

Около месяца свободного времени я уделил чтению исходного кода Quake II. Это был удивительный и поучительный опыт, потому что в движок idTech3 внесено большое изменение: Quake 1, Quake World и QuakeGL объединены в одну красивую архитектуру кода. Особенно был интересен способ, которым достигли модульности, несмотря на то, что язык программирования C не обеспечивает полиморфизма.
Quake II во многих отношениях является блестящим образцом программного обеспечения, потому что это был самый популярный (по количеству лицензий) трёхмерный движок всех времён. На его основе было создано более 30 игр. Кроме того, он ознаменовал переход игровой индустрии от программной/8-битной системы цветов к аппаратной/24-битной. Этот переход произошёл примерно в 1997 году.
Поэтому я крайне рекомендую всем, кто любит программирование, изучить этот движок. Как обычно, я вёл бесконечное количество заметок, затем подчистил их и опубликовал как статью, чтобы сэкономить вам несколько часов.
Процесс «подчистки» меня сильно увлёк: в статье теперь более 40 мегабайт видео, скриншотов и иллюстраций. Сейчас я не знаю, стоили ли мои труды того, и нужно ли публиковать в будущем необработанные заметки в ASCII, выскажите своё мнение.
Первая встреча и компиляция
Исходный код свободно доступен на ftp-сайте id Software. Проект можно открыть в Visual Studio Express 2008, который тоже можно свободно скачать с веб-сайта Microsoft.

Первая проблема заключается в том, что рабочая среда в Visual Studio 6 создаёт не один, а пять проектов. Так происходит потому, что Quake2 разрабатывался модульным (подробнее я расскажу об этом позже). Вот что получается из проектов:
| Проекты | Сборки |
| ctf | gamex86.dll |
| game | gamex86.dll |
| quake2 | quake.exe |
| ref_soft | ref_soft.dll |
| ref_gl | ref_gl.dll |
Примечание: проекты «ctf» и «game» перезаписывают друг друга, подробнее об этом позже.
Примечание 2: сначала сборку не удаётся выполнить из-за отсутствия заголовка DirectX:
fatal error C1083: Cannot open include file: 'dsound.h': No such file or directoryЯ установил Direct3D SDK и Microsoft SDK (для MFC), и всё нормально скомпилировалось.
Эрозия программного обеспечения: похоже, то, что случилось с базой кода Quake, начинает происходить и с Quake 2: невозможно открыть рабочую среду в Visual Studio 2010. Необходимо использовать VS 2008.
Примечание: если после компиляции возникает ошибка
"Couldn't fall back to software refresh!",
это значит, что не удалось правильно загрузить DLL рендерера. Но это легко исправить:
ядро Quake2 загружает две своих DLL с помощью win32 API: LoadLibrary. Если DLL не та, которая ожидается, или невозможно разрешить зависимости DLL, то сбой происходит без показа сообщения об ошибке. Поэтому:
- Подключите все пять проектов с одной библиотекой — нажмите правой кнопкой мыши на каждом проекте -> properties -> C/C++: убедитесь, что «runtime library» = Multi-threaded Debug DLL (с конфигурацией «Debug», иначе используйте release).
Если вы используете версию quake2, выпущенную id Software, то это устранит ошибку.
- Если вы используете мою версию: я добавил в движок возможность сохранения скриншотов в PNG, поэтому нужно также собрать libpng и libz (они находятся в подкаталоге). Убедитесь, что выбрана конфигурация Debug DLL. При сборке не забудьте поместить DLL libpng и zlib в одну папку с quake2.exe.
Архитектура Quake2
Когда я читал код Quake 1, разделил статью (её перевод находится здесь) на три части: «Сеть», «Прогнозирование» и «Визуализация». Такой подход был бы уместен и для Quake 2, потому что в основе своей движок не сильно отличается, но усовершенствования проще заметить, если разделить статью на три основных типа проектов:
| Тип проекта | Информация о проекте |
| Основной движок (.exe) | Ядро, выполняющее вызов модулей и обмен информацией между клиентом и сервером. В рабочей среде это проект quake2. |
| Модуль рендерера (.dll) | Отвечает за визуализацию. В рабочей среде содержатся программный рендерер (ref_soft) и рендерер OpenGL (ref_gl). |
| Игровой модуль (.dll) | Отвечает за игровой процесс (контент игры, оружие, поведение монстров...). В рабочей среде содержатся однопользовательский модуль (game) и модуль Capture The Flag (ctf). |
Quake2 имеет однопоточную архитектуру, точка входа находится в win32/sys_win.c. Метод WinMain выполняет следующие задачи:
game_export_t *ge; // Содержит указатели функций на dll игры
refexport_t re; // Содержит указатели функций на dll рендерера
WinMain() //Из quake2.exe
{
Qcommon_Init (argc, argv);
while(1)
{
Qcommon_Frame
{
SV_Frame() // Серверный код
{
//В сетевом режиме не используется в качестве сервера
if (!svs.initialized)
return;
// Переход в game.dll через указатель функции
ge->RunFrame();
}
CL_Frame() // Клиентский код
{
// Если только сервер ничего не рендерит
if (dedicated->value)
return;
// Переход к renderer.dll через указатель функции
re.BeginFrame();
//[...]
re.EndFrame();
}
}
}
}Полностью разобранный цикл можно найти в моих заметках.
Вы можете спросить: «зачем нужны такие изменения в архитектуре?». Для ответа на этот вопрос давайте посмотрим на все версии Quake с 1996 по 1997 год:
- Quake.
- WinQuake.
- GLQuake.
- VQuake. (несколько слов от одного из разработчиков Стефана Поделла (Stefan Podell) о сложностях V2200 в Z-буферинге (зеркало)).
- Quake World Server.
- Quake World Client.
Было создано множество исполняемых файлов, и каждый раз требовалось форкать или настраивать код через препроцессор . Это был полный хаос, и чтобы избавиться от него, нужно было:
- Унифицировать клиент/сервер.
- Собрать ядро, способное загружать взаимозаменяемые модули.
Новый подход можно проиллюстрировать таким образом:

Два основных улучшения:
- Клиент-серверная унификация: больше не было одного exe для клиента и другого для сервера, основной исполняемый файл мог работать как сервер, клиент или то и другое одновременно. Даже в однопользовательском режиме всё равно были клиент и сервер, выполнявшиеся в одном исполняемом файле (хотя в этом случае обмен данными выполнялся через локальный буфер, а не через TCP IP/IPX).
- Модульность: благодаря динамическому подключению часть кода стала взаимозаменяемой. Код рендерера и игры стал модулями, которые можно было переключать без изменения ядра Quake2. Таким образом с помощью двух структур, содержащих указатели функций, был достигнут полиморфизм.
Эти два изменения сделали базу кода чрезвычайно элегантной и более удобной для чтения, чем у Quake 1, который страдал от энтропии кода.
С точки зрения реализации проекты DLL должны раскрывать только один метод GetRefAPI для рендереров и GetGameAPI для игры (посмотрите на файл .def в папке «Resource Files»):
reg_gl/Resource Files/reg_soft.def
EXPORTS
GetGameAPI
Когда ядру нужно загрузить модуль, он загружает DLL в пространство процесса, получает адрес GetRefAPI с GetProcAddress, получает нужные указатели функций и на этом всё.
Интересный факт: при локальной игре связь между клиентом и сервером не выполняется через сокеты. Вместо этого команды скидываются в «кольцевой» (loopback) буфер с помощью NET_SendLoopPacket в клиентской части кода. Сервер реконструирует команду из того же буфера с помощью NET_GetLoopPacket.
Случайный факт: если вы видели когда-нибудь эту фотографию, то наверно интересовались, что за гигантский дисплей использовал Джон Кармак примерно в 1996 году:

Это был 28-дюймовый монитор InterView 28hd96, изготовленный Intergraph. Эта зверюга обеспечивала разрешение до 1920x1080, что довольно впечатляюще для 1995 года (подробнее можно почитать здесь (зеркало)).

Ностальгическое видео с Youtube: Рабочие станции Intergraph Computer Systems.
Дополнение: похоже, эта статья вдохновила кого-то на geek.com, потому что они написали статью «Джон Кармак создавал Quake в 1995 году на 28-дюймовом мониторе 16:9 1080p» (зеркало).
Дополнение: кажется, Джон Кармак всё ещё использовал этот монитор при разработке Doom 3.
Визуализация
Модули программного рендерера (ref_soft) и рендерера с аппаратным ускорением (ref_gl) были настолько большими, что я написал про них отдельные разделы.
И снова здесь примечательно то, что ядро даже не знало, какой рендерер подключен: оно просто вызывало указатель функции в структуре. То есть конвейер визуализации был полностью абстрагирован: и кому нужен этот C++?
Интересный факт: id Software по-прежнему использует систему координат из игры Wolfenstein 3D 1992 года (по крайней мере, так было в Doom3). Это важно знать при чтении исходного кода рендерера:
В системе id:
- Ось X = лево/право
- Ось Y = перед/зад
- Ось Z = верх/низ
В системе координат OpenGL:
- Ось X = лево/право
- Ось Y = верх/низ
- Ось Z = перед/зад
Поэтому в рендерере OpenGL используется матрица GL_MODELVIEW для «исправления» системы координат в каждом кадре с помощью метода R_SetupGL (glLoadIdentity + glRotatef).
Динамическое подключение
О взаимодействиях ядра/модуля можно сказать многое: я написал отдельный раздел о динамическом подключении.
Моддинг: gamex86.dll
Чтение этой части проекта оказалось не таким интересным, но отказ от Quake-C для скомпилированного модуля привёл к двум хорошим и одному очень плохому последствию.
Плохое:
- В жертву принесена портируемость, игровой модуль необходимо перекомпилировать под разные платформы с определёнными параметрами компоновщика.
Хорошее:
- Скорость: язык Quake-C игры Quake1 был интерпретируемым кодом, но модуль динамической библиотеки Quake2
gamex86.dllявляется нативным. - Свобода: моддеры получили доступ ко ВСЕМУ, а не только к тому, что было доступно через Quake-C.
Интересный факт: иронично, что id Software перешла в Quake3 обратно к использованию виртуальной машины (QVM) для игры, искусственного интеллекта и моддинга.
Мой quake2
В процессе хакинга я немного изменил исходный код Quake2. Крайне рекомендую добавить консоль DOS, чтобы видеть выводимые printf данные в процессе, а не ставить игру на паузу для изучения консоли Quake:
Добавить консоль в стиле DOS в окно Win32 довольно просто:
// sys_win.c
int WINAPI WinMain (HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
AllocConsole();
freopen("conin$","r",stdin);
freopen("conout$","w",stdout);
freopen("conout$","w",stderr);
consoleHandle = GetConsoleWindow();
MoveWindow(consoleHandle,1,1,680,480,1);
printf("[sys_win.c] Console initialized.n");
...
}Поскольку я запускал Windows на Mac с помощью Parallels, было сложно нажимать «printscreen» при выполнении игры. Для создания скриншотов я задал клавишу "*" с цифрового блока:
// keys.c
if (key == '*')
{
if (down) //Избегаем автоматического повтора!
Cmd_ExecuteString("screenshot");
}
И, наконец, я добавил множество комментариев и схем. Вот «мой» полный исходный код:
архив.
Управление памятью
У Doom и Quake1 был собственный диспетчер памяти под названием «Zone Memory Allocation»: при запуске выполнялась malloc и блок памяти управлялся с помощью списка указателей. Зону памяти (Memory Zone) можно было пометить для быстрой очистки нужной категории памяти. Zone Memory Allocator (common.c: Z_Malloc, Z_Free, Z_TagMalloc , Z_FreeTags) остался в Quake2, но он довольно бесполезен:
- Пометки не используются и распределение/освобождение памяти выполняется поверх
mallocиfree(понятия не имею, почему в id Software решили доверить эту работу C Standard Library). - Детектор переполнения (использующий константу
Z_MAGIC) тоже никогда не используется
По-прежнему очень полезно измерять потребление памяти благодаря атрибуту size в заголовке, вставляемому перед распределением каждого блока памяти:
#define Z_MAGIC 0x1d1d
typedef struct zhead_s
{
struct zhead_s *prev, *next;
short magic;
short tag; // для групповой очистки
int size;
} zhead_t;Система кэширования поверхностей имеет собственный диспетчер памяти. Объём распределённой памяти зависит от разрешения и определяется странной формулой, которая однако, очень эффективно защищает от мусора:
Первоначальная malloc кэширования поверхностей:
==============================
size = SURFCACHE_SIZE_AT_320X240; //1024*768
pix = vid.width*vid.height;
if (pix > 64000)
size += (pix-64000)*3;

«Hunk allocator» используется для загрузки ресурсов (изображений, звуков и текстур). Он довольно хорош, пытается использовать virtualAlloc и соотносить данные с размером страницы (8 КБ, несмотря на то, что в Win98 использовался 4 КБ?! Что за дела?!).
И, наконец, есть также множество стеков FIFO (среди прочего, для хранения интервалов), и несмотря на очевидно ограниченные возможности, они работают очень хорошо.
Управление памятью: трюк с упорядочиванием
Поскольку Quake2 управляет множеством обычных указателей, используется хороший трюк для размещения указателя в 32 битах (или размещения в 8 КБ для минимизации PAGE_FAULT… несмотря на то, что Windows 98 использовала страницы по 4 КБ).
Расположение страниц (в 8 КБ):
int roundUpToPageSize(int size)
{
size = (size + 8191) & ~8191;
return size;
}Расположение памяти (в 4 Б):
memLoc = (memLoc + 3) & ~3; // Располжоение в 4-байтном адресе.Подсистема консоли
Ядро Quake2 содержит мощную систему консоли, активно использующую списки указателей и линейный поиск.
В ней есть три типа объектов:
- Команды: дают указатель функции для заданного строкового значения.
- Cvar: хранят строковое значение для заданного имени строки.
- Псевдоним: предоставляет замену заданного строкового значения.
С точки зрения кода каждый тип объектов имеет список указателей:
cmd_function_t *cmd_functions // Список указателей, каждый элемент содержит имя строки и указатель функции: void (*)() .
cvar_t *cvar_vars // Список указателей, каждый элемент содержит имя строки и строковое значение.
cmdalias_t *cmd_alias // Список указателей, каждый элемент содержит имя строки и псевдоним строки.
При вводе каждой строки в консоль она сканируется, дополняется (с помощью псевдонимов и соответствующих cvar), а затем разбивается на токены, хранящиеся в двух глобальных переменных: cmd_argc и cmd_argv:
static int cmd_argc;
static char *cmd_argv[MAX_STRING_TOKENS];Пример:

Каждый идентифицированный в буфере токен копируется memcpy в место, указанное malloc записью cmd_argv. Процесс довольно неэффективный и показывает, что этой подсистеме уделили мало внимания. И это, кстати, полностью оправданно: она редко используется и мало влияет на игру, так что оптимизация не стоила усилий. Лучшим подходом был бы патчинг исходной строки на месте и запись значения указателя для каждого токена:

Поскольку токены находятся в массиве аргументов, то cmd_argv[0] проверяется очень медленным и линейным способом на соответствие всем функциям, объявленным в списке указателей функций. Если соответствие находится, то вызывается указатель функции.
Если соответствие не находится, то список указателей псевдонимов линейно проверяется для определения того, является ли токен вызовом функции. Если псевдоним заменяет вызов функции, то она вызывается.
И, наконец, если ничего из вышеперечисленного не срабатывает, то Quake2 обрабатывает токен как объявление переменной (или как её обновление, если переменная уже находится в списке указателей).
Здесь выполняется множество линейных поисков в списке указателей: идеальным выходом было бы использование таблицы хэшей. Она позволила бы достичь сложности O(n) вместо O(n²).
Интересный факт о парсинге 1: таблица ASCII организована умно: при парсинге строки для создания токенов можно пропустить разделители и символы пробела, просто проверяя, меньше ли ли символ i символа ' ' (пробела).
char* returnNextToken(char* string)
{
while (string && *string < ' ')
string++;
return string;
}Интересный факт о парсинге 2: таблица ASCII была организована очень умно: можно было преобразовать символ c в целое число следующим образом:
int value = c — '0';
int charToInt(char v)
{
return v - '0' ;
}Кэширование значения cvar:
Поскольку поиск места cvar в памяти (Cvar_Get) в этой системе имеет сложность O(n²) (линейный поиск + strcmp для каждой записи), рендереры кэшируют место cvar в памяти:
//Кэширование переменной
cvar_t *crosshair;
// На этапе инициализации движка, здесь создаётся
// и возвращается место Cvar в памяти.
crosshair = Cvar_Get ("crosshair", "0", CVAR_ARCHIVE); //ЭТО МЕЕЕДЛЕННО
//В рендерере, при выполнении программы.
void SCR_DrawCrosshair (void)
{
if (!crosshair->value) //ЭТО БЫСТРО
return;
}Доступ к этому значению затем можно получить за O(1).
Защита от злодеев
Для защиты от читерства было вставлено несколько механизмов:
- Даже несмотря на то, что у UDP есть собственная CRC, для защиты от модифицирования к каждому пакету добавляется Quake CRC (
COM_BlockSequenceCRCByte). - Перед началом детматча уровни хэшируются с помощью MD4. Этот хэш отправляется серверу, чтобы он убедился, что клиент не использует модифицированные карты (
Com_BlockChecksumM). - Есть даже система, проверяющая количество команд в секунду от каждого игрока (
SV_ClientThink), но я не знаю точно, насколько она была эффективна.
Внутренний ассемблер
Как и в каждой версии Quake, часть полезных функций была оптимизирована с помощью ассемблера (однако здесь ещё нет следов знаменитого «быстрого обратного квадратного корня», который присутствовал в Quake3).
Быстрое абсолютное значение 32-битного числа с плавающей запятой (большинство компиляторов сегодня делает это автоматически):
float Q_fabs (float f)
{
int tmp = * ( int * ) &f;
tmp &= 0x7FFFFFFF;
return * ( float * ) &tmp;
}Быстрое преобразование Float в Integer
__declspec( naked ) long Q_ftol( float f )
{
static int tmp;
__asm fld dword ptr [esp+4]
__asm fistp tmp
__asm mov eax, tmp
__asm ret
}Статистика кода
Анализ кода в Cloc показал, что всего в коде 138 240 строк. Как обычно, это число НЕ даёт представления о вложенных усилиях, потому что от многого отказались в итеративном цикле версий движка, но, как мне кажется, это хороший индикатор общей сложности движка.
$ cloc quake2-3.21/
338 text files.
319 unique files.
34 files ignored.
http://cloc.sourceforge.net v 1.53 T=3.0 s (96.0 files/s, 64515.7 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 181 24072 19652 107757
C/C++ Header 72 2493 2521 14825
Assembly 22 2235 2170 8331
Objective C 6 1029 606 4290
make 2 436 67 1739
HTML 1 3 0 1240
Bourne Shell 2 17 6 54
Teamcenter def 2 0 0 4
-------------------------------------------------------------------------------
SUM: 288 30285 25022 138240
-------------------------------------------------------------------------------Примечание: весь ассемблерный код предназначен для созданного вручную программного рендерера.
Инструменты, рекомендуемые для работы над хакингом Quake2
- Visual Studio Express 2008.
- Бесплатное демо Quake2 с веб-сайта id.
- Написанный мной Pak explorer.
- Wally: средство просмотра формата изображений WAL.
- Знаменитый инструмент исследования pak (PakExpl)
- Статья о формате BSP (зеркало) с сайта FlipCode.
- Профайлеры C: VTune(intel), CodeAnalysis(AMD), Visual Studio Team Profiler (лучший, по-моему).
- Большой 24/30-дюймовый экран.
- Клавиатура IBM Model M.
Quake2 состоит из одного ядра и двух модулей, загружаемых в процессе выполнения: Game и Renderer. Очень интересно, что благодаря полиморфизму к ядру можно подключить всё что угодно.
Прежде чем продолжать чтение, рекомендую убедиться, что вы хорошо понимаете принцип работы виртуальной памяти с помощью этой замечательной статьи (зеркало).
Полиморфизм в C с динамическим подключением
Динамическое подключение даёт множество преимуществ:
- Рендерер:
- Чистый код ядра Quake2, снижение энтропии кода, отсутствие повсюду безумных
. - Выпуск игры с несколькими рендерерами (программный, openGL).
- Рендерер можно менять при выполнении игры.
- Возможность создания нового рендерера для оборудования, созданного после выпуска игры (Glide, Verity).
- Чистый код ядра Quake2, снижение энтропии кода, отсутствие повсюду безумных
- Моддинг игры:
- Больше возможностей для авторов модов, игру можно полностью изменить через game.dll.
- Полная скорость игры в модах, нет необходимости полагаться на QuakeC и Quake Virtual Machine.
- Нет нужды изучать QuakeC, DLL были написаны на C.
Но Quake2 был написан на C, который не является объектно-ориентированным языком программирования, поэтому возник вопрос: «Как реализовать полиморфизм на языке, который не является ОО?»
Техника имитации ОО похожа на способ, применённый в JAVA и C++: использование структур, содержащих указатели функций.
Поэтому были использованы четыре структуры для обмена указателями функций: refimport_t и refexport_t действовали в качестве контейнера для обмена указателями функций при загрузке модуля рендерера. game_import_t и game_export_t использовались при загрузке модуля игры.
Небольшая иллюстрация лучше долгой речи
Шаг 1: на начальном этапе:
quake2.exeсодержит структуруref_OpenGL_tс указателями функций наNULL(серого цвета).- Модуль DLL (
ref_opengl.dll) также содержит структуруkernel_fct_tс указателями функций наNULL(серого цвета).
Задача процесса заключается в передаче адресов функций, чтобы каждая из частей могла вызывать другие.

Шаг 2: ядро, вызывающее функцию, заполняет структуру, содержащую указатели на её собственные функции, и отправляет эти значения DLL.

Шаг 3: принимающая DLL копирует указатели функций ядра и возвращает структуру, содержащую её собственные адреса функций.

Процесс с настоящими именами подробно описан в двух следующих разделах.
Библиотека рендерера
Метод, получающий модуль рендерера, называется VID_LoadRefresh. Он вызывается каждый кадр, чтобы Quake мог переключаться между рендерерами (но из-за необходимой рендереру предварительной обработки уровень нужно будет перезапустить).
Вот что происходит на стороне ядра Quake2:
refexport_t re;
qboolean VID_LoadRefresh( char *name )
{
refimport_t ri;
GetRefAPI_t GetRefAPI;
ri.Sys_Error = VID_Error;
ri.FS_LoadFile = FS_LoadFile;
ri.FS_FreeFile = FS_FreeFile;
ri.FS_Gamedir = FS_Gamedir;
ri.Cvar_Get = Cvar_Get;
ri.Cvar_Set = Cvar_Set;
ri.Vid_GetModeInfo = VID_GetModeInfo;
ri.Vid_MenuInit = VID_MenuInit;
ri.Vid_NewWindow = VID_NewWindow;
GetRefAPI = (void *) GetProcAddress( reflib_library, "GetRefAPI" );
re = GetRefAPI( ri );
...
}
В представленном выше коде ядро Quake2 получает указатель функции метода GetRefAPI от DLL рендерера с помощью GetProcAddress (встроенный метод win32).
Вот что происходит в GetRefAPI внутри DLL рендерера:
refexport_t GetRefAPI (refimport_t rimp )
{
refexport_t re;
ri = rimp;
re.api_version = API_VERSION;
re.BeginRegistration = R_BeginRegistration;
re.RegisterModel = R_RegisterModel;
re.RegisterSkin = R_RegisterSkin;
re.EndRegistration = R_EndRegistration;
re.RenderFrame = R_RenderFrame;
re.DrawPic = Draw_Pic;
re.DrawChar = Draw_Char;
re.Init = R_Init;
re.Shutdown = R_Shutdown;
re.BeginFrame = R_BeginFrame;
re.EndFrame = GLimp_EndFrame;
re.AppActivate = GLimp_AppActivate;
return re;
}В конце устанавливается двусторонний обмен данными между ядром и DLL. Он является полиморфным, потому что DLL рендерера возвращает внутри структуры свои собственные адреса функций и ядро Quake2 не видит разницы, оно всегда вызывает одинаковый указатель функции.
Библиотека игры
Точно такой же процесс выполняется с библиотекой игры на стороне ядра:
game_export_t *ge;
void SV_InitGameProgs (void)
{
game_import_t import;
import.linkentity = SV_LinkEdict;
import.unlinkentity = SV_UnlinkEdict;
import.BoxEdicts = SV_AreaEdicts;
import.trace = SV_Trace;
import.pointcontents = SV_PointContents;
import.setmodel = PF_setmodel;
import.inPVS = PF_inPVS;
import.inPHS = PF_inPHS;
import.Pmove = Pmove;
// Пропущено назначение 30 указателей функций
ge = (game_export_t *)Sys_GetGameAPI (&import);
ge->Init ();
}
void *Sys_GetGameAPI (void *parms)
{
void *(*GetGameAPI) (void *);
//[...]
GetGameAPI = (void *)GetProcAddress (game_library, "GetGameAPI");
if (!GetGameAPI)
{
Sys_UnloadGame ();
return NULL;
}
return GetGameAPI (parms);
}Вот что происходит на стороне DLL игры:
game_import_t gi;
game_export_t *GetGameAPI (game_import_t *import)
{
gi = *import;
globals.apiversion = GAME_API_VERSION;
globals.Init = InitGame;
globals.Shutdown = ShutdownGame;
globals.SpawnEntities = SpawnEntities;
globals.WriteGame = WriteGame;
globals.ReadGame = ReadGame;
globals.WriteLevel = WriteLevel;
globals.ReadLevel = ReadLevel;
globals.ClientThink = ClientThink;
globals.ClientConnect = ClientConnect;
globals.ClientDisconnect = ClientDisconnect;
globals.ClientBegin = ClientBegin;
globals.RunFrame = G_RunFrame;
globals.ServerCommand = ServerCommand;
globals.edict_size = sizeof(edict_t);
return &globals;
}Использование указателей функций
После передачи указателей методов включается полиморфизм. Здесь в коде ядро «перепрыгивает» к разным модулям:
Рендерер «перепрыгивает» к SCR_UpdateScreen:
// это метод quake.exe, рендерер абстрагирован, поэтому quake2.exe не знает, какой рендерер используется.
SCR_UpdateScreen()
{
// re - это struct refexport_t, BeginFrame указывает на BeginFrame в DLL.
re.BeginFrame( separation[i] );
// С этого момента методы принадлежат DLL
SCR_CalcVrect()
SCR_TileClear()
V_RenderView()
SCR_DrawStats
SCR_DrawNet
SCR_CheckDrawCenterString
SCR_DrawPause
SCR_DrawConsole
M_Draw
SCR_DrawLoading
re.EndFrame();
// Возврат к методам quake.exe.
}
Игра «перепрыгивает» к SV_RunGameFrame:
void SV_RunGameFrame (void)
{
sv.framenum++;
sv.time = sv.framenum*100; // не выполняется, если игра поставлена на паузу
if (!sv_paused->value || maxclients->value > 1)
ge->RunFrame ();
....
}
}Программный рендерер
Программный рендерер Quake2 — это самый большой, наиболее сложный, а потому самый интересный модуль для исследований.

Здесь нет никаких скрытых механизмов, начиная с диска и заканчивая пикселями.
Весь код написан аккуратно и оптимизирован вручную. Он — последний в своём роде и ознаменовал конец эры. Позже индустрия полностью перешла исключительно к рендерингу с аппаратным ускорением.
Фундаментальное отличие программного рендеринга и рендеринга OpenGL — использование системы 256-цветной палитры вместо привычной сегодня системы 24-битного True Color RGB:

Если сравнивать рендерер с аппаратным ускорением и программный рендерер, то заметим два наиболее очевидных различия:
- Отсутствие цветного освещения
- Отсутствие билинейной фильтрации
Но за исключением этого движку удавалось выполнять потрясающую работу с помощью очень умного использования палитры, о котором я расскажу позже:
- Быстрый выбор цветовых градиентов (64 значения).
- Полноэкранное смешивание цветов постэффектов.
- Попиксельная просвечиваемость.
Сначала загружается палитра Quake2 из архивного файла PAK pics/colormap.pcx:

Примечание: значение чёрного цвета равно 0, белого — 15, зелёного — 208, красного — 240 (в левом нижнем углу), прозрачного — 255.
Первым делом выполняется перестановка этих 256 цветов в соответствии с pics/colormap.pcx:

Такая схема 256x320 используется как таблица поиска, и это необыкновенно умно, потому что даёт множество интересных возможностей:
- 64 линий для имитации цветовых градиентов: первая линия создана из 256 цветов «развёрнутой» палитры. Остальные 63 значения в каждом столбце представляют в вертикальном виде градиент исходного цвета, имитированного остальными 255 цветами. Это позволяет создать очень простой и быстрый механизм выбора градиентов:
- Сначала выбирается цвет из палитры в диапазоне [0,255] (который получается из цветовой текстуры).
- Затем прибавляется x*256, где x находится в диапазоне [0,63] для получения затемнённой вариации выбранного изначально цвета (он берётся из текстуры карты освещения).
В результате получаем 64 оттенка 256 цветов. И всё это всего лишь из 256 цветов статичной палитры. Потрясающе.
- Оставшаяся часть изображения создаётся из квадратов 16x16, что позволяет использовать смешивание пикселей на основе палитры. Чётко видно, что все квадраты созданы из исходного цвета, конечного цвета и промежуточных цветов. Именно так в игре реализуется просвечиваемость воды. Например, в левом верхнем квадрате смешиваются чёрный и белый цвета.
Интересный факт: программный рендерер Quake2 изначально благодаря технологии MMX должен был быть основан на RGB, а не на палитре, о чём Джон Кармак заявил после выпуска Quake1 в этом видео (момент на 10 минуте 17 секунде):
MMX — это SIMD-технология, позволявшая работать со всеми тремя каналами RGB с затратой всего одного канала, обеспечивая таким образом смешивания с допустимым потреблением ресурсов ЦП. Я предполагаю, что от неё отказались по следующим причинам:
- Процессоры Pentium с поддержкой MMX были мало распространены в 1997 году, а программный рендерер предполагалось использовать на машинах с дешёвой конфигурацией.
- Передача цветов RGB (16 бит или 32 бит на пиксель) вместо цветов палитры (8 бит на пиксель) занимала слишком большую долю пропускной способности, и невозможно было достичь приемлемой частоты кадров.
Общая архитектура
Определившись с основным ограничением (палитрой), можно перейти к общей архитектуре рендерера. Его философия использовала сильные стороны Pentium (вычисления с плавающей точкой) для снижения влияния слабых сторон: скорости шины, влиявшей на запись пикселей в память. Бóльшая часть пути рендеринга сосредоточена на достижении нулевой перерисовки. В сущности, путь программного рендеринга аналогичен способу программного рендеринга Quake 1. В нём для обхода карты активно использовались BSP и PVS (набор потенциально видимых полигонов) для получения набора полигонов, которые нужно рендерить. Каждый кадр рендерятся три различных элемента:
- Карта: с помощью алгоритма связного построчного построения изображения на основе BSP (подробнее о нём позже).
- Сущности: либо как «спрайты» (окна), либо как «объекты» (игроки, враги) с помощью простого алгоритма построчного построения изображения.
- Частицы.
Примечание: если вы не знакомы с этими «старыми» алгоритмами, крайне рекомендую прочитать главы 3.6 и 15.6 книги Computer graphics: principles and practice Джеймса Д. Фоли (James D. Foley). Также можно найти множество информации в главах 59-70 книги Graphics programming black book Майкла Абраша (Michael Abrash).
Вот псевдокод высокого уровня:
- Рендеринг карты
- Проход по предварительно обработанному дереву BSP для определения кластера, в котором мы находимся.
- Запрос в базу данных PVS об этом конкретном кластере: получение и распаковка PVS.
- С помощью битового вектора PVS: помечаем как видимый каждый полигон, принадлежащий к кластеру, считающемуся потенциально видимым.
- Повторный проход по BSP. В этот раз проверяется, воздействует ли на видимый кластер какое-нибудь динамическое освещение. Если воздействует, то помечаем его идентификационным номером источника освещения.
- Теперь у нас есть список потенциально видимых полигонов с информацией об освещении:
- Снова используем BSP, проходим спереди назад:
- Проверяем на присутствие в пирамиде видимости и проецируем все полигоны на экран: строим глобальную таблицу рёбер.
- Рендеринг поверхности каждой грани (поверхность=текстура+карта освещения) для кэширования в ОЗУ.
- Вставка указателя поверхности в стек поверхностей (используется позже для связности).
- Генерирование с помощью стека поверхности и глобальной таблицы рёбер таблицы активных рёбер и построчный рендеринг экрана сверху вниз. Использование кэша поверхностей в ОЗУ в качестве текстуры. Запись интервалов в закадровый буфер и заполнение Z-буфера.
- Снова используем BSP, проходим спереди назад:
- Рендеринг сущностей, использование Z-буфера для определения видимых частей сущностей.
- Рендеринг просвечивающих текстур с помощью остроумного трюка с палитрой для попиксельного вычисления индексов палитры просвечивания.
- Рендеринг частиц.
- Добавление постэффектов (полноэкранное смешивание с красным цветов в случае снижения здоровья).
Визуализация экрана: индексы палитры записываются в закадровый буфер. В зависимости от режима (полноэкранный/оконный) используется DirectDraw или GDI. После завершения закадрового буфера кадров он передаётся в экранный буфер видеокарты (GDI=>rw_dib.c DirectDraw=>rw_ddraw.c) с помощью либо BitBlt WinGDI.h или BltFast ddraw.h.
DirectDraw или GDI
Те проблемы, с которыми программистам приходилось встречаться в 1997 году, просто удручали: Джон Кармак оставил в исходном коде забавный комментарий:
// может быть отрицательным для глупых DIBЕсли Quake2 работал в полноэкранном режиме с DirectDraw, он должен был отрисовывать закадровый буфер сверху вниз: так он и отображался на экране. Но когда он выполнялся в оконном режиме с GDI, то нужно было отрисовывать закадровый буфер в буфере DIB… отражённым по вертикали, потому что большинство драйверов производителей видеокарт передавало образ DIB из ОЗУ в видеопамять в отражённом режиме (стоит задаться вопросом, действительно ли «I» в аббревиатуре GDI обозначает «Independent»).
Поэтому переход по закадровому буферу кадров должен был стать абстрактным. Нужны были структура и значения, инициализируемые по-разному для абстрагирования от этих различий. Это примитивный способ реализации полиморфизма в C.
typedef struct
{
pixel_t *buffer; // Закадровый буфер кадров
pixel_t *colormap; // Палитра цветового градиента: размер 256 * VID_GRADES
pixel_t *alphamap; // Палитра просвечиваемости: карта просвечиваемости 256 * 256
int rowbytes; // может быть больше ширины, если отображается в окне
// может быть отрицательным для глупых DIB
int width;
int height;
} viddef_t;
viddef_t vid ;
В зависимости от способа, необходимого для отрисовки буфера кадров, vid.buffer инициализировался как первый пиксель:
- Первой строки для DirectDraw
- Последней строки для WinGDI/DBI
Для перехода вверх или вниз vid.rowbytes инициализировался как vid.width или как -vid.width.


Теперь для перехода не важно, как выполняется отрисовка: нормально или с вертикальным отражением:
// Первый пиксель первой строки
byte* pixel = vid.buffer + vid.rowbytes * 0;
// Первый пиксель последней строки
pixel = vid.buffer + vid.rowbytes * (vid.height-1);
// Первый пиксель строки i (нумерация строк начинается с 0)
pixel = vid.buffer + vid.rowbytes * i;
// Очистка буфера кадров заливкой чёрным цветом
memset(vid.buffer,0,vid.height*vid.height) ; // <-- Это работает в полноэкранном режиме DirectDraw
// но вызывает сбой в оконном режиме!Этот трюк позволяет конвейеру визуализации не беспокоиться о том, как выполняется передача на нижнем уровне, и я думаю, что это довольно примечательно.
Предварительная обработка карты
Прежде чем глубже закапываться в код, нужно понять две важные базы данных, генерируемых при предварительной обработке карты:
- Двоичное разбиение пространства (BSP)/ набор потенциально видимых полигонов (PVS).
- Текстура карты освещения на основе излучения.
Разрезание BSP, генерирование PVS
Рекомендую глубже изучить двоичное разбиение пространства:
- Wikipedia (на русском).
- Статья The Idea of BSP Trees Майкла Абраша.
- Статья Compiling BSP Trees Майкла Абраша.
- Статья в ASCII-стиле, старая библия.
Как и в Quake1, карты Quake2 проходят серьёзную предварительную обработку: их объём рекурсивно разрезается как на рисунке ниже:

В конце концов карта полностью разрезается на выпуклые 3D-пространства (называемые кластерами). Как и в Doom с Quake1, их можно использовать для сортировки всех полигонов спереди назад и сзади вперёд.
Отличное дополнение — это PVS, набор битовых векторов (по одному на кластер). Рассматривайте его как базу данных, к которой можно осуществлять запросы и получать кластеры, потенциально видимые из любого кластера. Эта база данных огромна (5 МБ), но эффективно сжата до нескольких сотен килобайт и хорошо умещается в ОЗУ.
Примечание: для сжатия PVS используется компрессия, пропускающая только значения 0x00, этот процесс объяснён ниже.
Излучение
Как и в Quake1, влияние освещения уровня рассчитывается предварительно и хранится в текстурах, которые называются картами освещения. Однако в отличие от Quake1 Quake2 использует в предварительных расчётах излучение и цветное освещение. Карты освещения затем сохраняются в архиве PAK и используются в процессе выполнения игры:
Пара слов от одного из создателей: Майкл Абраш в «Black Book of Programming» (глава «Quake: a post-mortem and a glimpse into the future»):
Самые интересные изменения графики заключались в предварительных расчётах, куда Джон добавил поддержку излучаемого света...
Обработка уровней Quake 2 занимала до часа времени.
(Однако стоит заметить, что в него входило создание BSP, расчёт PVS и излучаемого света, который я рассмотрю позже.)
Если вы хотите узнать об излучаемом освещении, то прочитайте эту потрясающе хорошо иллюстрированную статью (зеркало): это просто шедевр.
Вот первый уровень с наложенной текстурой излучения: к сожалению, потрясающие цвета RGB необходимо было ресемплировать для программного рендерера в градации серого (подробнее об этом позже).

Низкое разрешение карты освещения здесь бросается в глаза, но поскольку она проходит билинейную фильтрацию (да, даже в программном рендерере), то конечный результат, соединённый с цветовой текстурой, очень хорош.
Интересный факт: карты освещения могут иметь любой размер от 2x2 до 17x17 (несмотря на заявленный максимальный размер 16 в статье flipcode (зеркало)) и не обязаны быть квадратными.
Архитектура кода
Бóльшая часть кода программного рендерера находится в методе R_RenderFrame. Вот его краткое описание, более подробный анализ читайте в моих предварительных заметках.
R_SetupFrame: получает текущую точку обзора обходом BSP (вызовMod_PointInLeaf), сохраняет clusterID точки обзора вr_viewcluster.R_MarkLeaves: для текущего кластера обзора (r_viewcluster) получает и разархивирует PVS. Использует PVS, чтобы пометить видимые грани.R_PushDlights: снова использует BSP для обхода граней спереди назад. Если грань помечена как видимая, проверяет, воздействует ли на неё освещение.R_EdgeDrawing: визуализация уровня.R_RenderWorld: обход BSP спереди назад- Проецирование всех видимых полигонов в экранное пространство: построение глобальной таблицы рёбер.
- Отправка показателя каждой видимой поверхности в стек поверхностей (это выполняется для связности).
R_ScanEdges: рендеринг уровня строки за строкой, сверху вниз. Для каждой строки:R_InsertNewEdges: использование глобальной таблицы рёбер для инициализации таблицы активных рёбер, использование её в качестве набора событий.(*pdrawfunc)(): генерирование интервалов, но они не записываются в закадровый буфер. Вместо этого интервалы записываются в буфер стека интервалов. Причина будет объяснена ниже.D_DrawSurfaces: если буфер стека интервалов заполнен, рендеринг всех интервалов в закадровый буфер и очистка стека интервалов.
R_DrawEntitiesOnList: рендеринг сущностей, не являющихся BModel (BModel — это элемент уровня). Рендеринг спрайтов и моделей объектов (игроков, врагов, боеприпасов)...R_DrawAlphaSurfaces: использование остроумного трюка для выполнения попиксельного смешиванияR_CalcPalette: расчёт постэффектов, например, смешивания цветов (при получении урона, собирании предметов и т.п.)
R_RenderFrame
{
R_SetupFrame // Установка указателя функции pdrawfunc в зависимости от того, для чего делается рендеринг: GDI или DirectDraw
{
Mod_PointInLeaf // Определение того, что находится в текущем кластере обзора (обходом BSP-дерева) и сохранение этой информации в r_viewcluster
}
R_MarkLeaves // Получение и разархивация для текущего кластера обзора (r_viewcluster)
// набора PVS
R_PushDlights // Пометка полигонов, на которые воздействует освещение, для каждого dlight_t* прошедшего через r_newrefdef.dlights.
// Построение глобальной таблицы граней и их рендеринг через таблицу активных граней
R_EdgeDrawing // Рендеринг уровня
{
R_BeginEdgeFrame // Установка указателя функции pdrawfunc, используемого позже в этой функции
R_RenderWorld // Построение глобальной таблицы граней
// Также заполнение стека поверхностей и подсчёт количества поверхностей для рендеринга (surf_max - это максимальное значение)
R_DrawBEntitiesOnList// Понятия не имею, что делает этот фрагмент.
R_ScanEdges // Использование глобальной таблицы граней для сохранения таблицы активных граней: отрисовка мира как растровых строк
// Запись в Z-буфер (но не чтение)
{
for (iv=r_refdef.vrect.y ; iv<bottom ; iv++)
{
R_InsertNewEdges // Обновление AET событием GET
(*pdrawfunc)(); // Генерирование интервалов
D_DrawSurfaces // Отрисовка поверхностей на экране
}
// Очистка буфера интервалов
R_InsertNewEdges // Обновление AET событием GET
(*pdrawfunc)(); // Генерирование интервалов
D_DrawSurfaces // Отрисовка поверхностей на экране
}
}
R_DrawEntitiesOnList // Отрисовка врагов, бочек и т.д...
// Использование Z-буфера только в режиме чтения.
R_DrawParticles // Частицы!
R_DrawAlphaSurfaces // Выполнение смешивания пикселей палитры в нижней части таблицы поиска <code>pics/colormap.pcx</code>.
R_SetLightLevel // Сохранение значение освещения для поиска сервером (БОЛЬШОЙ ХАК!)
R_CalcPalette // Изменение палитры (при потере здоровья или собирании предметов), для изменения всех цветов
}R_SetupFrame: управление BSP
Обход дерева двоичного разбиения пространства выполняется повсюду в коде. Это мощный механизм со стабильной скоростью, позволяющий сортировать полигоны спереди назад или сзади вперёд. Чтобы его понять, нужно разобраться со структурой cplane_t:
typedef struct cplane_s
{
vec3_t normal;
float dist;
} cplane_t;Для вычисления расстояния или точки от секущей плоскости в узле нужно просто вставить её координаты в уравнение плоскости:
int d = DotProduct (p,plane->normal) - plane->dist;
Благодаря знаку d мы узнаём, находимся ли мы перед или за плоскостью, и можем выполнить сортировку. Этот процесс использовался в движках начиная с Doom и заканчивая Quake3.
R_MarkLeaves: групповая разархивация PVS
То, как я понимал разархивацию PVS в моём анализе исходного кода Quake 1, было полностью неправильным: кодируется не расстояние между битами 1, а только количество записываемых байтов 0x00. В PVS выполняется только групповое сжатие 0x00: при считывании сжатого потока:
- Если из сжатого PVS считывается ненулевой байт, то он записывается в разархивированную версию.
- Если из сжатого PVS считывается байт 0x00, то следующий байт показывает, какое количество байтов нужно пропустить.
В первом случае ничего не сжимается. Групповое сжатие выполняется только во втором случае:
byte *Mod_DecompressVis (byte *in, model_t *model)
{
static byte decompressed[MAX_MAP_LEAFS/8]; // Лист = 1 бит, поэтому всего 65536 / 8 = 8 192 байт
// нужно для хранения полностью разархивированного PVS.
int c;
byte *out;
int row;
row = (model->vis->numclusters+7)>>3;
out = decompressed;
do
{
if (*in) // Это ненулевой байт, записываем его в том же виде и продолжаем и переходим к следующему сжатому байту.
{
*out++ = *in++;
continue;
}
c = in[1]; // Мы не "продолжили", поэтому это нулевой байт: считываем следующий байт (in[1]) и записываем
in += 2; // соответствующее количество байтов в разархивированный PVS.
while (c)
{
*out++ = 0;
c--;
}
} while (out - decompressed < row);
return decompressed;
}Можно пропустить до 255 байт (255*8 листьев), при необходимости после них нужно снова добавить ноль с числом, которое нужно пропустить у следующих 255 байт. То есть пропуск 511 байт (511*8 листьев) занимает 4 байта: 0 — 255 — 0 — 255
Пример:
// Пример системы с 80 листьями, представленная в 10 байтах: видимый=1, невидимый=0
Двоичный разархивированный PVS
0000 0000 0000 0000 0000 0000 0000 0000 0011 1100 1011 1111 0000 0000 0000 0000 0000 0000 0000 0000
Десятичный разархивированный PVS
0x00 0x00 0x00 0x00 0x39 0xBF 0x00 0x00 0x00 0x00
// !! СЖАТИЕ!!
Двоичный сжатый PVS
0000 0000 0000 1000 0011 1100 1011 1111 0000 0000 0000 1000
Десятичный сжатый PVS
0x00 0x04 0x39 0xBF 0x00 0x04После разархивирования PVS текущего кластера, каждая отдельная грань, принадлежащая кластеру, считающемуся в PVS видимым, тоже помечается как видимая:
В: как проверить видимость кластера с заданным идентификатором i с помощью разархивированной PVS?
О: битовым И между байтом i/8 PVS и 1 << (i % 8)
char isVisible(byte* pvs, int i)
{
// i>>3 = i/8
// i&7 = i%8
return pvs[i>>3] & (1<<(i&7))
}
Точно как и в Quake1, здесь есть хороший трюк, используемый для пометки полигона как видимого: вместо использования флагов и сброса каждого из них в начале каждого кадра применяется int. При начале каждого кадра счётчик кадров r_visframecount увеличивается на единицу в R_MarkLeaves. После разархивировании PVS все зоны помечаются как видимые присвоением полю visframe текущего значения r_visframecount.
Позже в коде видимость узла/кластера всегда проверяется следующим способом:
if (node->visframe == r_visframecount)
{
// Узел видимый
}R_PushDlights: динамическое освещение
Для каждого идентификатора lightID источника активного динамического освещения выполняется рекурсивный обход BSP начиная с положения источника освещения. Вычисляется расстояние между источником и кластером, и если интенсивность освещения больше, чем расстояние от кластера, то все поверхности в кластере помечаются как подверженные воздействию этого идентификатора источника.
Примечание: поверхности помечаются с помощью двух полей:
dlightframe— это флагint, используемый так же, как в случае пометки видимости кластеров (вместо сброса всех флагов в каждом кадре увеличивается глобальная переменнаяr_dlightframecount. Чтобы свет воздействовал,r_dlightframecountдолжен быть равенsurf.dlightframe.dlightbits— это битовый векторint, используемый для хранения индексов различных массивов источников освещения, воздействующих на данную грань.
R_EdgeDrawing: визуализация уровня
R_EdgeDrawing — это монстр программного рендерера, наиболее сложный для понимания. Чтобы разобраться с ним, нужно посмотреть на основную структуру данных:
Стек surf_t (действующий в качестве прокси m_surface_t) размещается в стеке ЦП.

//Система стека поверхностей
surf_t *surfaces ; // Массив стека поверхностей
surf_t *surface_p ; // Вершина стека поверхностей
surf_t *surf_max ; // Верхний предел стека поверхностей
// поверхности генерируются bsp-деревом в порядке "сзади вперёд", поэтому если указатель
// больше другого, то должен отрисовываться перед
// surfaces[1] как фон, и используется как стек активных поверхностей
Note: первый элемент surfaces - это пустая поверхность
Note: второй элемент в surfaces - это фоновая поверхностьЭтот стек заполняется при обходе BSP спереди назад. Каждый видимый полигон вставляется в стек как прокси поверхности. Позже, при обходе таблицы активных рёбер для генерирования строки экрана он позволяет очень быстро увидеть, какой полигон находится перед всеми остальными простым сравнением адреса в памяти (чем ниже в стеке, тем ближе к точке обзора). Именно так реализуется «связность» для алгоритма преобразования построчного построения изображения.
Примечание: каждый элемент стека также имеет список указателей (называемый цепочкой текстур), указывающий на элементы в стеке буфера интервалов (рассмотренном ниже). Интервалы хранятся в буфере и отрисовываются из цепочке текстур для потекстурной группировки интервалов и максимизации буфера предварительного кэширования ЦП.
Стек инициализируется в самом начале R_EdgeDrawing:
void R_EdgeDrawing (void)
{
// Общий размер: 64 КБ
surf_t lsurfs[NUMSTACKSURFACES +((CACHE_SIZE - 1) / sizeof(surf_t)) + 1];
surfaces = (surf_t *) (((long)&lsurfs[0] + CACHE_SIZE - 1) & ~(CACHE_SIZE - 1));
surf_max = &surfaces[r_cnumsurfs];
// поверхность 0 на самом деле не существует; она пуста, потому что индекс 0
// используется для того, чтобы показать, что к поверхности не присоединены рёбра
surfaces--;
R_SurfacePatch ();
R_BeginEdgeFrame (); // surface_p = &surfaces[2];
// фон - это поверхность 1,
// поверхность 0 - это пустышка
R_RenderWorld
{
R_RenderFace
}
R_DrawBEntitiesOnList
R_ScanEdges // Запись Z-буфера (но без чтения)
{
for (iv=r_refdef.vrect.y ; iv<bottom ; iv++)
{
R_InsertNewEdges // Обновление AET событием GET
(*pdrawfunc)(); // Генерирование интервалов
D_DrawSurfaces // Отрисовка поверхностей на экране
}
// Очистка буфера интервалов
R_InsertNewEdges // Обновление AET событием GET
(*pdrawfunc)(); // Генерирование интервалов
D_DrawSurfaces // Отрисовка поверхностей на экране
}
}Вот подробности:
R_BeginEdgeFrame: очистка глобальной таблицы рёбер с последнего кадра.R_RenderWorld: обход BSP (учтите, что он НЕ рендерит ничего на экране):- Каждая поверхность, считающаяся видимой, добавляется в стек с прокси
surf_t. - Проецирование вершин всех полигонов в экранное пространство и заполнение глобальной таблицы рёбер.
- Также генерирование значения 1/Z для всех вершин, чтобы можно было сгенерировать Z-буфер с интервалами.
- Каждая поверхность, считающаяся видимой, добавляется в стек с прокси
R_DrawBEntitiesOnList: понятия не имею, что делает этот фрагмент.R_ScanEdges: комбинирование всей полученной на данный момент информации для рендеринга уровня:- Инициализация таблицы активных рёбер.
- Инициализация буфера интервалов (также является стеком):

// Система стека интервалов espan_t *span_p; // Текущая вершина указателя стека интервалов espan_t *max_span_p; // Макс. span_p за этим, переполнение стека // Примечание: стек интервалов (basespans) размещается в стеке ЦП void R_ScanEdges (void) { int iv, bottom; byte basespans[MAXSPANS*sizeof(espan_t)+CACHE_SIZE]; ... } - Запуск алгоритма построчного построения изображений сверху вниз по экрану.
- Для каждой строки:
- Обновление таблицы активных рёбер из глобальной таблицы рёбер.
- Запуск таблицы активных рёбер для всей строки:
- Определение видимого полигона с помощью адреса в стеке поверхностей.
- Передача интервала в буфер интервалов.
- Если буфер интервалов заполнен: отрисовка всех интервалов и сброс стека интервалов.
- Проверка оставшегося в буфере интервалов. Если в нём что-то осталось: отрисовка всех интервалов и сброс стека интервалов.
Видео работы R_EdgeDrawing
В видео ниже движок работает с разрешением 1024x768. Также он замедлен с помощью специальной cvar sw_drawflat 1, что позволило рендерить полигоны без текстур, но разными цветами:
В этом видео можно заметить очень много интересного:
- Экран генерируется сверху вниз, это типичный алгоритм построчного построения изображений.
- Горизонтальный интервал пикселей не записывается так, как генерировался. Это выполняется для оптимизации кэша упреждающей выборки Pentium: интервалы группируются по textureId с помощью механизма, называемого «цепочками текстур». Интервалы сохраняются в буфер. Когда буфер заполнен, интервалы отрисовываются с цепочками текстур ОДНОЙ группой.
- Момент заполнения буфера интервалов и запуска процесса рендеринга очевиден, потому что рендеринг полигонов останавливается примерно на пятидесятой строке пикселей.
- Интервалы генерируются сверху вниз, но отрисовываются снизу вверх: поскольку интервалы вставляются в цепочку текстур наверху списка указателей, они отрисовываются в порядке обратном их созданию.
- Последняя группа занимает 40% экрана, а первая занимала 10%. Так происходит потому, что здесь гораздо меньше полигонов, интервалы не обрезаны и они занимают гораздо большее пространство.
- OMG, нулевая перерисовка на этапе визуализации сплошного мира.
Предварительно вычисляемое излучение: карты освещения
К сожалению, красивые 24-битные карты освещения в RGB необходимо ресэмплировать в 6-битные градации серого (выбором самого яркого канала из R, G и B), чтобы уложиться в ограничения палитры:
Что хранится в архиве PAK (24 бита):

После загрузки с диска и ресэмплинга до 6-бит:

А потом всё вместе: текстура грани даёт цвет в диапазоне [0,255]. Это значение индексирует цвет в палитре из pics/colormap.pcx:

Карты освещения фильтруются: в результате мы получаем значение в диапазоне [0,63].

Теперь с помощью верхней части pics/colormap.pcx движок может выбрать нужную позицию палитры. Для получения окончательного результата он использует входное значение текстуры в качестве координаты X и освещённость*63 как координату Y:

И вуаля:

Лично я считаю, что это потрясающе: имитация 64 градиентов 256 цветов… всего 256 цветами!
Подсистема поверхностей
Из предыдущих скриншотов очевидно, что генерирование поверхностей — наиболее требовательная к ЦП часть Quake2 (это подтверждается результатами профайлера ниже). Приемлемое относительно скорости и потребления памяти генерирование поверхностей обеспечивают два механизма:
- MIP-текстурирование (mipmapping)
- Кэширование
Подсистема поверхностей: MIP-текстурирование
При проецировании полигона в экранное пространство генерируется 1/Z его расстояния. Ближайшая вершина используется для определения того, какой нужно использовать уровень MIP-текстур. Вот пример карты освещения и того, как она фильтруется в соответствии с уровнем MIP-текстур:


Вот минипроект, над которым я работал для тестирования качества билинейной фильтрации Quake2 на случайных изображениях: архив.
Ниже представлены результаты теста, выполненного для карты освещения размером 13x15 текселов:

Уровень 3 MIP-текстур: блок имеет размер 2x2 тексела.

Уровень 2 MIP-текстур: блок имеет размер 4x4 тексела.

Уровень 1 MIP-текстур: блок имеет размер 8x8 текселов.

Уровень 0 MIP-текстур: блок имеет размер 16x16 текселов.
Ключ к пониманию фильтрации заключается в том, то всё основано на размере полигонов в пространстве мира (ширина и высота называются extent):
- Препроцессор Quake2 убеждается, что размеры полигона (X или Y) меньше или равны 256, а также кратны 16.
- Из размеров полигона в пространстве мира мы можем вывести:
- Размер карты освещения (в текселах): LmpDim = PolyDim / 16 + 1
- Размер поверхности (в блоках): SurDim = LmpDim -1 = PolyDim / 16
На рисунке ниже размеры полигона (3,4), карты освещения — (4,5) текселов, а вырожденная поверхность всегда имеет размер (3,4) блока. Уровни MIP-текстур определяют размеры блока в текселах, а значит и общий размер поверхности в текселах.

Всё это выполняется в R_DrawSurface. Уровень MIP-текстур выбирается с помощью массива указателей функций (surfmiptable), выбирающего нужную функцию растеризации:
static void (*surfmiptable[4])(void) = {
R_DrawSurfaceBlock8_mip0,
R_DrawSurfaceBlock8_mip1,
R_DrawSurfaceBlock8_mip2,
R_DrawSurfaceBlock8_mip3
};
R_DrawSurface
{
pblockdrawer = surfmiptable[r_drawsurf.surfmip];
for (u=0 ; u<r_numhblocks; u++)
(*pblockdrawer)();
}В изменённом движке ниже можно увидеть три уровня MIP-текстур: 0 — серого цвета, 1 — жёлтого и 2 — красного:

Фильтрация выполняется блоком при генерировании block[i][j] поверхности, фильтр использует значения карты освещения: lightmap[i][j],lightmap[i+1][j],lightmap[i][j+1] и lightmap[i+1][j+1]: в сущности, с помощью четырёх текселов непосредственно в координатах и трёх внизу и справа. Заметьте, что это выполняется не весовой интерполяцией, а скорее линейной интерполяцией, сначала вертикально, а затем горизонтально по сгенерированным значениям. Если вкратце, то это работает в точности так же, как в статье Wikipedia о билинейной фильтрации.
А теперь всё вместе:

Исходная карта освещения, 13x15 текселов.

Фильтрация, уровень 0 MIP-текстур (16x16 блоков)=192x224 тексела.
Результат:

Подсистема поверхностей: кэширование
Даже несмотря на то, что движок активно использует для управления памятью malloc и free, он всё равно использует собственный диспетчер памяти для кэширования поверхностей. Блок памяти инициализируется сразу после того, как становится известно разрешение визуализации:
size = SURFCACHE_SIZE_AT_320X240;
pix = vid.width*vid.height;
if (pix > 64000)
size += (pix-64000)*3;
size = (size + 8191) & ~8191;
sc_base = (surfcache_t *)malloc(size);
sc_rover = sc_base;
Ровер sc_rover в самом начале располагается в блоке, чтобы отслеживать, что было занято. Когда ровер достигает конца памяти, он сворачивается, в сущности, заменяя старые поверхности. Объём зарезервированной памяти можно увидеть на графике:

Вот как новый фрагмент памяти выделяется из блока:
memLoc = (int)&((surfcache_t *)0)->data[size]; // Пропуск размера + обеспечение достаточного места для заголовка фрагмента памяти.
memLoc = (memLoc + 3) & ~3; // FCS: округление до числа, кратного 4
sc_rover = (surfcache_t *)( (byte *)new + size);Примечание: трюк с быстрым назначением кэша (может перейти в систему памяти)
Примечание: заголовок размещается поверх запрошенного объёма памяти. Очень странная строка, использующая указатель NULL (((surfcache_t *)0)) (но с ней всё в порядке, потому что нет задержки).
Перспективное проецирование для бедных?
В разных статьях в Интернете предполагается, что Quake2 использует «перспективное проецирование для бедных» с помощью простой формулы и без гомогенных координат или матриц (код ниже из R_ClipAndDrawPoly):
XscreenSpace = X / Z * XScale
YscreenSpace = Y / Z * YScaleГде XScale и YScale определяются по области обзора и соотношению сторон экрана.
Такое перспективное проецирование на самом деле аналогично тому, что происходит в OpenGL на этапе деления GL_PROJECTION + W:
Перспективное проецирование:
=======================
Вектор координат глаза
| X
| Y
| Z
| 1
--------------------------------------------------
Матрица перспективного проецирования |
|
XScale 0 0 0 | XClip
0 YScale 0 0 | YClip
0 0 V1 V2 | ZClip
0 0 -1 0 | WClip
Координаты обрезки:
================ XClip = X * XScale
YClip = Y * YScale
ZClip = /
WClip = -Z
Координаты NDC с делением W:
=========
XNDC = XClip/WClip = X * XScale / -Z
YNDC = YClip/WClip = Y * YScale / -ZПервое наивное доказательство: сравните наложенные скриншоты. Если мы посмотрим в код: проецирование для бедных? Нет!
R_DrawEntitiesOnList: спрайты и объекты
На этом этапе процесса визуализации уровень уже отрендерен на экране:

Движок также сгенерировал 16-битный z-буфер (он был записан, но ещё не считывался):

Примечание: мы видим, что чем ближе значения, тем они «ярче» (в противоположность OpenGL, где ближе — это «темнее»). Так происходит потому, что в Z-буфере вместо Z хранится 1/Z.
16-битный z-буфер хранится начиная с указателя d_pzbuffer:
short *d_pzbuffer;Как сказано выше, 1/Z сохраняется с помощью прямого применения формулы, описанной в статье Майкла Абраша «Consider the Alternatives: Quake's Hidden-Surface Removal».
Она находится в D_DrawZSpans:
zi = d_ziorigin + dv*d_zistepv + du*d_zistepu;Если вам интересно математическое доказательство того, что можно действительно интерполировать 1/Z, то вот статья Кок-Лим Ло (Kok-Lim Low): PDF.
Z-буфер, выведенный на этапе визуализации уровня, теперь используется в качестве входных данных для правильной обрезки сущностей.
Немного об анимированных сущностях (игроках и врагах):
- Quake1 отрисовывал только ключевые кадры, но теперь все вершины подвергаются LERP (
R_AliasSetUpLerpData) для плавной анимации. - Quake1 для рендеринга рассматривал сущности как BLOB: это неточный, но очень быстрый способ визуализации. В Quake2 от этого отказались и сущности рендерятся нормально, после тестирования BoundingBox и тестирования передних граней векторным произведением.
В отношении освещения:
- Не все тени отрисовываются.
- Полигоны имеют затенение по Гуро с жёстко заданным направлением освещения (
{-1, 0, 0}отR_AliasSetupLighting). - Интенсивность освещения основана на интенсивности источника освещения поверхности, на который она направлена.

Просвечиваемость в R_DrawAlphaSurfaces
Просвечиваемость должна выполняться с помощью индексов палитры. Наверно, я уже десятый раз повторяю это в статье, но только так я могу выразить, насколько это мне кажется потрясающим.
Просвечивающий полигон рендерится следующим образом:
- Проецирование всех вершин в экранное простраство.
- Определение левого и правого ребра.
- Если поверхность не искажается (анимированная вода), то выполняется визуализация в систему кэширования в ОЗУ.
После этого, если поверхность не полностью непрозрачная, то её нужно смешать с закадровым буфером кадров.
Трюк выполняется с помощью второй части изображения pics/colormap.pcx, использованного как таблица поиска для смешивания исходного пикселя из кэша поверхностей с целевым пикселем (в закадровом буфере кадров):
Исходные входные данные генерируют координату X, а целевые — координату Y. Полученный пиксель загружается в закадровый буфер кадров:

В анимации ниже показан кадр до и после попиксельного смешивания палитры:

R_CalcPalette: операции постэффектов и гамма-коррекция
Движок способен выполнять не только «попиксельное смешивание палитры» и «выбор цветового градиента на основе палитры», он может также изменять целую палитру для передачи информации о снижении здоровья или собирании предметов:

Если «анализатору» в DLL игры на стороне сервера необходимо было смешать цвета в конце процесса визуализации, ему нужно было просто задать значение переменной RGBA float player_state_t.blend[4] для любого игрока в игре. Это значение передаётся по сети, копируется в refdef.blend[4], а затем передаётся DLL рендерера (ну и путешествие!). При обнаружении оно смешивается с каждыми 256 элементами RGB в индексе палитры. После гамма-коррекции палитра снова загружается в видеокарту.
R_CalcPalette в r_main.c:
// newcolor = color * alpha + blend * (1 - alpha)
alpha = r_newrefdef.blend[3];
premult[0] = r_newrefdef.blend[0]*alpha*255;
premult[1] = r_newrefdef.blend[1]*alpha*255;
premult[2] = r_newrefdef.blend[2]*alpha*255;
one_minus_alpha = (1.0 - alpha);
in = (byte *)d_8to24table;
out = palette[0];
for (i=0 ; i<256 ; i++, in+=4, out+=4)
for (j=0 ; j<3 ; j++)
v = premult[j] + one_minus_alpha * in[j];
Интересный факт: после изменения палитры вышеуказанным способом для неё необходимо выполнить гамма-коррекцию (в R_GammaCorrectAndSetPalette):

Гамма-коррекция — это ресурсоёмкая операция, включающая в себя вызов pow и деление… к тому же, её нужно было выполнять для каждого из каналов R, G и B значения цвета!
int newValue = 255 * pow ( (value+0.5)/255.5 , gammaFactor ) + 0.5;
Всего получается три вызова pow, три операции деления, шесть операций суммирования и три умножения для каждого из 256 значений в индексе палитры — это очень много.
Но поскольку входные данные ограничены восемью битами на канал, полную коррекцию можно рассчитать заранее и кэширования в небольшой массив из 256 элементов:
void Draw_BuildGammaTable (void)
{
int i, inf;
float g;
g = vid_gamma->value;
if (g == 1.0)
{
for (i=0 ; i<256 ; i++)
sw_state.gammatable[i] = i;
return;
}
for (i=0 ; i<256 ; i++)
{
inf = 255 * pow ( (i+0.5)/255.5 , g ) + 0.5;
if (inf < 0)
inf = 0;
if (inf > 255)
inf = 255;
sw_state.gammatable[i] = inf;
}
}
Поэтому для этого трюка используется таблица поиска (sw_state.gammatable) и она сильно ускоряет процесс гамма-коррекции.
void R_GammaCorrectAndSetPalette( const unsigned char *palette )
{
int i;
for ( i = 0; i < 256; i++ )
{
sw_state.currentpalette[i*4+0] = sw_state.gammatable[palette[i*4+0]];
sw_state.currentpalette[i*4+1] = sw_state.gammatable[palette[i*4+1]];
sw_state.currentpalette[i*4+2] = sw_state.gammatable[palette[i*4+2]];
}
SWimp_SetPalette( sw_state.currentpalette );
}Примечание: вы можете решить, что у ЖК-экранов нет таких проблем с гаммой, как у ЭЛТ… однако они обычно имитируют поведение ЭЛТ-экранов!
Статистика кода
Немного анализа кода Cloc, чтобы закрыть тему программного рендерера: в этом модуле насчитывается 14 874 строк. Это немного больше 10% от общего количества, но не даёт представления о вложенных усилиях, потому что перед выбором этой схемы было протестировано несколько других.
$ cloc ref_soft/
39 text files.
38 unique files.
4 files ignored.
http://cloc.sourceforge.net v 1.53 T=0.5 s (68.0 files/s, 44420.0 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 17 2459 2341 8976
Assembly 9 1020 880 3849
C/C++ Header 7 343 293 2047
Teamcenter def 1 0 0 2
-------------------------------------------------------------------------------
SUM: 34 3822 3514 14874
-------------------------------------------------------------------------------
Ассемблерная оптимизация в девяти файлах r_*.asm содержит 25% объёма всей базы кода, и это довольно впечатляющее соотношение. Думаю, оно достаточно наглядно показывает объём труда, вложенного в программный рендерер: бóльшая часть процедуры растеризации оптимизирована вручную для процессора x86 Майклом Абрашем. Бóльшая часть оптимизации под Pentium, рассмотренных в его книге «Graphics Programming Black Book», используется в этих файлах.
Интересный факт: некоторые названия методов в книге и в коде Quake2 совпадают (например, ScanEdges).
Профайлинг

Я пробовал использовать разные профайлеры, все они интегрированы в Visual Studio 2008:
- AMD Code Analysis
- Intel VTune Amplifier XE 2011
- Visual Studio Team Profiler
Привязка к сэмплированию времени показала очень разные результаты. Например, Vtune учитывал затраты на передачу из ОЗУ в видеопамять (BitBlit), но другие профайлеры упустили их.
Профайлерами Intel и AMD не удалось проверить оборудование (и я не настолько мазохист, чтобы выяснять, почему так получилось), но профайлер VS 2008 Team справился… хотя я и не рекомендую его: игра работала с частотой три кадра в секунду, и на анализ 20-секундной игры потребовался целый час!
Профайлинг VS 2008 Team edition:

Результаты говорят сами за себя:
- Затраты на программный рендеринг ошеломляют: 89% времени тратится в DLL.
- Игровая логика едва заметна: 0%.
- На удивление много времени занимает звуковая DLL DirectX.
- В
libcтратится больше времени, чем в ядре quake.exe.

Взглянем повнимательней на траты времени ref_soft.dll:
- Как я упомянул выше, запись байта в память очень затратна:
- Огромные затраты (33%) связаны с построением Z-буфера (
D_DrawZSpans). - Огромные затраты (22%) связаны с записью интервалов в закадровый буфер (
D_DrawZSpans16). - Огромные затраты (13%) связаны с генерированием поверхности пропуска кэша.
- Огромные затраты (33%) связаны с построением Z-буфера (
- Затраты на алгоритм построчного построения изображения очевидны:
R_LeadingEdgeR_GenerateSpansR_TrailingEdge
Профайлинг Intel VTune:

Заметно следующее:
- 18% времени посвящено стандартной проблеме программных рендереров: затраты на перенос отрендеренного изображения из ОЗУ в видеопамять (
BitBlit). - 34% времени посвящено визуализации и кэшированию поверхностей (
D_DrawSurfaces). - 8% посвящено LERP вершин для анимации игроков/врагов (
R_AliasPreparePoints).
А вот более подробный профайлинг ref_sof Quake2 с помощью VTune.
Профайлинг AMD Code Analysis
Фильтрация текстур
Я получил много вопросов о том, как можно улучшить фильтрацию текстур (перейти к билинейной фильтрации или дизерингу похожему на используемый в Unreal (зеркало)). Если вы хотите поэкспериментировать с этим аспектом, то изучите D_DrawSpans16 в ref_soft/r_scan.c:
Начальные координаты (X,Y) экранного пространства находятся в pspan->u and pspan->v, также имеется ширина интервала в spancount для расчёта того, какой будет сгенерирован целевой экранный пиксель.
Что касается координат текстур: s и t инициализиуются в исходных координатах текстуры и увеличиваются на (соответственно) sstep и tstep для управления сэмплированием текстур.
У некоторых, например, у «Szilard Biro», получились неплохие результаты при использовании техники дизеринга Unreal I:

Исходный код программного рендерера с дизерингом можно найти в моём форке Quake2 на github. Дизеринг активируется присвоением cvar sw_texfilt значения 1.
Исходный дизеринг из программного рендерера Unreal 1:

Рендерер OpenGL

Quake2 стал первым движком, выпущенным с нативной поддержкой рендеринга с аппаратным ускорением. Он демонстрировал несомненные улучшения благодаря билинейной фильтрации текстур, увеличению мультитекстурирования и 24-битному смешиванию цвета.

С точки зрения пользователя версия с аппаратным ускорением обеспечивала следующие улучшения:
- Билинейная фильтрация
- Цветное освещение
- Повышение частоты кадров на 30% в высоких разрешениях
Не могу удержаться от цитаты из «Masters of Doom» о том, как Джон Ромеро впервые увидел цветное освещение [прим. пер.: до начала работы над Quake 2 он уже покинул id Software и создал собственную компанию Ion Storm]:
Затем Ромеро подошёл к стенду id [...].
Он пробился сквозь толпу, чтобы посмотреть на демо Quake II. Его лицо стало жёлтым, а челюсть отвисла: цветное освещение! Ромеро не мог поверить в то, что он видит. На экране был похожий на подземелье военный уровень, но когда игрок стрелял из оружия, жёлтый луч выстрела отбрасывал такой же жёлтый свет на стены. Он был слабым, но Ромеро видел динамическое цветное освещение. В тот момент он ощутил те же чувства, которые испытал в Softdisk, когда впервые увидел Dangerous Dave in Copyright Infringement [прим. пер.: созданное Кармаком в 1990 году демо первого платформера на PC с скроллингом экрана].
«Твою мать», — пробормотал он. Кармаку снова удалось удивить его.
Эта особенность оказала сильное влияние на разработку Daikatana.
С точки зрения кода рендерер на 50% меньше, чем программный рендерер (см. «Статистику кода» в конце страницы). Это значило, что разработчикам требовалось меньше работы. Также такая реализация была гораздо проще и элегантнее, чем программная/оптимизированная на ассемблере версия:
- Z-буфер позволил избавиться от стека активных полигонов (такая зависимость от быстрого Z-буфера привела к проблемам при разработке VQuake для V2200
- Высокая скорость чипов растеризатора в сочетании со скоростью ОЗУ Z-буфера сделали ненужной задачу нулевой перерисовки.
- Встроенная процедура построчного построения изображения избавила от необходимости глобальной таблицы рёбер и таблицы активных рёбер.
- Фильтрация карт освещения выполнялась в видеопроцессоре (и в RGB вместо градаций серого): в ЦП эти вычисления вообще не попадали.
В конце концов, рендерер OpenGL больше является диспетчером ресурсов, чем рендерером: он передаёт вершины, на лету загружает атлас карт освещения и назначает состояния текстур.
Интересный факт: кадр Quake2 обычно содержит по 600-900 полигонов: разительное отличие от миллионов полигонов в любом современном движке.
Глобальная архитектура кода
Фаза рендеринга очень проста и я не буду подробно её рассматривать, потому что она практически идентична программному рендерингу:
R_RenderView
{
R_PushDlights // Пометка полигона, на который воздействует динамическое освещение
R_SetupFrame
R_SetFrustum
R_SetupGL // Настройка GL_MODELVIEW и GL_PROJECTION
R_MarkLeaves // Разархивирование PVS и пометка потенциально видимых полигонов
R_DrawWorld // Рендеринг уровня, отсечение целых кластеров полигонов тестированием BoundingBox
{
}
R_DrawEntitiesOnList // Рендеринг сущностей
R_RenderDlights // Смешивание динамического освещения
R_DrawParticles // Отрисовка частиц
R_DrawAlphaSurfaces // Просвечивающие поверхности с смешиванием альфа-канала
R_Flash // Постэффекты (добавление красного цвета на весь экран при потере здоровья и т.п...)
}Все этапы наглядно показаны в видео, в котором движок «замедлен»:
Порядок визуализации:
- Мир.
- Сущности (в Quake2 они называются «alias»).
- Частицы.
- Просвечивающие поверхности.
- Полноэкранные постэффекты.
Основная сложность кода возникает из-за разных путей в зависимости от того, поддерживает ли видеокарта мультитекстурирование и включён ли групповой рендеринг вершин. Например, если мультитекстурирование поддерживается, то DrawTextureChains и R_BlendLightmaps в следующем куске кода ничего не делают и только запутывают при чтении кода:
R_DrawWorld
{
//Отрисовка мира, выполняется на 100% при поддержке мультитекстурирования или только ПЕРВЫЙ проход (цвета) без мультитекстурирования
R_RecursiveWorldNode // Сохранение граней цепочкой текстур, чтобы избежать изменения назначенных текстур
{
// Рендеринг всех PVS с отсечением кластеров с помощью BBox/пирамиды видимости
// Здесь выполняется основное!
// Если видимо: рендеринг
GL_RenderLightmappedPoly
{
if ( is_dynamic )
{
}
else
{
}
}
}
// Только если не поддерживается мультитекстутирование (ВТОРОЙ проход)
DrawTextureChains // Отрисовка всех цепочек текстур, это позволяет избежать слишком большого числа вызовов bindTexture.
{
for ( i = 0, image=gltextures ; i<numgltextures ; i++,image++)
for ( ; s ; s=s->texturechain)
R_RenderBrushPoly (s)
{
}
}
// Только если не поддерживается мультитекстурирование (ВТОРОЙ проход: карты освещения)
R_BlendLightmaps
{
// Рендеринг статичных карт освещения
// Загрузка и рендеринг динамических карт освещения
if ( gl_dynamic->value )
{
LM_InitBlock
GL_Bind
for ( surf = gl_lms.lightmap_surfaces[0]; surf != 0; surf = surf->lightmapchain )
{
// Проверка заполненности блока. Если он заполнен, загрузить блок и отрисовать, в противном случае продолжать заполнять его
}
}
}
R_DrawSkyBox
R_DrawTriangleOutlines
}Визуализация мира
Рендеринг уровня выполняется в R_DrawWorld. Вершина имеет пять атрибутов:
- Положение.
- Идентификатор цветовой текстуры.
- Координаты цветовой текстуры.
- Идентификатор текстуры статичной карты освещения.
- Координаты текстуры статичной карты освещения.
В рендерере OpenGL нет «Surface»: цвета и карта освещения сочетаются на лету и никогда не кэшируются. Если видеокарта поддерживает мультитекстурирование, то необходим только один проход, указывающий идентификатор текстуры и её координаты:
- Цветовая текстура привязывается к состоянию OpenGL GL_TEXTURE0.
- Текстура карты освещения привязывается к состоянию OpenGL GL_TEXTURE1.
- Передаются вершины с координатами цветовой текстуры и текстуры карты освещения.
Если видеокарта НЕ поддерживает мультитекстурирование, то выполняется два прохода:
- Смешивание отключается.
- Цветовая текстура привязывается к состоянию OpenGL GL_TEXTURE0.
- Вершины отправляются с координатами цветовой текстуры.
- Смешивание включается.
- Текстура карты освещения привязывается к состоянию OpenGL GL_TEXTURE0.
- Передаются вершины с координатами текстуры карты освещения.
Управление текстурами
Поскольку вся растеризация выполняется в видеопроцессоре, в начале уровня все текстуры должны загружаться в видеопамять:
- Цветовые текстуры
- Предварительно рассчитанные текстуры карт освещения
С помощью отладчика OpenGL gDEBugger можно с лёгкостью покопаться в памяти видеопроцессора и получить статистику:

Как мы видим, у каждой цветовой текстуры есть собственный идентификатор текстуры (textureID). Статичные карты освещения загружаются как атлас текстур (называемый в quake2 «блоком») в таком виде:

Почему же цветовая текстура находится в отдельной текстуре, если карты освещения собраны в атлас текстур?
Причина заключается в оптимизации цепочек текстур:
Если вы хотите увеличить производительность при работе с видеопроцессором, то нужно стремиться к том, чтобы он менял своё состояние как можно реже. Это особенно справедливо для привязки текстур (glBindTexture). Вот плохой пример:
for(i=0 ; i < polys.num ; i++)
{
glBindTexture(polys[i].textureColorID , GL_TEXTURE0);
glBindTexture(polys[i].textureLightMapID , GL_TEXTURE1);
RenderPoly(polys[i].vertices);
}Если каждый полигон имеет цветовую текстуру и текстуру карты освещения, то тут мало что можно сделать, но Quake2 собирает свои карты освещения в атласы, которые легко сгруппировать по идентификатору. Поэтому полигоны не рендерятся в порядке, возвращаемом из BSP. Вместо этого они группируются в цепочки текстур на основании того, к какому атласу текстур карт освещения они относятся:
glBindTexture(polys[textureChain[0]].textureLightMapID , GL_TEXTURE1);
for(i=0 ; i < textureChain.num ; i++)
{
glBindTexture(polys[textureChain[i]].textureColorID , GL_TEXTURE0);
RenderPoly(polys[textureChain[i]].vertices);
}В видео ниже показан процесс визуализации «цепочек текстур»: полигоны рендерятся не в зависимости от расстояния, а на основании блока карт освещения, к которым они относятся:
Примечание: для достижения постоянной просвечиваемости в цепочку текстур попадают только полностью непрозрачные полигоны, а просвечиваемые полигоны по-прежнему рендерятся сзади вперёд.
Динамическое освещение
В самом начале фазы визуализации все полигоны помечаются, чтобы показать, что они подвержены влиянию динамического освещения (R_PushDlights). Поэтому предварительно рассчитанная статичная карта освещения не используется. Вместо неё генерируется новая карта освещения, сочетающая в себе статичную карту освещения с добавлением света, проецируемого на плоскость полигона (R_BuildLightMap).
Поскольку карта освещения имеет максимальный размер 17x17, фаза генерирования карты динамического освещения не слишком затратна, но загрузка изменений в видеопроцессор с помощью qglTexSubImage2D очень медленная.
Для хранения всех динамических карт освещения используется блок карт освещения размером 128x128, его id=1024. См. в разделе «Управление картами освещения» объяснение того, как все динамические карты освещения комбинируются на лету в атлас текстур.

1. Первоначальное состояние блока динамического освещения. 2. После первого кадра. 3. Через десять кадров.
Примечание: если динамическая карта освещения заполнена, выполняется групповой рендеринг. Ровер отслеживает, выполнена ли очистка выделенного места, и генерирование динамических карт освещения возобновляется.
Управление картами освещения
Как я сказал ранее, в OpenGL-версии рендерера нет концепции «поверхности» («surface»). Карта освещения и цветовая текстура комбинируются на лету и НЕ кэшируются.
Хота статичные карты освещения загружаются в видеопамять, они всё равно хранятся в ОЗУ: если на полигон воздействует динамическое освещение, генерируется новая карта освещения, сочетающая в себе статичную карту освещения со спроецированным на неё светом. Динамическая карта освещения затем загружается в textureId=1024 и используется для текстурирования.
Атласы текстур называются в Quake2 «блоками» («Block»), состоят из 128x128 текселов и управляются тремя функциями:
LM_InitBlock: сброс отслеживания потребления памяти блоком.LM_UploadBlock: загрузка или обновление содержимого текстуры.LM_AllocBlock: поиск подходящего места для хранения карты освещения.
В видео ниже показано, как карты освещения соединяются в блоки. Здесь движок играет в «Тетрис»: сканирует слева направо и запоминает, куда карта освещения поместится полностью в самой верхней координате изображения.
Алгоритму стоит уделить внимание: ровер (int gl_lms.allocated[BLOCK_WIDTH]) отслеживает по всей ширине, какую высоту занял каждый столбец пикселей.
// Переменную "best" лучше было бы назвать "bestHeight"
// Переменную "best2" НУЖНО было бы назвать "tentativeHeight"
static qboolean LM_AllocBlock (int w, int h, int *x, int *y)
{
int i, j;
int best, best2;
//FCS: на этой высоте сохраняется новая карта освещения
best = BLOCK_HEIGHT;
for (i=0 ; i<BLOCK_WIDTH-w ; i++)
{
best2 = 0;
for (j=0 ; j<w ; j++)
{
if (gl_lms.allocated[i+j] >= best)
break;
if (gl_lms.allocated[i+j] > best2)
best2 = gl_lms.allocated[i+j];
}
if (j == w)
{ // это нужное место
*x = i;
*y = best = best2;
}
}
if (best + h > BLOCK_HEIGHT)
return false;
for (i=0 ; i<w ; i++)
gl_lms.allocated[*x + i] = best + h;
return true;
}Примечание: шаблон проектирования «ровер» («rover») очень элегантен и используется также в системе памяти кэширования поверхностей программного рендерера.
Скорость заполнения пикселями и проходы рендеринга
Как видно из следующего видео, перерисовка может быть довольно значительной:
В худшем случае пиксель может перезаписываться 3-4 раза (не считая перерисовки):
- Мир: 1-2 прохода (в зависимости от поддержки мультитекстурирования).
- Смешивание частиц: 1 проход.
- Смешивание постэффектов: 1 проход.
GL_LINEAR
Билинейная фильтрация хорошо работала с цветовыми текстурами, но по-настоящему расцвела при фильтрации карт освещения:
Было:

Стало:

А теперь всё вместе:

1. Текстура: динамическая/статическая карта освещения.

2. Текстура: цвет.

3. Результат смешивания: один или два прохода.

Визуализация сущностей
Сущности рендерятся группами: вершины, координаты текстур и указатели массивов цветов собираются и отправляются с помощью glArrayElement.
Перед визуализацией для вершин всех сущностей выполняется LERP для сглаживания анимации (в Quake1 использовались только ключевые кадры).
Используется модель освещения Гуро: массив цветов перехватывается Quake2 для хранения значения освещения. Перед визуализацией для каждой вершины выполняется расчёт значения освещения и сохраняется в массив цветов. Значение этого массива интерполируется в видеопроцессоре и получается хороший результат с освещением по Гуро.
R_DrawEntitiesOnList
{
if (!r_drawentities->value)
return;
// Непрозрачные сущности
for (i=0 ; i < r_newrefdef.num_entities ; i++)
{
R_DrawAliasModel
{
R_LightPoint /// Определение цвета освещения для применения к модели целиком
GL_Bind(skin->texnum); // Привязка текстуры сущности
GL_DrawAliasFrameLerp() // Отрисовка
{
GL_LerpVerts // Интерполяция LERP всех вершин
// Расчёт освещения для каждой вершины, сохранение в массиве цветов colorArray
for ( i = 0; i < paliashdr->num_xyz; i++ )
{
}
qglLockArraysEXT
qglArrayElement // ОТРИСОВКА!
qglUnlockArraysEXT
}
}
}
// Сущности с прозрачностью
for (i=0 ; i < r_newrefdef.num_entities ; i++)
{
R_DrawAliasModel
{
[...]
}
}
}Отсечение задних граней выполняется в видеопроцессоре (ну, поскольку тесселяция и освещение выполнялись в то время в ЦП, думаю, можно сказать, что оно выполнялось на этапе драйвера).
Примечание: для ускорения расчётов направление света всегда принималось одинаковым ({-1, 0, 0} ), но это не отражено в движке. Цвет освещения точен и подбирается по текущему полигону, на котором основана сущность.
Это очень хорошо заметно на скриншоте ниже, где свет и тень имеют одно направление, несмотря на неправильное определение источника света.

Примечание: конечно, эта система не всегда идеальна, тень выдаётся в пустоту, а грани перезаписывают друг друга, приводя к разным уровням теней, но это всё равно довольно впечатляюще для 1997 года.
Подробнее о тенях:
Многим неизвестно, что Quake2 был способен вычислять приблизительные тени сущностей. Хотя по умолчанию эта функция отключена, её можно включить командой gl_shadows 1.
Тень всегда направлена в одну сторону (не зависит от ближайшего источника света), грани проецируются на плоскость уровня сущности. В коде R_DrawAliasModel генерирует вектор shadevector, используемый GL_DrawAliasShadow для проецирования граней на плоскость уровня сущности.
Освещение визуализации сущностей: трюк с дискретизацией
Вы можете решить, что малое количество полигонов в модели позволяло вычислять нормальное и скалярное произведение нормалей/света в реальном времени… но нет. Все скалярные произведения вычисляются заранее и хранятся в float r_avertexnormal_dots[SHADEDOT_QUANT][256], где SHADEDOT_QUANT=16.
Используется дискретизация: направление света всегда одинаково: {-1,0,0}.
Вычисляется всего одна из 16 различных нормалей, в зависимости от ориентации модели по оси Y.
После выбора одного из 16 направлений предварительно вычисляется скалярное произведение для 256 разных нормалей. Нормаль в формате модели MD2 — это ВСЕГДА индекс заранее вычисленного массива. Любое сочетание нормалей X,Y,Z попадает в одно из 256 направлений.
Из-за всех этих ограничений все скалярные произведения ищутся в r_avertexnormal_dots размером 16x256. Поскольку индекс нормали нельзя интерполировать в процессе анимации, для ключевого кадра используется ближайший индекс нормали.
Подробнее об этом: http://www.quake-1.com/docs/quakesrc.org/97.html (зеркало).
Старый добрый OpenGL...
Где моя glGenTextures?!:
Сегодня openGL-разработчики запрашивают textureID из видеопроцессора через glGenTextures. Quake2 не утруждался этим и выбирал идентификатор самостоятельно. Поэтому цветовые текстуры начинались с 0, текстура динамической карты освещения всегда имела идентификатор 1024, а статичная карта освещения с 1025 по 1036.
Печально известный режим Immediate mode:
Данные вершины передаются в видеокарту с помощью ImmediateMode. По два вызова функции на вершину (glVertex3fv и glTexCoord2f) для рендеринга мира (поскольку полигоны отсекались индивидуально, невозможно было собрать их в группы).
Групповая визуализация выполнялась для моделей (врагов, игроков) с помощью glEnableClientState (GL_VERTEX_ARRAY). Вершины, передаваемые в glVertexPointer и glColorPointer, использовались для передачи значения освещения, вычисляемого в ЦП.
Мультитекстурирование:
Код усложнён тем, что стремится подстроиться к оборудованию поддерживающему и не поддерживающему новую технологию… мультитекстурирования.
Нет использования GL_LIGHTING:
Поскольку все вычисления выполнялись в ЦП (генерирование текстур для мира и значение освещённости вершин для сущностей), в коде нет следов GL_LIGHTING.
Поскольку OpenGL 1.0 всё равно выполнял затенение по Гуро (интерполируя цвета между вершинами) вместо затенения по Фонгу (где нормали интерполируются для реального «попиксельного освещения»), то использование GL_LIGHTING плохо бы выглядело для мира, потому что требовало бы создания вершин на лету.
Его «можно» было применить для сущностей, но при этом пришлось бы отправлять и векторы нормалей вершин. Похоже, это сочли неподходящим, поэтому вычисление значений освещения выполняется в ЦП. Значение освещения передаётся из массива цветов, значения интерполируются в ЦП для получения затенения по Гуро.
Полноэкранные постэффекты
Программный рендерер на основе палитры выполнял элегантное полное смешивание цветов палитры и дополнительную гамма-коррекцию с помощью таблицы поиска. Но OpenGL-версии это не нужно, и в этом можно убедиться на примере метода «грубой силы» в R_Flash:
Проблема: нужно сделать экран немного более красным?
Решение: просто отрисуем на весь экран огромный красный прямоугольник GL_QUAD со включенным смешиванием альфа-канала. Готово.
Примечание: сервер управлял клиентом так же, как программный рендерер: если серверу нужно было выполнить полноэкранное смешивание цветов для постэффекта, он просто присваивал значение переменной float player_state_t.blend[4] RGBA. Значение переменной затем передавалось благодаря ядру quake2 по сети и отправлялось в DLL рендерера.
Профайлинг
Профайлер Visual Studio 2008 Team просто чудесен, вот что выяснилось для OpenGL Quake2:

Ничего удивительного: бóльшая часть времени тратится на OpenGL-драйвер NVidia и Win32 (nvoglv32.dll и opengl32.dll), всего около 30%. Визуализация выполняется в видеопроцессоре, но куча времени тратится на множественный вызов методов immediate mode, а также на копирование данных из ОЗУ в видеопамять.
Следующими идут модуль рендерера (ref_gl.dll 23%) и ядро quake2 (quake2.exe 15%).
Даже несмотря на то, что движок активно использует malloc, мы видим, что на него почти не тратится времени (MSVCR90D.dll и msvcrt.dll). Также несущественно время, потраченное на игровую логику (gamex86.dll).
Неожиданное количество времени тратится на звуковую библиотеку directX (dsound.dll): 12% от общего времени.
Рассмотрим подробнее dll рендерера OpenGL Quake2:

- Бóльшая часть времени тратится на рендеринг мира (
R_RecurseiveWorldNode). - Почти столько же — на рендеринг врагов (моделей alias): (
GL_DrawAliasFrameLerp2,5%). Затраты довольно высоки, несмотря на то, что скалярное произведение вычисляется заранее. - Генерирование карт освещения (когда динамическое освещение не даёт использовать заранее вычисленную статичную карту освещения) тоже занимает 2,5% времени (
GL_RenderLightMappedPoly).
В целом dll OpenGL хорошо сбалансирована, в ней НЕТ очевидных «бутылочных горлышек».
Статистика кода
Анализ кода Cloc показывает, что всего насчитывается 7 265 строк кода.
$ cloc ref_gl
17 text files.
17 unique files.
1 file ignored.
http://cloc.sourceforge.net v 1.53 T=1.0 s (16.0 files/s, 10602.0 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 9 1522 1403 6201
C/C++ Header 6 237 175 1062
Teamcenter def 1 0 0 2
-------------------------------------------------------------------------------
SUM: 16 1759 1578 7265
-------------------------------------------------------------------------------По сравнению с программным рендерером разница поразительна: на 50% меньше кода, БЕЗ ассемблерной оптимизации, при этом скорость на 30% выше и присутствует цветное освещение и билинейная фильтрация. Легко понять, почему id Software не стала возиться с программным рендерером для Quake3.
Автор: PatientZero






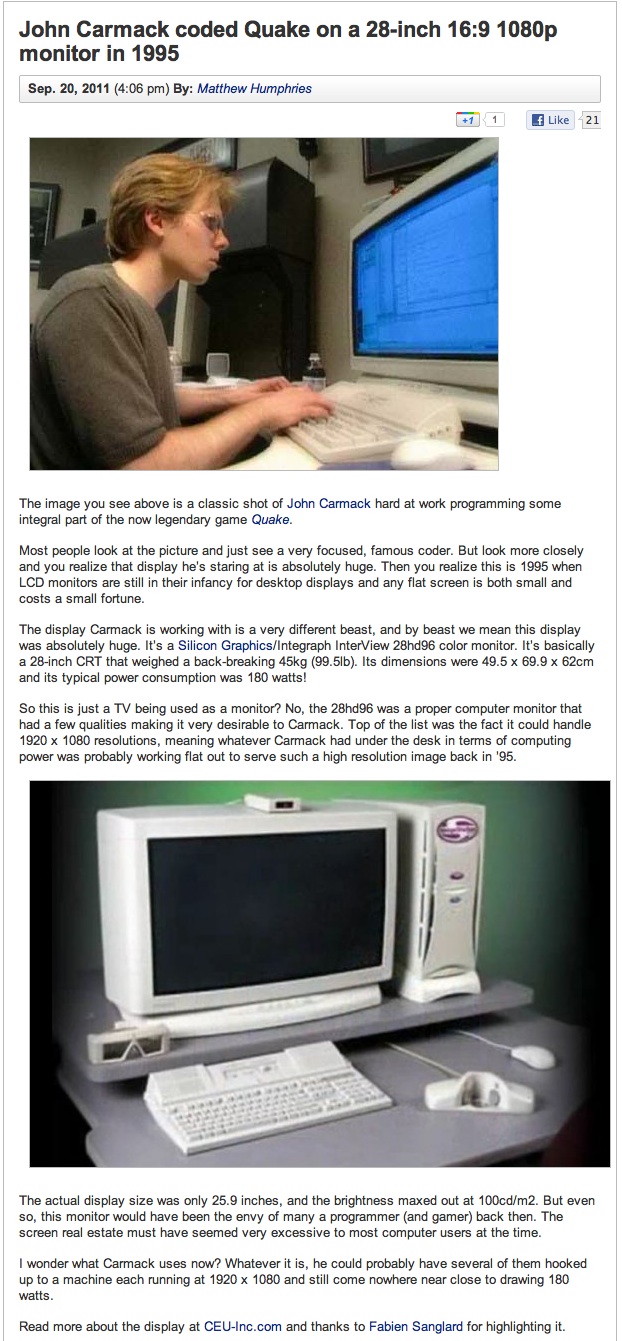{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}