

Введение
(Ссылки на исходный код и проект KiCAD приведены в конце статьи.)
Хотя мы родились в 8-битную эпоху, нашим первым компьютером был Amiga 500. Это великолепная 16-битная машина, обладавшая потрясающими графикой и звуком, благодаря чему она отлично подходила для игр. Очень популярным игровым жанром на этом компьютере стали платформеры. Многие из них были очень цветастыми и обладали очень плавным параллаксным скроллингом. Это стало возможно благодаря талантливым программистам, гениально использовавшим сопроцессоры Amiga для увеличения количества экранных цветов. Взгляните, например на LionHeart!

Lionheart на Amiga. Это статичное изображение не передаёт всю красоту графики.
С 90-х электроника сильно поменялась, и теперь есть множество маленьких микроконтроллеров, позволяющих создавать удивительные вещи.
Мы всегда любили платформенные игры, а сегодня всего за несколько долларов можно купить Raspberry Zero, установить Linux и «довольно легко» написать красочный платформер.
Но это задача не по нам — мы не хотим палить из пушки по воробьям!
Мы хотим использовать микроконтроллеры с ограниченной памятью, а не мощную систему на чипе со встроенным GPU! Другими словами, мы хотим трудностей!
Кстати, о возможностях видео: некоторым людям удаётся в своих проектах выжать все соки из микроконтроллера AVR (например, в проекте Uzebox или Craft разработчика lft). Однако чтобы достичь этого, микроконтроллеры AVR вынуждают нас писать на ассемблере, и даже несмотря на то, что некоторые игры очень хороши, вы столкнётесь с серьёзными ограничениями, не позволяющими создать игру в 16-битном стиле.
Поэтому мы решили использовать более сбалансированный микроконтроллер/плату, позволяющий писать код полностью на C.
Он не такой мощный, как Arduino Due, но и не такой слабый, как Arduino Uno. Любопытно, что «Due» означает «два», а «Uno» — «один». Microsoft научила нас считать правильно (1, 2, 3, 95, 98, ME, 2000, XP, Vista, 7, 8, 10), и Arduino тоже пошла по этому пути! Мы будем использовать Arduino Zero, который находится посередине между 1 и 2!
Ага, по мнению Arduino, 1 < 0 < 2.
В частности, нас интересует не сама плата, а её серия процессоров. В Arduino Zero установлен микроконтроллер серии ATSAMD21 с Cortex M0+ (48 МГц), 256 КБ флеш-памяти и 32 КБ ОЗУ.
И хотя 48-мегагерцовый Cortex M0+ сильно обгоняет по производительности старый 7-мегагерцовый MC68000, у Amiga 500 были 512 КБ ОЗУ, аппаратные спрайты, встроенное двойное игровое поле, Blitter (движок передачи блоков изображений на основе DMA со встроенной пиксельно-точной системой распознавания коллизий и прозрачностью) и Copper (растровый сопроцессор, позволявший выполнять операции с регистрами на основании позиции развёртки для создания множества очень красивых эффектов). В SAMD21 всего этого «железа» нет (за исключением довольно простого по сравнению с Blitter DMA), поэтому многое будет отрисовываться программно.
Мы хотим достичь следующих параметров:
- Разрешение 160 x 128 пикселей на 1,8-дюймовом дисплее SPI.
- Графика с 16 битами на пиксель;
- Максимально высокая частота кадров. Не менее 25 fps при тактовой частоте SPI 12 МГц, или 40 fps при 24 МГц;
- двойное игровое поле с параллаксным скроллингом;
- всё написано на C. Никакого ассемблерного кода;
- Пиксельно-точное распознавание коллизий;
- экранный оверлей.
Кажется, что достичь этих целей довольно трудно. Так и есть, особенно если мы откажемся от кода на asm!
Например, при 16-битном цвете для экрана размером 160×128 пикселей под экранный буфер потребуется 40 КБ, но у нас всего 32 КБ ОЗУ! А нам ещё нужен параллаксный скроллинг на двойном игровом поле и многое другое, с частотой не менее 25/40 fps!
Но ведь для нас нет ничего невозможного, правда?
Мы используем трюки и встроенные функции ATSAMD21! В качестве «железа» мы возьмём uChip, который можно купить в Itaca Store.

uChip: сердце нашего проекта!
Он имеет те же характеристики, что и Arduino Zero, но намного меньше, и к тому же дешевле оригинального Arduino Zero (да, можно купить и поддельный Arduino Zero за 10 долларов на AliExpress… но нам хочется отталкиваться от оригинала). Это позволит нам создать небольшую портативную консоль. Вы почти без усилий сможете адаптировать этот проект под Arduino Zero, только результат окажется довольно громоздким по размерам.
Также мы создали небольшую тестовую плату, в которой реализована портативная консоль «для бедных». Подробности ниже!

Мы не будем пользоваться фреймворком Arduino. Он не очень хорошо подходит, когда дело касается оптимизации и управления оборудованием. (И давайте не будем говорить про IDE!)
В этой статье мы расскажем, как пришли к окончательной версии игры, опишем все использованные оптимизации и критерии. Сама игра ещё не завершена, в ней не хватает звука, уровней и т.д. Однако её можно использовать как отправную точку для множества разных видов игр!
Кроме того, есть ещё множество возможностей оптимизации, даже без ассемблера!
Итак, давайте начнём наше путешествие!
Сложности
По сути, у проекта есть два сложных аспекта: тайминги и память (как ОЗУ, так и накопитель).
Память
Начнём с памяти. Во-первых, вместо хранения большой картинки уровня мы используем тайлы. На самом деле, если внимательно проанализировать большинство платформеров, то можно заметить, что они созданы из небольшого количества графических элементов (тайлов), которые многократно повторяются.

Turrican 2 на Amiga. Одна из лучших платформенных игр на все времена. В ней легко можно увидеть тайлы!
Мир/уровень кажется разнообразным благодаря различным комбинациям тайлов. Это экономит много памяти на накопителе, но не решает проблему огромного буфера кадров.
Второй используемый нами трюк возможен благодаря довольно большой вычислительной мощи uC и наличию DMA! Вместо хранения всех данных кадра в ОЗУ (да и зачем это нужно?) мы будем создавать сцену в каждом кадре с нуля. В частности, мы по-прежнему будем использовать буферы, но такие, чтобы в них уместился один горизонтальный блок данных графики высотой 16 пикселей.
Тайминги — ЦП
Когда инженеру нужно что-то создать, он первым делом проверяет, возможно ли это. Разумеется, мы в самом начале выполнили эту проверку!
Итак, нам нужно не менее 25 fps на экране 160×128 пикселей. То есть 512000 пикселей/с. Так как микроконтроллер работает с частотой 48 МГц, у нас есть не менее 93 тактовых циклов на пиксель. Эта величина снижается до 58 циклов, если мы стремимся к 40 fps.
На самом деле наш микроконтроллер способен обрабатывать до 2 пикселей за раз, потому что каждый пиксель занимает 16 бит, а ATSAMD21 имеет 32-битную внутреннюю шину, то есть показатели будут ещё лучше!
Величина в 93 тактовых циклов говорит нам, что задача вполне выполнима! На самом деле, мы можем прийти к выводу, что ЦП в одиночку справится со всеми задачами отрисовки без DMA. Скорее всего, это правда, особенно при работе с ассемблером. Однако с кодом будет очень трудно справляться. А на C он должен быть очень оптимизированным! На самом деле, Cortex M0+ не так дружественнен к C, как Cortex M3, и в нём недостаёт множества инструкций (в нём нет даже загрузки/сохранения с последующим/предварительным инкрементом/декрементом!), которые нужно реализовать двумя или несколькими более простыми инструкциями.
Давайте посмотрим, что нам нужно сделать для отрисовки двух игровых полей (предполагая, что мы уже знаем координаты x и y и т.п.).
- Вычислить расположение пикселя переднего плана во флеш-памяти.
- Получить значение пикселя.
- Если он прозрачен, то вычислить позицию пикселя фона во флеш-памяти.
- Получить значение пикселя.
- Вычислить целевое местоположение.
- Сохранить пиксель в буфер.
Более того, для каждого спрайта, который может попасть в буфер, должны выполняться такие операции:
- Вычисление позиции пикселя спрайта во флеш-памяти.
- Получение значения пикселя.
- Если он не прозрачен, то вычисление местоположения буфера назначения.
- Сохранение пикселя в буфере.
Все эти операции не только не реализованы как одна инструкция ASM, но и каждая инструкция ASM требует два цикла при доступе к ОЗУ/флеш-памяти.
Кроме того, у нас ещё нет геймплейной логики (которая, к счастью, занимает незначительное количество времени, потому что вычисляется один раз за кадр), распознавания коллизий, обработки буфера и инструкций, необходимых для отправки данных по SPI.
Например, вот псевдокод того, что нам придётся сделать (пока мы предполагаем, что в игре нет скроллинга, а у игрового поля фон постоянного цвета!) только для переднего плана.
Пусть cameraY и cameraX будут координатами верхнего левого угла дисплея в игровом мире.
Пусть xTilepos и yTilepos будут позицией текущего тайла на карте.
xTilepos = cameraX / 16; // this is a rightward shift of 4 bits.
yTilepos = cameraY / 16;
destBufferAddress = &buffer[0][0];
for tile = 0...9
nTile = gameMap[yTilepos][xTilepos];
tileDataAddress = &tileData[nTile];
xTilepos = xTilepos + 1;
for y = 0…15
for x = 0…15
pixel = *tileDataAddress;
tileDataAddress = tileDataAddress + 1;
*destBufferAddress = pixel;
destBufferAddress = destBufferAddress + 1;
next
destBufferAddress = destBufferAddress + 144; // point to next row
next
destBufferAddress = destBufferAddress – ( 160 * 16 - 16); // now point to the position where the next tile will be saved.
nextКоличество инструкций для 2560 пикселей (160 x 16) примерно равно 16k, т.е. по 6 на пиксель. На самом деле можно рисовать по два пикселя за раз. Это вдвое снижает действительное количество инструкций на пиксель, то есть количество высокоуровневых инструкций на пиксель примерно равно 3. Однако некоторые из этих высокоуровневых инструкций или будут разделены на две или более ассемблерных инструкций, или потребуют для завершения не менее двух циклов, потому что они осуществляют доступ к памяти. Также мы не учли сброс конвейера ЦП из-за переходов (jump) и состояний ожидания для флеш-памяти. Да, нам ещё далеко до 58-93 имеющихся в нашем распоряжении циклов, но нам ведь ещё нужно учесть фон игрового поля и спрайты.
Хотя мы видим, что задача решаема и на одном ЦП, DMA окажется намного быстрее. Прямой доступ к памяти оставляет ещё больше возможностей для экранных спрайтов или улучшения графических эффектов (например, мы можем реализовать альфа-смешение).
Мы увидим, что для настройки DMA для каждого тайла нам понадобится менее 100 инструкций C, то есть потребуется меньше 0,5 на пиксель! Разумеется, DMA всё равно придётся выполнять то же количество передач в памяти, но инкремент адреса и передача выполняются без вмешательства ЦП, который может заняться чем-то другим (например вычислением и отрисовкой спрайтов).
При помощи таймера SysTick мы выяснили, что время, необходимое для подготовки DMA для целого блока, а затем для завершения работы DMA, примерно равно 12k тактовым циклам. Заметьте: тактовых циклов! Не высокоуровневых инструкций! Количество циклов довольно высоко для всего лишь 2560 пикселей, т.е. 1280 32-битных слов. На самом деле мы получаем около 10 циклов на 32-битное слово. Однако нужно учитывать врмя, необходимое для подготовки DMA, а также время, требующееся DMA для загрузки из ОЗУ дескрипторов передачи (которые по сути содержат указатели и количество передаваемых байтов). Кроме того, всегда существует какая-нибудь смена шин памяти (чтобы ЦП не простаивал без данных), а для флеш-памяти требуется как минимум одно состояние ожидания.
Тайминги — SPI
Ещё одним узким местом является SPI. Достаточно ли 12 МГц для 25 fps? Ответ положительный: 12 МГц соответствует примерно 36 кадрам в секунду. Если мы используем 24 МГц, то предел увеличится вдвое!
Кстати, в спецификациях дисплея и микроконтроллера говорится, что максимальная скорость SPI равна, соответственно, 15 и 12 МГц. Мы протестировали и убедились, что её без проблем можно повысить до 24 МГц, по крайней мере, в нужном нам «направлении» (микроконтроллер выполняет запись в дисплей).
Мы будем использовать популярный 1,8-дюймовый дисплей SPI. Мы убедились, что с частотой 12 МГц нормально работают и ILI9163, и ST7735 (по крайней мере с 12 МГц. Проверено, что ST7735 работает с частотой до 24 МГц). Если вы хотите использовать тот же дисплей, что и в туториале «Как воспроизводить видео на Arduino Uno», то мы рекомендуем модифицировать его на случай, если в будущем вы захотите добавить поддержку SD. Мы используем версию с SD-картой, чтобы у нас было много места для других элементов, таких как звук или дополнительные уровни.
Графика
Как уже было сказано, в игре используются тайлы. Каждый уровень будет состоять из тайлов, повторяющихся согласно таблице, которую мы назвали «gameMap». Насколько большим будет каждый тайл? Размер каждого тайла сильно влияет на потребление памяти, детали и гибкость (и, как мы увидим позже, на скорость тоже). Слишком большие тайлы потребуют создания нового тайла для каждой небольшой вариации, необходимой нам. Это займёт много места на накопителе.

Два тайла размером 32×32 пикселя (левый и центральный), отличающиеся на небольшой частью (правая верхняя часть пикселя размером 16×16). Поэтому нам нужно хранить два разных тайла размером 32×32 пикселя. Если мы используем тайл размером 16×16 пикселей (справа), то нам понадобится хранить всего два тайла 16×16 (полностью белый тайл и тайл справа). Однако при использовании тайлов 16×16 у нас получится 4 элемента карты.
Однако потребуется меньше тайлов на экран, что повышает скорость (см. ниже) и уменьшает размер карты (т.е. количество строк и столбцов в таблице) каждого уровня. Слишком маленькие тайлы создают противоположную проблему. Таблицы карт становятся больше, а скорость снижается. Разумеется, мы не будем принимать глупые решения. например, выбирать тайлы размером 17×31 пикселя. Наш верный друг — степени двойки! Размер 16×16 — это практически «золотое правило», он используется во многих играх, и именно его мы выберем!
Наш экран имеет размер 160×128. Другими словами, нам понадобится 10×8 тайлов на экран, т.е. 80 записей в таблице. Для большого уровня из 10×10 экранов (или 100×1 экранов) потребуется всего 8000 записей (16 КБ, если мы используем по 16 бит на запись. Позже мы покажем, почему решили выбрать 16 бит на запись).
Сравним это с объёмом памяти, который скорее всего будет занят крупной картинкой на весь экран: 40 КБ *100= 4 МБ! Это безумие!
Давайте поговорим о системе отрисовки.
Каждый кадр должен содержать (в порядке отрисовки):
- графику фона (заднее игровое поле)
- саму графику уровня (передний план).
- спрайты
- текстовый/верхний оверлей.
В частности, мы последовательно будем выполнять следующие операции:
- Отрисовка фона + переднего плана (тайлов)
- отрисовка полупрозрачных тайлов + спрайтов + верхнего оверлея
- отправка данных по SPI.
Фон и полностью непрозрачные тайлы будут отрисовываться DMA. Полностью непрозрачный тайл — это тайл, в котором нет прозрачных пикселей.

Частично прозрачный тайл (слева) и полностью непрозрачный (справа). В частично прозрачном тайле некоторые пиксели (в левой нижней части) прозрачны, и поэтому сквозь эту область виден фон.
Частично прозрачные тайлы, спрайты и оверлей не могут эффективно отрисовываться DMA. На самом деле, система DMA чипа ATSAMD21 просто копирует данные, и в отличие Blitter компьютера Amiga, она не проверяет наличие прозрачности (задаваемой значением цвета). Все частично прозрачные элементы отрисовываются ЦП.

Затем данные передаются на дисплей при помощи DMA.
Создание конвейера
Как можно увидеть, если мы будем выполнять эти операции последовательно в одном буфере, то на это уйдёт куча времени. Фактически, пока работает DMA, ЦП не будет ничем занят, кроме как ожиданием завершения работы DMA! Это плохой способ реализации графического движка. Более того, когда DMA отправляет данные в устройство SPI, она не использует её полную пропускную способность. На самом деле, даже когда SPI работает с частотой 24 МГц, данные передаются только с частотой 3 МГц, что довольно мало. Другими словами, DMA используется не в полную силу: DMA может выполнять другие задачи, не особо теряя при этом в производительности.
Именно поэтому мы реализовали конвейер (pipeline), который является развитием идеи двойной буферизации (мы используем три буфера!). Разумеется, в конечном итоге операции всегда выполняются последовательно. Но ЦП и DMA одновременно выполняют разные задачи, не (особо) влияя при этом друг на друга.
Вот что происходит одновременно:
- Буфер используется для отрисовки данных фонов при помощи канала DMA 1;
- В другом буфере (который ранее был заполнен данными фонов) ЦП рисует спрайты и частично прозрачные тайлы;
- Затем ещё один буфер (который содержит полный горизонтальный блок данных) используется для отправки данных дисплею по SPI при помощи канала DMA 0. Разумеется, буфер, используемый для отправки данных по SPI, был ранее заполнен спрайтами, пока SPI отправлял предыдущий блок и пока другой буфер заполнялся тайлами.

DMA
Система DMA чипа ATSAMD21 несравнима с Blitter, но тем не менее у неё есть свои полезные особенности. Благодаря DMA мы можем обеспечивать очень высокую частоту обновления, несмотря на наличие двойного игрового поля.
Конфигурация передачи DMA хранится в ОЗУ, в «дескрипторах DMA», сообщающих DMA, как и откуда она должна выполнять текущую передачу. Эти дескрипторы можно соединять вместе: если связь есть (т.е. нет нулевого указателя), то после завершения передачи DMA автоматически получит следующий дескриптор. Благодаря использованию множественных дескрипторов DMA может выполнять «сложные передачи», которые полезны когда, например, исходный буфер является последовательностью несмежных сегментов смежных байтов. Однако на получение и запись дескрипторов требуется время, потому что нужно сохранять/загружать из ОЗУ 16 байтов дескриптора.
DMA может работать с данными разной длины: байтами, полусловами (16 бит) и словами (32 бит). В спецификации эта длина называется «beat size». Для SPI мы вынуждены использовать передачу байтов (хотя текущая спецификация REVD гласит, что SERCOM чипа ATSAMD21 имеют FIFO, который, по утверждению Microchip, может принимать и 32-битные данные, на деле кажется, что FIFO у них нет. В спецификации REVD также упоминается регистр SERCOM CTRLC, который отсутствует и в файлах заголовков, и в разделе описания регистров. К счастью, в отличие от AVR, у ATSAMD21 по крайней мере есть регистр данных буферизированной передачи, поэтому при отправке не будет пауз в передаче!). Для отрисовки тайлов мы, разумеется, используем 32 бита. Это позволяет копировать по два пикселя на beat. DMA чипа ATSAMD21 также позволяет увеличивать в каждом beat адрес источника или получателя на фиксированное число размеров beat.
Эти два аспекта очень важны и они определяют способ, которым мы отрисовываем тайлы.
Во-первых, если бы мы отрисовывали по одному пикселю на beat (16 бит), то уполовинили бы пропускную способность нашей системы. Мы не можем отказаться от полной пропускной способности!
Однако если мы будем отрисовывать по два пикселя на beat, игровое поле сможет скроллиться только на чётное количество пикселей, из-за чего пострадает плавность движения. Чтобы справиться с этим, можно использовать буфер, который на два или более пикселей больше. При отправке данных на дисплей мы будем использовать правильное смещение (0 или 1 пиксель), в зависимости от того, нужно ли нам двигать «камеру» на чётное или нечётное количество пикселей.
Однако ради упрощения мы зарезервируем место для 11 полных тайлов (160 + 16 пикселей), а не для 160+2 пиксеей. У такого подхода есть одно большое преимущество: нам не придётся вычислять и обновлять адрес получателя каждого дескриптора DMA (для этого бы потребовалось несколько инструкций, из-за чего на один тайл могло бы приходиться слишком много вычислений). Разумеется, мы будем отрисовывать только минимальное количество пикселей, т.е не более 162. Да, в конечном итоге мы потратим немного лишней памяти (с учётом трёх буферов это около 1500 байт) ради скорости и простоты. Также можно выполнить и дальнейшие оптимизации.

В этой GIF-анимации видны все 16-строчные буферы блока (без дескрипторов). Справа показано то, что на самом деле отображается на дисплее. В GIF показаны первые 32 кадра, на которых мы движемся вправо на 1 пиксель в каждом кадре. Чёрная область буфера — это часть, которая не обновляется, а её содержимое просто осталось от предыдущих операций. Когда экран прокручивается на нечётное количество кадров, в буфер отрисовывается область шириной 162 пикселя. Однако первый и последний столбец из них (которые в анимации выделены) отбрасываются. Когда величина прокрутки кратна 16 пикселям, операции отрисовки в буфере начинаются с первого столбца (x = 0).
А что насчёт вертикального скроллинга?
Им мы займёмся после того, как покажем способ хранения тайлов во флеш-памяти.
Как хранить тайлы
Наивным подходом (который устроил бы нас, если бы мы выполняли отрисовку только через ЦП) было бы хранение тайлов во флеш-памяти как последовательности цветов пикселей. Первый пиксель первой строки, второй, и так далее, до шестнадцатого. Затем мы сохраняем первый пиксель второй строки, второй, и так далее.
Почему такое решение наивно? Потому что в таком случае DMA сможет отрисовывать всего лишь по 16 пикселей на каждый дескриптор DMA! Следовательно, нам потребуется 16 дескрипторов, каждому из которых нужно 4+4 операций доступа к памяти (то есть для передачи 32 байт — 8 операций чтения памяти + 8 операций записи в память — DMA должна выполнить ещё 4 чтений + 4 записей). Это довольно неэффективно!
На самом деле, для каждого дескриптора DMA может выполнять инкремент адрес источника и получателя только на фиксированное количество слов. После копирования первой строки тайла в буфер адрес получателя должен быть увеличен не на 1 слово, а на такую величину, чтобы он указывал на следующую строку буфера. Это невозможно, потому что каждый дескриптор передачи указывает только инкремент передачи beat, который нельзя изменить.
Гораздо умнее будет последовательно отправлять первые два пикселя каждой строки тайла, то есть пиксели 0 и 1 строки 0, пиксели 0 и 1 строки 1, и т.д., до пикселей 0 и 1 строки 15. Затем мы отправляем пиксели 2 и 3 строки 0, и так далее.

Как хранится тайл.
На рисунке выше каждое число обозначает порядок, в котором 16-битный пиксель сохраняется в массив тайла.
Это можно сделать при помощи дескриптора, но нам нужны две вещи:
- Тайлы должны храниться таким образом, чтобы при инкременте источника на одно слово мы всегда указывали на верные позиции пикселей. Другими словами, если (r,c) — это пиксель в строке r и столбце c, то нам нужно последовательно сохранить пиксели (0,0)(0,1)(1,0)(1,1)(2,0)(2,1)… (15,0)(15,1)(0,2)(0,3)(1,2)(1,3)…
- Буфер должен иметь ширину 256 пикселей (а не 160)
Первой цели достичь очень легко: достаточно просто изменить порядок данных, это можно сделать при экспорте графики в файл c (см. изображение выше).
Вторую задачу можно решить потому, что DMA позволяет увеличивать адрес получателя после каждого beat на 512 байта. У этого есть два последствия:
- Мы не можем отправлять данные при помощи одного дескриптора по SPI целый блок. Это не особо серьёзная проблема, потому что в конечном итоге мы считываем один дескриптор через 160 пикселей. Влияние на производительность будет минимальным.
- Блок должен иметь размер 256 * 2 * 16 байт = 8 КБ, и в нём будет много «неиспользованного пространства».
Тем не менее, это пространство всё равно можно использовать, например, для дескрипторов.
На самом деле каждый дескриптор имеет размер 16 байт. Нам нужно не менее 10 * 8 (а на самом деле 11 * 8!) дескрипторов для тайлов и 16 дескрипторов для SPI.
Вот поэтому чем больше тайлы, тем выше скорость. На самом деле, если бы мы использовали, например, тайл размером 32 x 32, то нам потребовалось бы меньше дескрипторов на один экран (320 вместо 640). Это снизило бы излишнюю трату ресурсов.
Блок данных дисплея
Буфер блока, дескрипторы и другие данные хранятся в типе структуры, который мы назвали displayBlock_t.
displayBlock — это массив из 16 элементов displayLineData_t. Данные displayLine содержат 176 пикселей плюс 80 слов. В этих 80 словах мы храним дескрипторы дисплея или другие полезные данные дисплея (с помощью объединения (union)).


Так как у нас есть 16 строк, каждый тайл в позиции X использует 8 первых дескрипторов DMA (от 0 до 7) строк X. Поскольку у нас есть максимум 11 тайлов (строка дисплея имеет ширину 176 пикселя), то тайлы используют дескрипторы DMA только первых 11 строк данных. Дескрипторы 8-9 всех строк и дескрипторы 0-9 строк 11-15 свободны.
Из них дескрипторы 8 и 9 строк 0..7 будут использованы для SPI.
Дескрипторы 0..9 строк 11-15 (до 50 дескрипторов, хоть мы и будем использовать только 48 из них) будут использованы для фонового игрового поля.
На рисунке ниже показана их структура.

Фоновое игровое поле
Фоновое игровое поле обрабатывается иначе. Во-первых, если нам нужен плавный скроллинг, то придётся вернуться к двухпиксельному формату, потому что передний план и фон скроллятся с разными скоростями. Поэтому beat будут на полуслово больше. Несмотря на то, что это недостаток с точки зрения скорости, такой подход облегчает интеграцию. У нас осталось только небольшое количество дескрипторов, поэтому мелкие тайлы использовать нельзя. Кроме того, для упрощения работы и быстрого добавления параллакса мы будем применять длинные «сектора».
Фон отрисовывается только в том случае, если есть хотя бы один частично прозрачный пиксель. Это значит, что если есть только один прозрачный тайл, то будет отрисован фон. Разумеется, это лишняя трата пропускной способности, но зато она всё упрощает.
Сравним фоновое и переднее игровые поля:
- В фоне используются сектора, являющиеся длинными тайлами, хранящимися «наивным» образом.
- Фон имеет собственную карту, однако по горизонтали она повторяется. Благодаря этому используется меньше памяти.
- Фон имеет параллакс для каждого сектора.
Переднее игровое поле
Как было сказано, в каждом блоке у нас есть до 11 тайлов (10 полных тайла, или 9 полных тайлов и 2 частичных файла). Каждый из этих тайлов, если он не помечен как прозрачный, отрисовывается DMA. Если он не полностью непрозрачный, то он добавляется в список, который будет анализироваться позже, при отрисовке спрайтов.
Соединяем вместе два игровых поля
Дескрипторы фонового игрового поля (которые всегда вычисляются) и переднего игрового поля образуют очень длинный связанный список. Первая часть отрисовывает фоновое игровое поле. Вторая часть отрисовывает тайлы над фоном. Длина второй части может быть переменной, потому что дескрипторы DMA частично прозрачных тайлов исключаются из списка. Если блок содержит только непрозрачные тайлы, то DMA настраивается так. чтобы начать непосредственно с первого дескриптора первого тайла.
Спрайты и тайлы с прозрачностью
Тайлы с прозрачностью и спрайты обрабатываются почти одинаково. Выполняется анализ пикселя тайла/спрайта. Если он чёрный, то он прозрачен, а потому фоновый тайл не изменяется. Если он не чёрный, то фоновый пиксель заменяется пикселем спрайта/тайла.
Вертикальный скроллинг
При работе с горизонтальным скроллингом мы отрисовываем до 11 тайлов, даже если при отрисовке 11 тайлов первый и последний отрисовываются только частично. Такая частичная отрисовка возможна благодаря тому, что каждый дескриптор отрисовывает по два столбца тайла, поэтому мы легко можем задавать начало и конец связанного списка.
При работе с вертикальным скроллингом нам нужно вычислять и регистр получателя, и объём передачи. Их необходимо задавать по несколько раз за кадр. Чтобы избежать этой возни, мы можем просто отрисовывать до 9 полных блоков на кадр (8, если скроллинг кратен 16).
Оборудование
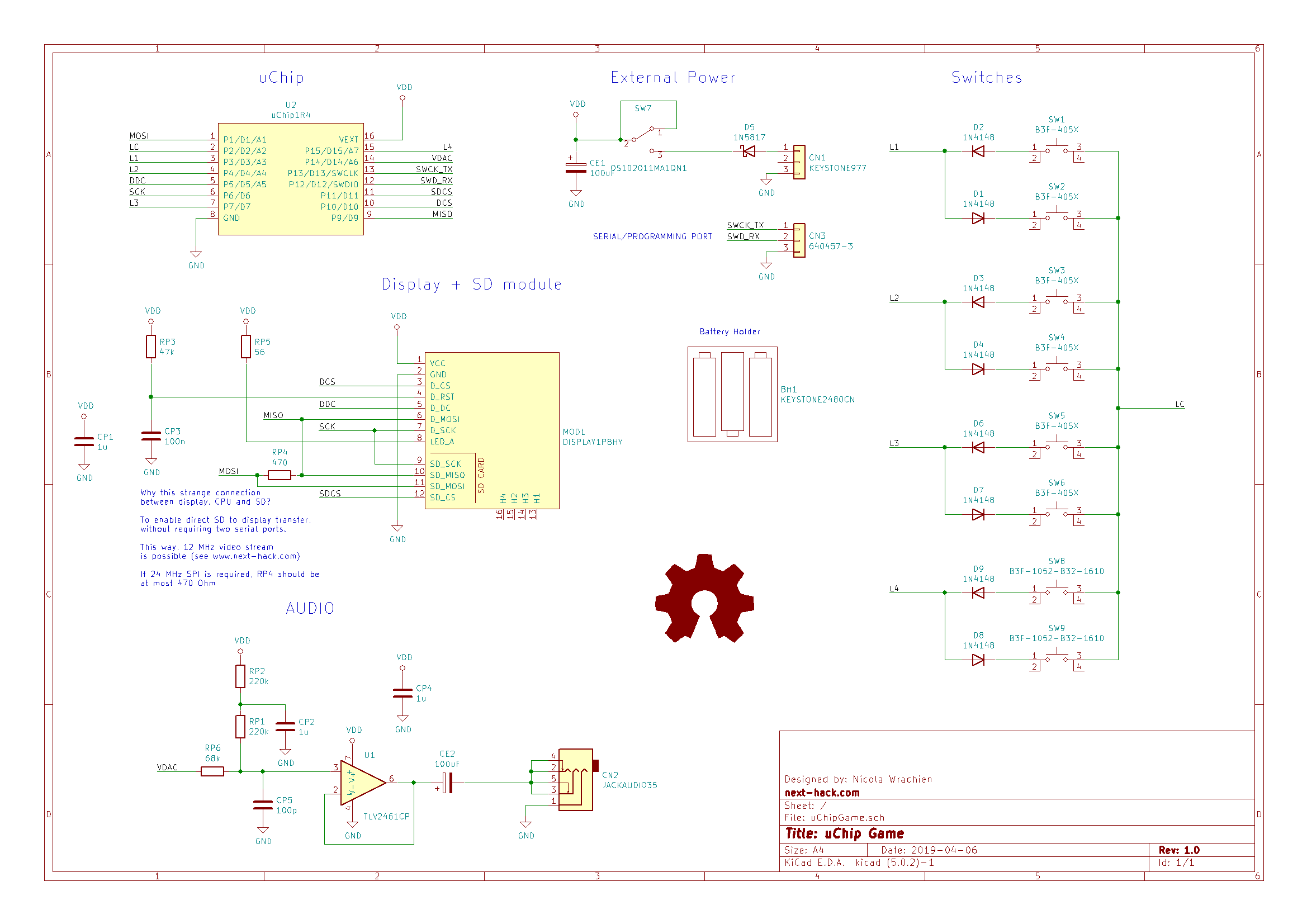
Как мы говорили, сердцем системы является uChip. А что насчёт всего остального?
Вот схема! Стоит упомянуть некоторые её аспекты.

Клавиши
Для оптимизации использования ввода-вывода мы используем небольшой трюк. У нас будет 4 шины датчиков L1-L4, и один общий провод LC. На общий провод попеременно подаётся 1 и 0. Соответственно, шины датчиков попеременно будут подтягиваться вниз или вверх при помощи внутренних утягивающих вверх/вниз резисторов. Две клавиши соединены между каждой из шин клавиш и общей шиной. Последовательно с этими двумя клавишами вставлен диод. Каждый из этих диодов имеет обратную полярность, чтобы каждый раз «считывалась» только одна клавиша.
Поскольку встроенного контроллера клавиатуры нет (и никакой встроенный контроллер клавиатуры не использует этот любопытный способ), восемь клавиш быстро опрашиваются в начале каждого кадра. Так как вводы должны утягиваться вверх и вниз, мы не можем (и не хотим) использовать внешние резисторы, поэтому нужно использовать интегрированные, которые могут иметь довольно высокое сопротивление (60 кОм). Это значит, что когда общая шина меняет состояние, а шины данных меняют своё состояние утягивания вверх/вниз, нужно вставить какую-то задержку, чтобы встроенный утягивающий вверх/вниз резистор сменил контракт и установил паразитную ёмкость на нужный уровень. Но мы не хотим ждать! Поэтому мы переводим общую шину в состояние высокого импеданса (чтобы не возникало разногласий), и предварительно меняем шины датчиков на логические значения 1 или 0, временно конфигурируя их как вывод. Позже они конфигурируются как ввод при помощи утягивания вверх или вниз. Так как выходное сопротивление имеет порядок десятков Ом, состояние меняется за несколько наносекунд, то есть при переключении шины датчиков обратно на ввод, она уже будет находиться в нужном состоянии. После этого общая шина переключается на вывод с противоположной полярностью.
Это значительно повышает скорость сканирования и избавляет от необходимости задержек/инструкций nop.
Подключение SPI
Мы подключили SD и дисплей так, чтобы они общались друг с другом без передачи данных в ATSAMD21. Это может быть полезно, если потребуется воспроизводить видео.
Резисторы, соединяющие MISO и MOSI, должны иметь низкие значения. Если они будут слишком большими, то SPI не заработает, потому что сигнал окажется слишком слабым.
Оптимизации и дальнейшая разработка
Одна из самых больших проблем — это использование ОЗУ. Три блока занимают по 8 КБ каждый, оставляя всего 8 КБ на стек и другие переменные. На данный момент у нас есть всего 1,3 КБ свободного ОЗУ + 4 КБ стека (4 КБ на стек — это очень много, возможно, мы его уменьшим).
Однако можно использовать блоки высотой не 16, а 8 пикселей. Это увеличит трату ресурсов на дескрипторы DMA, но почти вдвое снизит объём памяти, занимаемый буфером блоков (учтите, что количество дескрипторов не изменится, если мы по-прежнему будем использовать тайлы размером 16×16, поэтому нам придётся изменить структуру блока). Это может освободить примерно 7,5 КБ ОЗУ, что будет очень полезно для реализации таких функций, как изменяемая карта с секретами или добавление звука (хотя звук можно добавить даже при 1 КБ ОЗУ).
Ещё одна проблема — это спрайт, но данную модификацию выполнить гораздо проще, и для неё нужна будет только функция createNextFrameScene(). По сути, мы создаём в ОЗУ огромный массив с состоянием всех спрайтов. Затем для каждого спрайта мы вычисляем, находится ли его положение в пределах области экрана, а затем анимируем его и добавлем в список отрисовки.
Вместо этого можно выполнять оптимизацию. Например, в gameMap можно хранить не только значение тайла, но и флаг, обозначающий прозрачность тайла, задаваемый в редакторе. Это позволит нам быстро проверять, кем должен отрисовываться тайл: DMA или ЦП. Вот поэтому мы использовали для тайловой карты 16-битные записи. Если предположить, что у нас есть набор из 256 тайлов (на данный момент у нас меньше 128 тайлов, но на флеш-памяти есть достаточно места для добавления новых), то остаётся 7 свободных бит, которые можно использовать под другие цели. Три из этих семи бит можно использовать для обозначения того, хранится ли какой-то спрайт/объект. Например:
0b000 = нет хранящегося объекта
0b001 = опоссум
0b010 = орёл
0b011 = лягушка
0b100 = кристалл
0b101 = вишня
0b110 = переключатель
0b111 = другие объекты на будущее, например, исчезающие секретные стены.
Затем можно создать в ОЗУ битовую таблицу, в которой каждый бит означает, обнаружен ли (например, враг)/подобран ли (например, бонус)/активирован ли (переключатель) определённый объект. На уровне из 10×10 экранов для этого потребуется 8000 бит, т.е. 1 КБ ОЗУ. Бит обнуляется, когда обнаружен враг или подобран бонус.
В createNextFrameScene() мы должны проверять биты, соответствующие тайлам в текущей видимой области. Если они имеют значение 1:
- Если это бонус, то просто добавляем его в список спрайтов для отрисовки.
- Если это враг, то создаём динамический спрайт и сбрасываем флаг. В следующем кадре сцена будет содержать динамический спрайт, пока враг не уйдёт с экрана или не будет убит.
Такой подход имеет недостатки.
- Во-первых, спрайты в момент создания должны быть выровнены относительно границ тайлов (после чего они могут перемещаться с субпиксельной точностью). Однако это не очень серьёзная проблема.
- Во-вторых, нам всегда нужно будет проверять все 80 экранных тайлов, чтобы понять, какой спрайт надо отрисовывать. Гораздо умнее будет проверять битовую таблицу, потому что за одну операцию доступа мы сможем одновременно получать по 32 тайла. Но это всё равно будет проблемой для переключателей и объектов, имеющих состояние «включено/выключено» (они должны отрисовываться даже в позиции «выключено», т.е. когда их флаг в битовой таблице равен 0!). Для решения этой проблемы можно отрисовывать тайл всегда в состоянии «выключено», а затем перерисовывать поверх этого тайла спрайт во состоянии «включено» (который будет полностью совпадать по размерам с тайлом и быть полностью непрозрачным).
- В-третьих, нам нужно создавать динамический список спрайтов. Если игрока будут преследовать множество врагов (и он их не убьёт), то список может стать огромным. Кроме того, динамические списки всегда довольно сложно обрабатывать.
- В-четвёртых, игрок может жульничать, сначала открыв врага, а затем сделав так, чтобы он пропал с экрана. Частично эту проблему можно решить, сохраняя в динамические данные спрайта позицию тайла, в котором он был создан. Если спрайт уходит за экран и ещё не был убит, то мы снова устанавливаем бит, соответствующий его тайлу, чтобы когда игрок вернётся назад, враг появился снова!
- Это технику невозможно эффективно использовать, когда все персонажи должны действовать даже за пределами экрана (например, как в версии Unreal Tournament с видом сверху, где боты постоянно должны сражаться друг с другом).
Тем не менее, таким образом мы сможем гораздо эффективнее хранить и обрабатывать спрайты на уровне.
Однако эта техника больше относиться к «игровой логике», чем к графическому движку игры.
Возможно, в будущем мы реализуем эту функцию.
Подведём итоги
Надеемся, вам понравилась эта вводная статья. Нам нужно объяснить ещё множество аспектов, которые станут темами будущих статей.
А пока вы можете скачать полный исходный код игры! Если она вам понравится, то можете поддержать финансово художника ansimuz, нарисовавшего всю графику и бесплатно подарил её миру. Мы тоже принимаем пожертвования.
Игра пока ещё не завершена. Мы хотим добавить звук, много уровней, объекты, с которыми можно взаимодействовать и тому подобное. Можете создавать собственные модификации! Мы надеемся, что увидим новые игры с новой графикой и уровнями!
Скоро мы выпустим редактор карт, а пока он слишком рудиментарный, чтобы показывать его сообществу!
Видео
(Примечание: из-за плохого освещения видео записано с гораздо меньшей частотой кадров! Скоро мы обновим видео, чтобы вы могли оценить полную скорость в 40 fps!)
Благодарность
Графика игры (и тайлы, показанные на некоторых изображениях) взяты из бесплатного ассета «Sunny Land», созданного ansimuz.
Скачиваемые материалы
Исходный код проекта находится в открытом доступе, то есть он предоставляется бесплатно. Мы делимся им в надежде, что он окажется кому-то полезным. Мы не гарантируем, что из-за какого-нибудь бага/ошибки в коде не возникнет проблем!
Проект Atmel Studio 7 (исходный код)
Автор: PatientZero






{kind=link}