
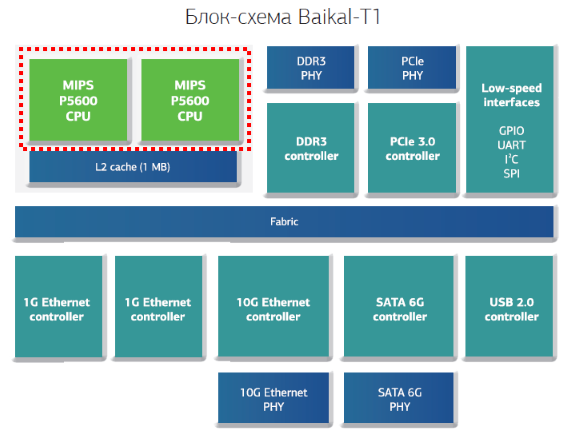
Коллеги из Байкал Электроникс предложили поработать с процессором Байкал-Т1 [L1] и написать о своих впечатлениях. Для них это способ рассказать разработчикам о возможностях и особенностях своего процессора. Для меня — шанс поближе познакомиться с системой на современном процессорном ядре и в будущем изобретать поменьше "велосипедов", добавляя, к примеру, новую функциональность в проект MIPSfpga-plus [L2]. Ну и обычное инженерное любопытство, опять же...
Сегодня речь пойдет о векторном расширении архитектуры MIPS SIMD, которое доступно в ядрах MIPS Warrior P-class P5600 [L3], а значит присутствует и в процессоре Байкал-Т1. Статья ориентирована на начинающих разработчиков.

Введение
Практически всегда с разработкой того или иного устройства (прибора/аппаратуры/программно-аппаратного комплекса и т.д.) связано решение задачи по обработке цифровых и аналоговых сигналов. На входе могут быть показания датчиков, сигналы с устройств ввода-вывода, информация из файла на диске и т.д. На выходе: изображение на мониторе, звук из колонок, сигналы управления приводами, показания индикаторов на приборной панели и пр. А "между" вводом и выводом — набор тех или иных математических операций.
Если кратко перечислить способы реализовать эту "математику в железе", то получим следующий список доступных разработчику инструментов, которые могут быть применены как вместе, так и по отдельности:
- реализация в виде аналоговой схемы.
- программная реализация на микроконтроллере.
- реализация на ПЛИС
- программно-аппаратная реализация в виде системы на кристалле
- использование цифрового сигнального процессора
- программная реализация на процессоре общего назначения
- использование графического контроллера
-
реализация в виде аналоговой схемы
Несмотря на засилье цифровых устройств, мир и органы чувств человека все равно остаются аналоговым. Хотим мы этого или нет, но даже обрабатывая информацию "исключительно" в цифре, перед входом АЦП нам все равно приходится ставить фильтр. Точно также на аналоговых компонентах могут быть реализованы интеграторы, дифференциаторы, сумматоры и т.д. За десятилетия господства аналоговой электроники инженеры накопили огромный опыт решения тех или иных задач и хороший разработчик (пусть даже цифровой электроники) учитывает это наследие [D1]; -
программная реализация на микроконтроллере
Обрабатываемых сигналов немного, а математика — не сложная или не требовательная к ресурсам? В этом случае относительно недорогой микроконтроллер с его АЦП, невысокой частотой работы, возможностями энергосбережения — вполне себе вариант. При необходимости "узкие" места можно написать на ассемблере; -
реализация на ПЛИС
Если у нас высокие требования к скорости, параллелизму, масштабированию решения, то описываем математику в виде модуля на Verilog или VHDL, выбираем ПЛИС, которая может работать на необходимой для обработки частоте. Если решение окажется очень удачным и появится смысл в его широком тиражировании — добро пожаловать в мир ASIC [L3]; -
программно-аппаратная реализация в виде системы на кристалле
Система слишком сложная, чтобы описывать ее целиком на Verilog, отдельную логику хочется запрограммировать на высокоуровневом языке, да и вообще — управлять всем из Linux? В этом случае вариантом решения для нас является СнК (System-on-a-Chip, SoC): берем готовое процессорное ядро (Nios II, MIPSfpga и т.д.) и обвешиваем его необходимыми нам периферийными модулями, среди которых будет наш особенный, выполняющий хитрую математику. Некоторые операции можно сделать доступными в виде процессорных команд [L4]. И да, в перспективе это тоже можно реализовать в ASIC; -
использование цифрового сигнального процессора (ЦСП)
Здесь мы, фактически, покупаем готовую микросхему с процессорным ядром, своим набором периферии и набором команд, специально ориентированным на высокоскоростную цифровую обработку сигналов. Вокруг нее мы и выстраиваем свое решение [L10, L5]; -
программная реализация на процессоре общего назначения
Каждый из производителей процессоров предлагает свои архитектурные решения, позволяющие оптимизировать выполнение тех или иных математических операций. И задача разработчика ПО при необходимости использовать предлагаемые производителем возможности для ускорения вычислений. Как раз об этом применительно к процессорам MIPS и пойдет речь ниже; - использование графического контроллера для вычислений
Для того, чтобы настоящий список был более полным, нельзя не упомянуть о возможности вынести наиболее сложные и ресурсоемкие вычисления на видеокарту [L6, L7].
Идеальных инструментов не бывает. Самый лучший инструмент — это тот, который гарантирует решение задачи в приемлемые сроки, для которого в проектной команде есть необходимые компетенции, и который либо есть в наличии, либо может быть приобретен с минимальными затратами. На принятие подобных решений накладываются ограничения бюджета, требования заказчика, а иногда и политические причины.
Надеюсь, что данная статья будет полезна в качестве вводной для тех читателей, кто столкнется с необходимостью оптимизировать выполнение тех или иных вычислений на процессоре Байкал-Т1 или ином другом, построенном на базе ядра (ядер) MIPS, где доступна технология MIPS SIMD.
Ресурсоемкость вычислений
Перед тем, как двигаться дальше, рассмотрим одну из часто встречающихся задач цифровой обработки сигналов (ЦОС) — фильтрацию. В качестве примера возьмем фильтр с конечной импульсной характеристикой (КИХ, FIR, finite impulse response) [L8]. Не углубляясь в теорию ЦОС и математические выкладки отметим основное — уравнение, которое описывает данный вид цифровых фильтров:

где x(n) — входной сигнал, y(n) — выходной сигнал, P — порядок фильтра, bi — коэффициенты фильтра. Это же уравнение можно записать следующим образом:

Природу входного сигнала x(n) в данном случае — проигнорируем. Пусть это будут данные, полученные с АЦП, но с тем же успехом они могут быть считаны из файла. Для нас в рассматриваемом случае это не имеет никакого значения. Так как наша текущая статья "про вычисления", а не "про ЦОС", то, соответственно, не будем погружаться и в Магию фильтров, а просто воспользуемся одним из онлайн сервисов для расчета коэффициентов [L9]:
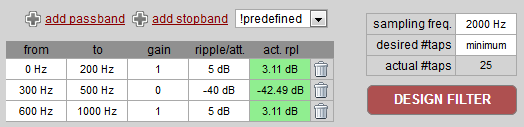
Устанавливаем желаемые параметры фильтрации (например, один из predefined вариантов: band stop — режекторный фильтр [L11]) и нажимаем кнопку Design Filter:

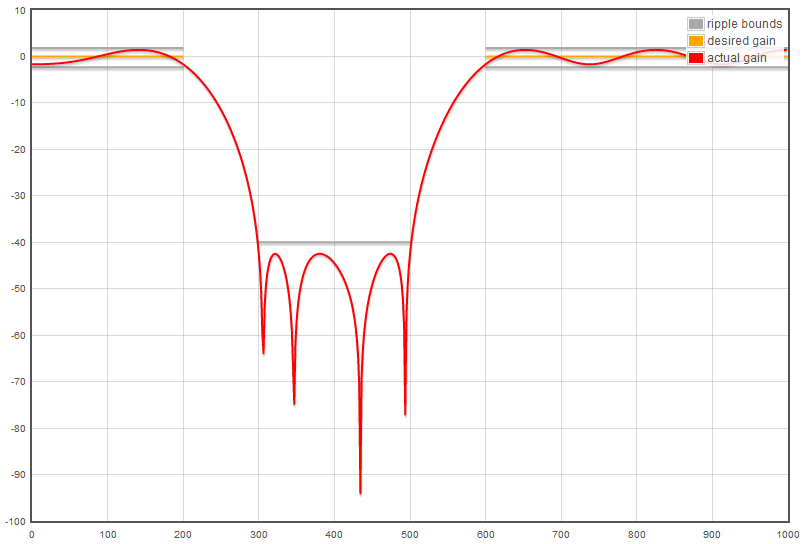
Результатом расчета является АЧХ фильтра [L12]:

Набор коэффициентов и исходный код:
#ifndef SAMPLEFILTER_H_
#define SAMPLEFILTER_H_
/*
FIR filter designed with
http://t-filter.appspot.com
sampling frequency: 2000 Hz
* 0 Hz - 200 Hz
gain = 1
desired ripple = 5 dB
actual ripple = 3.1077303934211127 dB
* 300 Hz - 500 Hz
gain = 0
desired attenuation = -40 dB
actual attenuation = -42.49314043914754 dB
* 600 Hz - 1000 Hz
gain = 1
desired ripple = 5 dB
actual ripple = 3.1077303934211127 dB
*/
#define SAMPLEFILTER_TAP_NUM 25
typedef struct {
double history[SAMPLEFILTER_TAP_NUM];
unsigned int last_index;
} SampleFilter;
void SampleFilter_init(SampleFilter* f);
void SampleFilter_put(SampleFilter* f, double input);
double SampleFilter_get(SampleFilter* f);
#endif#include "SampleFilter.h"
static double filter_taps[SAMPLEFILTER_TAP_NUM] = {
0.037391727827352596, -0.03299884552335979,
0.044230583967321345, 0.0023050970833628304,
-0.06768087195950104, -0.046347105409124706,
-0.011717387509232432, -0.0707342284185183,
-0.049766517282999544, 0.16086413543836361,
0.21561058688743148, -0.10159456907827959,
0.6638637561392535, -0.10159456907827959,
0.21561058688743148, 0.16086413543836361,
-0.049766517282999544, -0.0707342284185183,
-0.011717387509232432, -0.046347105409124706,
-0.06768087195950104, 0.0023050970833628304,
0.044230583967321345, -0.03299884552335979,
0.037391727827352596
};
void SampleFilter_init(SampleFilter* f) {
int i;
for(i = 0; i < SAMPLEFILTER_TAP_NUM; ++i)
f->history[i] = 0;
f->last_index = 0;
}
void SampleFilter_put(SampleFilter* f, double input) {
f->history[f->last_index++] = input;
if(f->last_index == SAMPLEFILTER_TAP_NUM)
f->last_index = 0;
}
double SampleFilter_get(SampleFilter* f) {
double acc = 0;
int index = f->last_index, i;
for(i = 0; i < SAMPLEFILTER_TAP_NUM; ++i) {
index = index != 0 ? index-1 : SAMPLEFILTER_TAP_NUM-1;
acc += f->history[index] * filter_taps[i];
};
return acc;
}Посмотрим на параметры фильтрации, функцию SampleFilter_get, вспомним приведенное выше уравнение КИХ-фильтра и отметим наиболее важные для нас моменты:
- для того, чтобы получить один отсчет y(n), что в нашем случае равносильно одному вызову функции SampleFilter_get нам необходимо в цикле обработать 25 входных отсчетов x(n) (порядок фильтра, см. макрос SAMPLEFILTER_TAP_NUM и "taps" на скриншоте интерфейса);
- если мы хотим, чтобы эта обработка выполнялась налету (к примеру, по мере поступления x(n) с АЦП), то мы должны успевать выполнять ее с учетом sampling frequency, которая в нашем случае 2000Hz;
- для каждого из этих 25 отсчетов x(n) мы выполняем ряд математических операций: умножение на соответствующий ему коэффициент, сложение в регистр-аккумулятор. Кроме того, не забываем о сопутствующих операциях по чтению/записи из/в память, на которые также требуется время.
Теперь предположим, что условия задачи в силу неких объективных причин были уточнены:

И в результате мы получаем вот такую АЧХ:

Что для нас важно:
- в связи с увеличением sampling frequency до 4000Hz в 2 раза сократилось время, которое мы можем потратить на вычисления, если хотим получать результаты налету;
- количество итераций (taps, порядок фильтра) при этом увеличилось почти в 3 раза (с 25 до 67). Если не вносить изменения в параметр неравномерности АЧХ (оставить ripple/att. = 5 dB), то количество итераций все равно увеличится в 2 раза;
- таким образом, незначительное изменение параметров фильтрации привело к увеличению ресурсоемкости вычислений в 6 раз (либо в 4).
Мне бы не хотелось, чтобы читатель обращал внимание на приведенные в примере абсолютные значения параметров фильтра. Основная мысль, которую хотелось бы донести, заключается в том, что в какой-то момент увеличение ресурсоемкости вычислений может выйти за ранее спрогнозированные пределы. И после небольшого изменения алгоритма, его параметров, или входных данных, вдруг, может оказаться что ваше процессорное ядро занимается только тем, что "лопатит" данные, да и то не успевает это делать, не говоря уже про выполнение остальных задач. Либо оно успешно справляется, но создаваемая при этом нагрузка или длительность вычислений уже не соответствуют требованиям к системе. И в этот момент перед вами как никогда встает задача оптимизации.
Скорость вычислений
После того, как мы на простом примере увидели проблему, посмотрим на ее решение. Производители процессоров идут на ряд ухищрений для того, чтобы повысить скорость вычислений: повышают частоту, увеличивают число процессорных ядер, добавляют новые команды, экспериментируют с конфигурацией конвейера, объемом кэша, переходят к использованию все более и более высокоскоростных шин и интерфейсов.
Также никто не забирает у разработчика право реализовать наиболее узкие места на ассемблере, поэкспериментировать с опциями компилятора, сменить алгоритм на менее ресурсоемкий либо ведущий себя более предсказуемо на том же диапазоне параметров.
Cконцентрируемся на двух способах повысить скорость обработки, которые не могут быть использованы без поддержки со стороны архитектуры процессора:
- объединение нескольких арифметических операций в одну команду;
- реализация SIMD-подхода.
Объединение арифметических операций
Вернемся к нашему фильтру и внимательно посмотрим на код функции SampleFilter_get:
double SampleFilter_get(SampleFilter* f) {
double acc = 0;
int index = f->last_index, i;
for(i = 0; i < SAMPLEFILTER_TAP_NUM; ++i) {
index = index != 0 ? index-1 : SAMPLEFILTER_TAP_NUM-1;
acc += f->history[index] * filter_taps[i];
};
return acc;
}И особенно на строку:
acc += f->history[index] * filter_taps[i];Здесь мы видим 2 последовательно выполняемые операции: умножение на коэффициент и накопление результатов этой команды в переменной-аккумуляторе. Подобное сочетание умножения и сложения очень часто встречается в алгоритмах ЦОС. Но если эти две операции так часто соседствуют друг с другом, то почему бы их не объединить в одну команду, выполняемую в течении 1 такта? Идея такого объединения пришла в головы инженеров очень давно. Так появилась команда "умножение с накоплением" (совмещённое умножение-сложение, multiply–accumulate operation, MAC), которая ныне присутствует во всех цифровых сигнальных процессорах:

SIMD-подход
Подойдем к решению с другой стороны. А почему бы нам, вместо того, чтобы работать с каждым отсчетом x(n) по отдельности, не объединить несколько отсчетов в один вектор (массив) и применить команду сразу ко всему вектору, а если точнее — то одновременно к каждому элементу вектора? В этом случае за один такт (не считая работу с памятью) можно будет обработать сразу несколько отсчетов:

И чем больше будет максимально допустимый размер вектора, тем выше будет скорость обработки данных. Данный принцип организации вычислений называется SIMD (single instruction, multiple data; одиночный поток команд, множественный поток данных) [L13]. На этом подходе строится работа векторных процессоров [L14] и векторных расширений к скалярным процессорам: SSE и AVX для архитектуры x86, MIPS SIMD [L15] для архитектуры MIPS.
MIPS SIMD
Теперь, когда мы понимаем основные принципы, на которых строятся векторные расширения архитектуры, можно перейти непосредственно к MIPS SIMD. Исчерпывающее описание этого расширения приведено в документации [D2], отметим основные моменты:
- доступно в двух вариантах: MIPS32 SIMD и MIPS64 SIMD. Так как Байкал-Т1 основан на ядрах архитектуры MIPS 32 r5, то в дальнейшем, упоминая MIPS SIMD, будем иметь в ввиду MIPS32 SIMD. На сайте и в документации Imagination Technologies оно также упоминается как MSA (MIPS SIMD Architecture);
-
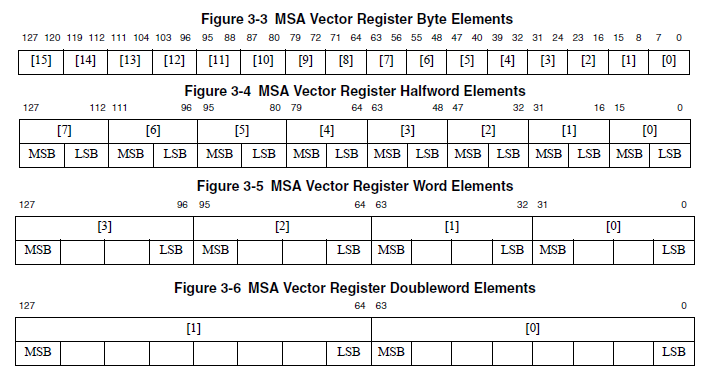
работа осуществляется с использованием 32x 128-битных регистров для обработки векторных данных. Каждый из которых может быть представлен как: 16x 8-битных векторов, 8x 16-битных, 4x 32-битных, либо 2x 64-битных:

- предполагает более 150 инструкций по обработке данных: целочисленных, с плавающей и фиксированной точкой, включая битовые операции, операции сравнения, конвертации:
| Mnemonic | Instruction Description |
|---|---|
| ADDV, ADDVI | Add |
| ADD_A, ADDS_A | Add and Saturated Add Absolute Values |
| ADDS_S, ADDS_U | Signed and Unsigned Saturated Add |
| HADD_S, HADD_U | Signed and Unsigned Horizontal Add |
| ASUB_S, ASUB_U | Absolute Value of Signed and Unsigned Subtract |
| AVE_S, AVE_U | Signed and Unsigned Average |
| AVER_S, AVER_U | Signed and Unsigned Average with Rounding |
| DOTP_S, DOTP_U | Signed and Unsigned Dot Product |
| DPADD_S, DPADD_U | Signed and Unsigned Dot Product Add |
| DPSUB_S, DPSUB_U | Signed and Unsigned Dot Product Subtract |
| DIV_S, DIV_U | Divide |
| MADDV | Multiply-Add |
| MAX_A, MIN_A | Maximum and Minimum of Absolute Values |
| MAX_S, MAXI_S, MAX_U, MAXI_U | Signed and Unsigned Maximum |
| MIN_S, MINI_S, MIN_U, MINI_U | Signed and Unsigned Maximum |
| MSUBV | Multiply-Subtract |
| MULV | Multiply |
| MOD_S, MOD_U | Signed and Unsigned Remainder (Modulo) |
| SAT_S, SAT_U | Signed and Unsigned Saturate |
| SUBS_S, SUBS_U | Signed and Unsigned Saturated Subtract |
| HSUB_S, HSUB_U | Signed and Unsigned Horizontal Subtract |
| SUBSUU_S | Signed Saturated Unsigned Subtract |
| SUBSUS_U | Unsigned Saturated Signed Subtract from Unsigned |
| SUBV, SUBVI | Subtract |
| Mnemonic | Instruction Description |
|---|---|
| AND, ANDI | Logical And |
| BCLR, BCLRI | Bit Clear |
| BINSL, BINSLI, BINSR, BINSRI | Bit Insert Left and Right |
| BMNZ, BMNZI | Bit Move If Not Zero |
| BMZ, BMZI | Bit Move If Zero |
| BNEG, BNEGI | Bit Negate |
| BSEL, BSELI | Bit Select |
| BSET, BSETI | Bit Set |
| NLOC Leading | One Bits Count |
| NLZC Leading | Zero Bits Count |
| NOR, NORI | Logical Negated Or |
| PCNT | Population (Bits Set to 1) Count |
| OR, ORI | Logical Or |
| SLL, SLLI | Shift Left |
| SRA, SRAI | Shift Right Arithmetic |
| SRAR, SRARI | Rounding Shift Right Arithmetic |
| SRL, SRLI | Shift Right Logical |
| SRLR, SRLRI | Rounding Shift Right Logical |
| XOR, XORI | Logical Exclusive Or |
| Mnemonic | Instruction Description |
|---|---|
| FADD | Floating-Point Addition |
| FDIV | Floating-Point Division |
| FEXP2 | Floating-Point Base 2 Exponentiation |
| FLOG2 | Floating-Point Base 2 Logarithm |
| FMADD, FMSUB | Floating-Point Fused Multiply-Add and Multiply-Subtract |
| FMAX, FMIN | Floating-Point Maximum and Minimum |
| FMAX_A, FMIN_A | Floating-Point Maximum and Minimum of Absolute Values |
| FMUL | Floating-Point Multiplication |
| FRCP | Approximate Floating-Point Reciprocal |
| FRINT | Floating-Point Round to Integer |
| FRSQRT | Approximate Floating-Point Reciprocal of Square Root |
| FSQRT | Floating-Point Square Root |
| FSUB | Floating-Point Subtraction |
| Mnemonic | Instruction Description |
|---|---|
| FCLASS | Floating-Point Class Mask |
| Mnemonic | Instruction Description |
|---|---|
| FCAF | Floating-Point Quiet Compare Always False |
| FCUN | Floating-Point Quiet Compare Unordered |
| FCOR | Floating-Point Quiet Compare Ordered |
| FCEQ | Floating-Point Quiet Compare Equal |
| FCUNE | Floating-Point Quiet Compare Unordered or Not Equal |
| FCUEQ | Floating-Point Quiet Compare Unordered or Equal |
| FCNE | Floating-Point Quiet Compare Not Equal |
| FCLT | Floating-Point Quiet Compare Less Than |
| FCULT | Floating-Point Quiet Compare Unordered or Less Than |
| FCLE | Floating-Point Quiet Compare Less Than or Equal |
| FCULE | Floating-Point Quiet Compare Unordered or Less Than or Equal |
| FSAF | Floating-Point Signaling Compare Always False |
| FSUN | Floating-Point Signaling Compare Unordered |
| FSOR | Floating-Point Signaling Compare Ordered |
| FSEQ | Floating-Point Signaling Compare Equal |
| FSUNE | Floating-Point Signaling Compare Unordered or Not Equal |
| FSUEQ | Floating-Point Signaling Compare Unordered or Equal |
| FSNE | Floating-Point Signaling Compare Not Equal |
| FSLT | Floating-Point Signaling Compare Less Than |
| FSULT | Floating-Point Signaling Compare Unordered or Less Than |
| FSLE | Floating-Point Signaling Compare Less Than or Equal |
| FSULE | Floating-Point Signaling Compare Unordered or Less Than or Equal |
| Mnemonic | Instruction Description |
|---|---|
| FEXDO | Floating-Point Down-Convert Interchange Format |
| FEXUPL, FEXUPR | Left-Half and Right-Half Floating-Point Up-Convert Interchange Format |
| FFINT_S, FFINT_U | Floating-Point Convert from Signed and Unsigned Integer |
| FFQL, FFQR | Left-Half and Right-Half Floating-Point Convert from Fixed-Point |
| FTINT_S, FTINT_U | Floating-Point Round and Convert to Signed and Unsigned Integer |
| FTRUNC_S, FTRUNC_U | Floating-Point Truncate and Convert to Signed and Unsigned Integer |
| FTQ | Floating-Point Round and Convert to Fixed-Point |
| Mnemonic | Instruction Description |
|---|---|
| MADD_Q, MADDR_Q | Fixed-Point Multiply and Add without and with Rounding |
| MSUB_Q, MSUBR_Q | Fixed-Point Multiply and Subtract without and with Rounding |
| MUL_Q, MULR_Q | Fixed-Point Multiply without and with Rounding |
| Mnemonic | Instruction Description |
|---|---|
| BNZ | Branch If Not Zero |
| BZ | Branch If Zero |
| CEQ, CEQI | Compare Equal |
| CLE_S, CLEI_S, CLE_U, CLEI_U | Compare Less-Than-or-Equal Signed and Unsigned |
| CLT_S, CLTI_S, CLT_U, CLTI_U | Compare Less-Than Signed and Unsigned |
| Mnemonic | Instruction Description |
|---|---|
| CFCMSA, CTCMSA | Copy from and copy to MSA Control Register |
| LD | Load Vector |
| LDI | Load Immediate |
| MOVE | Vector to Vector Move |
| SPLAT, SPLATI | Replicate Vector Element |
| FILL Fill | Vector from GPR |
| INSERT, INSVE | Insert GPR and Vector element 0 to Vector Element |
| COPY_S, COPY_U | Copy element to GPR Signed and Unsigned |
| ST | Store Vector |
| Mnemonic | Instruction Description |
|---|---|
| ILVEV, ILVOD | Interleave Even, Odd |
| ILVL, ILVR | Interleave the Left, Right |
| PCKEV, PCKOD | Pack Even and Odd Elements |
| SHF | Set Shuffle |
| SLD, SLDI | Element Slide |
| VSHF | Vector shuffle |
| Mnemonic | Instruction Description |
|---|---|
| LSA | Left-shift add or load/store address calculation |
- большинство команд доступно в нескольких вариантах, отличающихся друг от друга размером элемента вектора и типом обрабатываемых данных. Так уже знакомая нам операция умножения с накоплением реализована как: FMADD — для чисел с плавающей точкой, MADD_Q — для чисел с фиксированной точкой (с насыщением), MADDR_Q — для чисел с фиксированной точкой (с насыщением и округлением), MADDV — для целых чисел. При этом, к примеру, MADDV доступна в 4х вариантах: MADDV.B — когда элементами для побайтовой обработки (x8), MADDV.H — когда каждый элемент вектора является полусловом (x16), MADDV.W — словом (x32) и MADDV.D — двойным словом (x64)

Поддержка на уровне компилятора
MIPS SIMD поддерживается компилятором gcc, вместе с тем у этой поддержки есть свои особенности:
- для элементов вектора различной размерности введены отдельные типы данных [L16];
- мы избавлены от необходимости непосредственной работы с регистрами (работа ведется на уровне переменных соответствующего типа);
- для всех перечисленных выше операций введены высокоуровневые псевдонимы [L17];
- согласно документации gcc, компилятор не принимает самостоятельных решений об использовании MIPS SIMD, это же подтверждается неплохо разобранным примером применения MIPS SIMD, опубликованном на сайте Imagination Technologies [D3]. Таким образом, если провести грубую аналогию, то работа с MIPS SIMD ближе к написанию ассемблерных вставок, нежели к высокоуровневому программированию. Что должно учитываться при принятии решения об оптимизации.
#define ROUND_POWER_OF_TWO(value, n) (((value) + (1 << ((n) - 1))) >> (n))
static inline unsigned char clip_pixel(int i32Val)
{
return ((i32Val) > 255) ? 255u : ((i32Val) < 0) ? 0u : (i32Val);
}
void vert_filter_8taps_16width_c(unsigned char *pSrc, // SOURCE POINTER
int SrcStride, // SOURCE BUFFER PITCH
unsigned char *pDst, // DEST POINTER
int DstStride, // DEST BUFFER PITCH
char *pFilter, // POINTER TO FILTER BANK
int Height) // HEIGHT OF THE BLOCK
{
unsigned int Row, Col;
int FiltSum;
short Src0, Src1, Src2, Src3, Src4, Src5, Src6, Src7;
pSrc -= (8 / 2 - 1) * SrcStride; // MOVE INPUT SRC POINTER TO APPROPRIATE POSITION
// LOOP FOR NUMBER OF COLUMNS-16
for (Col = 0; Col < 16; ++Col)
{
Src0 = pSrc[0 * SrcStride];
Src1 = pSrc[1 * SrcStride];
Src2 = pSrc[2 * SrcStride];
Src3 = pSrc[3 * SrcStride];
Src4 = pSrc[4 * SrcStride];
Src5 = pSrc[5 * SrcStride];
Src6 = pSrc[6 * SrcStride];
// LOOP FOR NUMBER OF ROWS
for (Row = 0; Row < Height; Row++)
{
Src7 = pSrc[(7 + Row) * SrcStride];
FiltSum = 0;
// ACCUMULATED FILTER SUM += PIXEL * FILTER COEFF
FiltSum += (Src0 * pi8Filter[0]);
FiltSum += (Src1 * pi8Filter[1]);
FiltSum += (Src2 * pi8Filter[2]);
FiltSum += (Src3 * pi8Filter[3]);
FiltSum += (Src4 * pi8Filter[4]);
FiltSum += (Src5 * pi8Filter[5]);
FiltSum += (Src6 * pi8Filter[6]);
FiltSum += (Src7 * pi8Filter[7]);
FiltSum = ROUND_POWER_OF_TWO(FiltSum, 7); // ROUNDING
pDst[Row * DstStride] = clip_pixel(FiltSum);// CLIP RESULT IN 0-255(UNSIGNED CHAR)
// PREPARING FOR NEXT CONVOLUTION- SLIDING WINDOW
Src0 = Src1;
Src1 = Src2;
Src2 = Src3;
Src3 = Src4;
Src4 = Src5;
Src5 = Src6;
Src6 = Src7;
}
pSrc += 1;
pDst += 1;
}
}/* MSA VECTOR TYPES */
#define WRLEN 128 // VECTOR REGISTER LENGTH 128-BIT
#define NUMWRELEM (WRLEN >> 3)
typedef signed char IMG_VINT8 __attribute__ ((vector_size(NUMWRELEM))); //VEC SIGNED BYTES
typedef unsigned char IMG_VUINT8 __attribute__ ((vector_size(NUMWRELEM))); //VEC UNSIGNED BYTES
typedef short IMG_VINT16 __attribute__ ((vector_size(NUMWRELEM))); //VEC SIGNED HALF-WORD
#define LOAD_UNPACK_VEC(pSrc, SrcStride, vi16VecRight, vi16VecLeft)
{
IMG_VUINT8 vu8Src;
IMG_VINT16 vi16Vec0;
IMG_VINT8 vi8Tmp0;
/* LOAD INPUT VECTOR */
vu8Src = *((IMG_VINT8 *)(pSrc));
/* RANGE WARPING TO MAINTAIN 16 BIT PRECISION */
vi16Vec0 = __builtin_msa_xori_b(vu8Src, 128);
/* CALCULATE SIGN EXTENSION */
vi8Tmp0 = __builtin_msa_clti_s_b(vi16Vec0, 0);
/* INTERLEAVE RIGHT TO 16 BIT VEC */
vi16VecRight = __builtin_msa_ilvr_b(vi8Tmp0, vi16Vec0);
/* INTERLEAVE LEFT TO 16 BIT VEC */
vi16VecLeft = __builtin_msa_ilvl_b(vi8Tmp0, vi16Vec0);
pSrc += SrcStride;
}
void vert_filter_8taps_16width_msa(unsigned char *pSrc, // SOURCE POINTER
int SrcStride, // SOURCE BUFFER PITCH
unsigned char *pDst, // DEST POINTER
int DstStride, // DEST BUFFER PITH
char *pFilter, // POINTER TO FILTER BANK
int Height) // HEIGHT OF THE BLOCK
{
int u32LoopCnt;
VINT16 vi16Vec0Right, vi16Vec1Right, vi16Vec2Right, vi16Vec3Right;
VINT16 vi16Vec4Right, vi16Vec5Right, vi16Vec6Right, vi16Vec7Right;
VINT16 vi16Vec0Left, vi16Vec1Left, vi16Vec2Left, vi16Vec3Left;
VINT16 vi16Vec4Left, vi16Vec5Left, vi16Vec6Left, vi16Vec7Left;
VINT16 vi16Temp1Right, vi16Temp1Left;
VINT16 vi16Filt0, vi16Filt1, vi16Filt2, vi16Filt3;
VINT16 vi16Filt4, vi16Filt5, vi16Filt6, vi16Filt7;
pSrc -= (3 * SrcStride);
// PREPARE FILTER COEFF IN VEC REGISTERS
vi16Filt0 = __builtin_msa_fill_h(*(pFilter));
vi16Filt1 = __builtin_msa_fill_h(*(pFilter + 1));
vi16Filt2 = __builtin_msa_fill_h(*(pFilter + 2));
vi16Filt3 = __builtin_msa_fill_h(*(pFilter + 3));
vi16Filt4 = __builtin_msa_fill_h(*(pFilter + 4));
vi16Filt5 = __builtin_msa_fill_h(*(pFilter + 5));
vi16Filt6 = __builtin_msa_fill_h(*(pFilter + 6));
vi16Filt7 = __builtin_msa_fill_h(*(pFilter + 7));
//LOAD 7 INPUT VECTORS
LOAD_UNPACK_VEC(pSrc, SrcStride, vi16Vec0Right, vi16Vec0Left)
LOAD_UNPACK_VEC(pSrc, SrcStride, vi16Vec1Right, vi16Vec1Left)
LOAD_UNPACK_VEC(pSrc, SrcStride, vi16Vec2Right, vi16Vec2Left)
LOAD_UNPACK_VEC(pSrc, SrcStride, vi16Vec3Right, vi16Vec3Left)
LOAD_UNPACK_VEC(pSrc, SrcStride, vi16Vec4Right, vi16Vec4Left)
LOAD_UNPACK_VEC(pSrc, SrcStride, vi16Vec5Right, vi16Vec5Left)
LOAD_UNPACK_VEC(pSrc, SrcStride, vi16Vec6Right, vi16Vec6Left)
// START CONVOLUTION VERTICALLY
for (u32LoopCnt = Height; u32LoopCnt--; )
{
//LOAD 8TH INPUT VECTOR
LOAD_UNPACK_VEC(pSrc, SrcStride, vi16Vec7Right, vi16Vec7Left)
/* FILTER CALC */
IMG_VINT16 vi16Tmp1, vi16Tmp2;
IMG_VINT8 vi8Tmp3;
// 8 TAP VECTORIZED CONVOLUTION FOR RIGHT HALF
vi16Tmp1 = (vi16Vec0Right * vi16Filt0);
vi16Tmp1 += (vi16Vec1Right * vi16Filt1);
vi16Tmp1 += (vi16Vec2Right * vi16Filt2);
vi16Tmp1 += (vi16Vec3Right * vi16Filt3);
vi16Tmp2 = (vi16Vec4Right * vi16Filt4);
vi16Tmp2 += (vi16Vec5Right * vi16Filt5);
vi16Tmp2 += (vi16Vec6Right * vi16Filt6);
vi16Tmp2 += (vi16Vec7Right * vi16Filt7);
vi16Temp1Right = __builtin_msa_adds_s_h(vi16Tmp1, vi16Tmp2);
// 8 TAP VECTORIZED CONVOLUTION FOR LEFT HALF
vi16Tmp1 = (vi16Vec0Left * vi16Filt0);
vi16Tmp1 += (vi16Vec1Left * vi16Filt1);
vi16Tmp1 += (vi16Vec2Left * vi16Filt2);
vi16Tmp1 += (vi16Vec3Left * vi16Filt3);
vi16Tmp2 = (vi16Vec4Left * vi16Filt4);
vi16Tmp2 += (vi16Vec5Left * vi16Filt5);
vi16Tmp2 += (vi16Vec6Left * vi16Filt6);
vi16Tmp2 += (vi16Vec7Left * vi16Filt7);
vi16Temp1Left = __builtin_msa_adds_s_h(vi16Tmp1, vi16Tmp2);
// ROUNDING RIGHT SHIFT RANGE CLIPPING AND NARROWING
vi16Temp1Right = __builtin_msa_srari_h(vi16Temp1Right, 7);
vi16Temp1Right = __builtin_msa_sat_s_h(vi16Temp1Right, 7);
vi16Temp1Left = __builtin_msa_srari_h(vi16Temp1Left, 7);
vi16Temp1Left = __builtin_msa_sat_s_h(vi16Temp1Left, 7);
vi8Tmp3 = __builtin_msa_pckev_b(vi16Temp1Left, vi16Temp1Right);
vi8Tmp3 = __builtin_msa_xori_b(vi8Tmp3, 128);
// STORE OUTPUT VEC
*((IMG_VINT8 *)(pDst)) = (vi8Tmp3);
pDst += DstStride;
// PREPARING FOR NEXT CONVOLUTION- SLIDING WINDOW
vi16Vec0Right = vi16Vec1Right;
vi16Vec1Right = vi16Vec2Right;
vi16Vec2Right = vi16Vec3Right;
vi16Vec3Right = vi16Vec4Right;
vi16Vec4Right = vi16Vec5Right;
vi16Vec5Right = vi16Vec6Right;
vi16Vec6Right = vi16Vec7Right;
vi16Vec0Left = vi16Vec1Left;
vi16Vec1Left = vi16Vec2Left;
vi16Vec2Left = vi16Vec3Left;
vi16Vec3Left = vi16Vec4Left;
vi16Vec4Left = vi16Vec5Left;
vi16Vec5Left = vi16Vec6Left;
vi16Vec6Left = vi16Vec7Left;
}
}
Оценка производительности
Первоначально у меня были мысли написать простейшее приложение (синтетический тест) для оценки прироста производительности при использовании MIPS SIMD. Но несмотря на всю свою привлекательность, этот вариант не является показательным, ввиду его оторванности от реальных задач пользователя. На наше счастье работники Imagination Technologies и MIPS сделали весомый вклад в ffmpeg [L18] — широко используемое open source приложение, предназначенное для конвертации аудио и видео [L19]. Полагаю, что они как никто другой знают, как правильно использовать рассматриваемую технологию, а значит этот код должен быть максимально эффективен.
Таким образом, если мы скомпилируем ffmpeg в двух вариантах: с поддержкой MIPS SIMD и без нее, то можно будет сравнить скорость работы на одинаковых входных данных и по результатам сделать некий вывод об эффективности векторных вычислений.
Сборка ffmpeg
Выполняется на машине x86 под управлением ОС Linux. Используются средства разработки с сайта Imagination Technologies [L20] в режиме кросс-компиляции. Тесты выполняются на последнем стабильном релизе на момент написания статьи — ffmpeg 3.3 [L19].
Конфигурация ffmpeg для варианта с поддержкой MIPS SIMD:
./configure --enable-cross-compile --prefix=../ffmpeg-msa --cross-prefix=/home/stas/mipsfpga/toolchain/mips-mti-linux-gnu/2016.05-03/bin/mips-mti-linux-gnu- --arch=mips --cpu=p5600 --target-os=linux --extra-cflags="-EL -static" --extra-ldflags="-EL -static" --disable-iconvИ с отключенной поддержкой MIPS SIMD:
./configure --enable-cross-compile --prefix=../ffmpeg-soft --cross-prefix=/home/stas/mipsfpga/toolchain/mips-mti-linux-gnu/2016.05-03/bin/mips-mti-linux-gnu- --arch=mips --cpu=p5600 --target-os=linux --extra-cflags="-EL -static" --extra-ldflags="-EL -static" --disable-iconv --disable-msa| Параметр | Описание |
|---|---|
| --enable-cross-compile | сборка будет осуществляться на машине с архитектурой, отличной отцелевой |
| --prefix=../ffmpeg-msa | каталог, в который будут помещены файлы после команды make install |
| --cross-prefix=../mips-mti-linux-gnu- | путь к toolchain |
| --arch=mips | целевая архитектура — MIPS |
| --cpu=p5600 | целевое процессорное ядро — p5600 |
| --target-os=linux | целевая ОС — Linux |
| --extra-cflags="-EL -static" | целевая система — little endian, использовать статическоесвязывание |
| --extra-ldflags="-EL -static" | аналогично |
| --disable-iconv | отключить функциональность, связанную с кодировками текста |
| --disable-msa | не использовать MIPS SIMD |
Если вы планируете повторить эти действия, то учтите, что сборка ffmpeg 3.3 с поддержкой MIPS SIMD вываливается с мелкой ошибкой, для устранения которой необходимо в файл libavcodecmipshevcpred_msa.c добавить:
#include "libavcodec/hevcdec.h"Тестирование
Выполняется на процессоре Байкал-Т1:
# uname -a
Linux baikal-BFK-18446744073709551615 4.4.41-bfk #0 SMP Tue Apr 25 15:54:24 MSK 2017 mips GNU/LinuxВ качестве входных данных выступают два видеоролика закодированные с использованием x264 [L21] и x265 [L22]. Тестовой задачей является декодирование видео с получением скриншотов через равные промежутки времени:
./ffmpeg-mips/ffmpeg-msa/bin/ffmpeg -i ./The Simpsons Movie - Trailer_x264.mp4 -vf fps=1/10 ./out_img/ffmpeg-msa_x264_%d.jpg -report -benchmark
./ffmpeg-mips/ffmpeg-msa/bin/ffmpeg -i ./Tears_400_x265.mp4 -vf fps=1 ./out_img/ffmpeg-msa_x265_%d.jpg -report -benchmark
./ffmpeg-mips/ffmpeg-soft/bin/ffmpeg -i ./The Simpsons Movie - Trailer_x264.mp4 -vf fps=1/10 ./out_img/ffmpeg-soft_x264_%d.jpg -report -benchmark
./ffmpeg-mips/ffmpeg-soft/bin/ffmpeg -i ./Tears_400_x265.mp4 -vf fps=1 ./out_img/ffmpeg-soft_x265_%d.jpg -report -benchmark| Параметр | Описание |
|---|---|
| -i ./Tears_400_x265.mp4 | файл, который подлежит обработке |
| -vf fps=1 | период (частота) снятия скриншотов (1 сек — для короткого ролика, 10 сек — для длинного) |
| ./out_img/ffmpeg-softx264%d.jpg | шаблон имени выходного файла |
| -report | сформировать отчет по результатам работы |
| -benchmark | включить в отчет данные о производительности |
Результаты работы ffmpeg
| Сценарий | Длительность (cек) |
|---|---|
| декодирование x264 с поддержкой MIPS SIMD | 113 |
| декодирование x265 с поддержкой MIPS SIMD | 22 |
| декодирование x264 без MIPS SIMD | 164 |
| декодирование x265 без MIPS SIMD | 52 |
Таким образом, реальное время декодирования при использовании MIPS SIMD сокращается в 1.5 — 2.4 раза.
Полные логи работы ffmpeg опубликованы на github [L23].
ffmpeg started on 2010-10-18 at 00:30:26
Report written to "ffmpeg-20101018-003026.log"
Command line:
./ffmpeg-mips/ffmpeg-msa/bin/ffmpeg -i "./The Simpsons Movie - Trailer_x264.mp4" -vf "fps=1/10" "./out_img/ffmpeg-msa_x264_%d.jpg" -report -benchmark
ffmpeg version 3.3 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 4.9.2 (Codescape GNU Tools 2016.05-03 for MIPS MTI Linux)
configuration: --enable-cross-compile --prefix=../ffmpeg-msa --cross-prefix=/home/stas/mipsfpga/toolchain/mips-mti-linux-gnu/2016.05-03/bin/mips-mti-linux-gnu- --arch=mips --cpu=p5600 --target-os=linux --extra-cflags='-EL -static' --extra-ldflags='-EL -static' --disable-iconv
libavutil 55. 58.100 / 55. 58.100
libavcodec 57. 89.100 / 57. 89.100
libavformat 57. 71.100 / 57. 71.100
libavdevice 57. 6.100 / 57. 6.100
libavfilter 6. 82.100 / 6. 82.100
libswscale 4. 6.100 / 4. 6.100
libswresample 2. 7.100 / 2. 7.100
Splitting the commandline.
Reading option '-i' ... matched as input url with argument './The Simpsons Movie - Trailer_x264.mp4'.
Reading option '-vf' ... matched as option 'vf' (set video filters) with argument 'fps=1/10'.
Reading option './out_img/ffmpeg-msa_x264_%d.jpg' ... matched as output url.
Reading option '-report' ... matched as option 'report' (generate a report) with argument '1'.
Reading option '-benchmark' ... matched as option 'benchmark' (add timings for benchmarking) with argument '1'.
Finished splitting the commandline.
Parsing a group of options: global .
Applying option report (generate a report) with argument 1.
Applying option benchmark (add timings for benchmarking) with argument 1.
Successfully parsed a group of options.
Parsing a group of options: input url ./The Simpsons Movie - Trailer_x264.mp4.
Successfully parsed a group of options.
Opening an input file: ./The Simpsons Movie - Trailer_x264.mp4.
[file @ 0x1fce0e0] Setting default whitelist 'file,crypto'
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] Format mov,mp4,m4a,3gp,3g2,mj2 probed with size=2048 and score=100
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] ISO: File Type Major Brand: isom
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] Unknown dref type 0x206c7275 size 12
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] Unknown dref type 0x206c7275 size 12
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] Before avformat_find_stream_info() pos: 73516232 bytes read:65587 seeks:1 nb_streams:2
[h264 @ 0x1fcecb0] nal_unit_type: 7, nal_ref_idc: 3
[h264 @ 0x1fcecb0] nal_unit_type: 8, nal_ref_idc: 3
[h264 @ 0x1fcecb0] nal_unit_type: 6, nal_ref_idc: 0
[h264 @ 0x1fcecb0] nal_unit_type: 5, nal_ref_idc: 3
[h264 @ 0x1fcecb0] user data:"x264 - core 54 svn-620M - H.264/MPEG-4 AVC codec - Copyleft 2005 - http://www.videolan.org/x264.html - options: cabac=1 ref=5 deblock=1:0:0 analyse=0x1:0x131 me=umh subme=6 brdo=1 mixed_ref=0 me_range=16 chroma_me=1 trellis=1 8x8dct=0 cqm=0 deadzone=21,11 chroma_qp_offset=0 threads=1 nr=0 decimate=1 mbaff=0 bframes=1 b_pyramid=0 b_adapt=1 b_bias=0 direct=3 wpredb=0 bime=0 keyint=250 keyint_min=25 scenecut=40 rc=2pass bitrate=4214 ratetol=1.0 rceq='blurCplx^(1-qComp)' qcomp=0.60 qpmin=10 qpmax=51 qpstep=4 cplxblur=20.0 qblur=0.5 ip_ratio=1.40 pb_ratio=1.30"
[h264 @ 0x1fcecb0] Reinit context to 1280x544, pix_fmt: yuv420p
[h264 @ 0x1fcecb0] no picture
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] All info found
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] After avformat_find_stream_info() pos: 94845 bytes read:141348 seeks:2 frames:13
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from './The Simpsons Movie - Trailer_x264.mp4':
Metadata:
major_brand : isom
minor_version : 1
compatible_brands: isomavc1
creation_time : 2007-02-19T05:03:04.000000Z
Duration: 00:02:17.30, start: 0.000000, bitrate: 4283 kb/s
Stream #0:0(und), 12, 1/24000: Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 1280x544, 4221 kb/s, 23.98 fps, 23.98 tbr, 24k tbn, 47.95 tbc (default)
Metadata:
creation_time : 2007-02-19T05:03:04.000000Z
handler_name : GPAC ISO Video Handler
Stream #0:1(und), 1, 1/48000: Audio: aac (HE-AAC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 64 kb/s (default)
Metadata:
creation_time : 2007-02-19T05:03:08.000000Z
handler_name : GPAC ISO Audio Handler
Successfully opened the file.
Parsing a group of options: output url ./out_img/ffmpeg-msa_x264_%d.jpg.
Applying option vf (set video filters) with argument fps=1/10.
Successfully parsed a group of options.
Opening an output file: ./out_img/ffmpeg-msa_x264_%d.jpg.
Successfully opened the file.
detected 2 logical cores
[h264 @ 0x20191e0] nal_unit_type: 7, nal_ref_idc: 3
[h264 @ 0x20191e0] nal_unit_type: 8, nal_ref_idc: 3
Stream mapping:
Stream #0:0 -> #0:0 (h264 (native) -> mjpeg (native))
Press [q] to stop, [?] for help
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[h264 @ 0x20191e0] nal_unit_type: 6, nal_ref_idc: 0
[h264 @ 0x20191e0] nal_unit_type: 5, nal_ref_idc: 3
[h264 @ 0x20191e0] user data:"x264 - core 54 svn-620M - H.264/MPEG-4 AVC codec - Copyleft 2005 - http://www.videolan.org/x264.html - options: cabac=1 ref=5 deblock=1:0:0 analyse=0x1:0x131 me=umh subme=6 brdo=1 mixed_ref=0 me_range=16 chroma_me=1 trellis=1 8x8dct=0 cqm=0 deadzone=21,11 chroma_qp_offset=0 threads=1 nr=0 decimate=1 mbaff=0 bframes=1 b_pyramid=0 b_adapt=1 b_bias=0 direct=3 wpredb=0 bime=0 keyint=250 keyint_min=25 scenecut=40 rc=2pass bitrate=4214 ratetol=1.0 rceq='blurCplx^(1-qComp)' qcomp=0.60 qpmin=10 qpmax=51 qpstep=4 cplxblur=20.0 qblur=0.5 ip_ratio=1.40 pb_ratio=1.30"
[h264 @ 0x20191e0] Reinit context to 1280x544, pix_fmt: yuv420p
[h264 @ 0x20191e0] no picture
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[h264 @ 0x2026050] nal_unit_type: 1, nal_ref_idc: 2
[h264 @ 0x2060f00] nal_unit_type: 1, nal_ref_idc: 0
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[h264 @ 0x20191e0] nal_unit_type: 1, nal_ref_idc: 2
[Parsed_fps_0 @ 0x202bf50] Setting 'fps' to value '1/10'
[Parsed_fps_0 @ 0x202bf50] fps=1/10
[graph 0 input from stream 0:0 @ 0x202c6f0] Setting 'video_size' to value '1280x544'
[graph 0 input from stream 0:0 @ 0x202c6f0] Setting 'pix_fmt' to value '0'
[graph 0 input from stream 0:0 @ 0x202c6f0] Setting 'time_base' to value '1/24000'
[graph 0 input from stream 0:0 @ 0x202c6f0] Setting 'pixel_aspect' to value '0/1'
[graph 0 input from stream 0:0 @ 0x202c6f0] Setting 'sws_param' to value 'flags=2'
[graph 0 input from stream 0:0 @ 0x202c6f0] Setting 'frame_rate' to value '24000/1001'
[graph 0 input from stream 0:0 @ 0x202c6f0] w:1280 h:544 pixfmt:yuv420p tb:1/24000 fr:24000/1001 sar:0/1 sws_param:flags=2
[format @ 0x202c030] compat: called with args=[yuvj420p|yuvj422p|yuvj444p]
[format @ 0x202c030] Setting 'pix_fmts' to value 'yuvj420p|yuvj422p|yuvj444p'
[auto_scaler_0 @ 0x202c660] Setting 'flags' to value 'bicubic'
[auto_scaler_0 @ 0x202c660] w:iw h:ih flags:'bicubic' interl:0
[format @ 0x202c030] auto-inserting filter 'auto_scaler_0' between the filter 'Parsed_fps_0' and the filter 'format'
[AVFilterGraph @ 0x202bb80] query_formats: 4 queried, 2 merged, 1 already done, 0 delayed
[auto_scaler_0 @ 0x202c660] picking yuvj420p out of 3 ref:yuv420p alpha:0
[swscaler @ 0x202cf00] deprecated pixel format used, make sure you did set range correctly
[auto_scaler_0 @ 0x202c660] w:1280 h:544 fmt:yuv420p sar:0/1 -> w:1280 h:544 fmt:yuvj420p sar:0/1 flags:0x4
[mjpeg @ 0x1ff5f90] Forcing thread count to 1 for MJPEG encoding, use -thread_type slice or a constant quantizer if you want to use multiple cpu cores
[mjpeg @ 0x1ff5f90] intra_quant_bias = 96 inter_quant_bias = 0
Output #0, image2, to './out_img/ffmpeg-msa_x264_%d.jpg':
Metadata:
major_brand : isom
minor_version : 1
compatible_brands: isomavc1
encoder : Lavf57.71.100
Stream #0:0(und), 0, 10/1: Video: mjpeg, yuvj420p(pc), 1280x544, q=2-31, 200 kb/s, 0.10 fps, 0.10 tbn, 0.10 tbc (default)
Metadata:
creation_time : 2007-02-19T05:03:04.000000Z
handler_name : GPAC ISO Video Handler
encoder : Lavc57.89.100 mjpeg
Side data:
cpb: bitrate max/min/avg: 0/0/200000 buffer size: 0 vbv_delay: -1
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[Parsed_fps_0 @ 0x202bf50] Dropping 1 frame(s).
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
...
[h264 @ 0x2060f00] nal_unit_type: 1, nal_ref_idc: 2
[Parsed_fps_0 @ 0x202bf50] Dropping 1 frame(s).
[Parsed_fps_0 @ 0x202bf50] Dropping 1 frame(s).
[Parsed_fps_0 @ 0x202bf50] Dropping 1 frame(s).
[file @ 0x209dc40] Setting default whitelist 'file,crypto'
[AVIOContext @ 0x2189ab0] Statistics: 0 seeks, 1 writeouts
frame= 15 fps=0.2 q=1.6 size=N/A time=00:02:30.00 bitrate=N/A speed=2.03x
No more output streams to write to, finishing.
frame= 15 fps=0.2 q=1.6 Lsize=N/A time=00:02:30.00 bitrate=N/A speed=2.03x
video:1382kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
Input file #0 (./The Simpsons Movie - Trailer_x264.mp4):
Input stream #0:0 (video): 3288 packets read (72364468 bytes); 3288 frames decoded;
Input stream #0:1 (audio): 1 packets read (134 bytes);
Total: 3289 packets (72364602 bytes) demuxed
Output file #0 (./out_img/ffmpeg-msa_x264_%d.jpg):
Output stream #0:0 (video): 15 frames encoded; 15 packets muxed (1414925 bytes);
Total: 15 packets (1414925 bytes) muxed
bench: utime=113.070s
3288 frames successfully decoded, 0 decoding errors
bench: maxrss=39264kB
[Parsed_fps_0 @ 0x202bf50] 3288 frames in, 15 frames out; 3273 frames dropped, 0 frames duplicated.
[AVIOContext @ 0x1fd6230] Statistics: 73517562 bytes read, 5 seeksffmpeg started on 2010-10-18 at 00:27:58
Report written to "ffmpeg-20101018-002758.log"
Command line:
./ffmpeg-mips/ffmpeg-msa/bin/ffmpeg -i ./Tears_400_x265.mp4 -vf "fps=1" "./out_img/ffmpeg-msa_x265_%d.jpg" -report -benchmark
ffmpeg version 3.3 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 4.9.2 (Codescape GNU Tools 2016.05-03 for MIPS MTI Linux)
configuration: --enable-cross-compile --prefix=../ffmpeg-msa --cross-prefix=/home/stas/mipsfpga/toolchain/mips-mti-linux-gnu/2016.05-03/bin/mips-mti-linux-gnu- --arch=mips --cpu=p5600 --target-os=linux --extra-cflags='-EL -static' --extra-ldflags='-EL -static' --disable-iconv
libavutil 55. 58.100 / 55. 58.100
libavcodec 57. 89.100 / 57. 89.100
libavformat 57. 71.100 / 57. 71.100
libavdevice 57. 6.100 / 57. 6.100
libavfilter 6. 82.100 / 6. 82.100
libswscale 4. 6.100 / 4. 6.100
libswresample 2. 7.100 / 2. 7.100
Splitting the commandline.
Reading option '-i' ... matched as input url with argument './Tears_400_x265.mp4'.
Reading option '-vf' ... matched as option 'vf' (set video filters) with argument 'fps=1'.
Reading option './out_img/ffmpeg-msa_x265_%d.jpg' ... matched as output url.
Reading option '-report' ... matched as option 'report' (generate a report) with argument '1'.
Reading option '-benchmark' ... matched as option 'benchmark' (add timings for benchmarking) with argument '1'.
Finished splitting the commandline.
Parsing a group of options: global .
Applying option report (generate a report) with argument 1.
Applying option benchmark (add timings for benchmarking) with argument 1.
Successfully parsed a group of options.
Parsing a group of options: input url ./Tears_400_x265.mp4.
Successfully parsed a group of options.
Opening an input file: ./Tears_400_x265.mp4.
[file @ 0x1fce0e0] Setting default whitelist 'file,crypto'
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] Format mov,mp4,m4a,3gp,3g2,mj2 probed with size=2048 and score=100
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] ISO: File Type Major Brand: iso4
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] Unknown dref type 0x206c7275 size 12
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] Before avformat_find_stream_info() pos: 705972 bytes read:32827 seeks:1 nb_streams:1
[hevc @ 0x1fceca0] nal_unit_type: 32(VPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fceca0] Decoding VPS
[hevc @ 0x1fceca0] Main profile bitstream
[hevc @ 0x1fceca0] nal_unit_type: 33(SPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fceca0] Decoding SPS
[hevc @ 0x1fceca0] Main profile bitstream
[hevc @ 0x1fceca0] Decoding VUI
[hevc @ 0x1fceca0] nal_unit_type: 34(PPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fceca0] Decoding PPS
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] All info found
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1fcd980] After avformat_find_stream_info() pos: 20299 bytes read:65595 seeks:2 frames:1
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from './Tears_400_x265.mp4':
Metadata:
major_brand : iso4
minor_version : 1
compatible_brands: iso4hvc1
creation_time : 2014-08-25T18:10:46.000000Z
Duration: 00:00:13.96, start: 0.125000, bitrate: 404 kb/s
Stream #0:0(und), 1, 1/24000: Video: hevc (Main) (hvc1 / 0x31637668), yuv420p(tv), 1920x800, 402 kb/s, 24 fps, 24 tbr, 24k tbn, 24 tbc (default)
Metadata:
creation_time : 2014-08-25T18:10:46.000000Z
handler_name : hevc:fps=24@GPAC0.5.1-DEV-rev4807
Successfully opened the file.
Parsing a group of options: output url ./out_img/ffmpeg-msa_x265_%d.jpg.
Applying option vf (set video filters) with argument fps=1.
Successfully parsed a group of options.
Opening an output file: ./out_img/ffmpeg-msa_x265_%d.jpg.
Successfully opened the file.
detected 2 logical cores
[hevc @ 0x1fe5a00] nal_unit_type: 32(VPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fe5a00] Decoding VPS
[hevc @ 0x1fe5a00] Main profile bitstream
[hevc @ 0x1fe5a00] nal_unit_type: 33(SPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fe5a00] Decoding SPS
[hevc @ 0x1fe5a00] Main profile bitstream
[hevc @ 0x1fe5a00] Decoding VUI
[hevc @ 0x1fe5a00] nal_unit_type: 34(PPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fe5a00] Decoding PPS
Stream mapping:
Stream #0:0 -> #0:0 (hevc (native) -> mjpeg (native))
Press [q] to stop, [?] for help
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1fe5a00] nal_unit_type: 39(SEI_PREFIX), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fe5a00] nal_unit_type: 39(SEI_PREFIX), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fe5a00] nal_unit_type: 19(IDR_W_RADL), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fe5a00] Decoding SEI
[hevc @ 0x1fe5a00] Skipped PREFIX SEI 5
[hevc @ 0x1fe5a00] Decoding SEI
[hevc @ 0x1fe5a00] Skipped PREFIX SEI 6
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1ffeba0] nal_unit_type: 1(TRAIL_R), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x200c4d0] nal_unit_type: 1(TRAIL_R), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x200c4d0] Output frame with POC 0.
[hevc @ 0x1fe5a00] Decoded frame with POC 0.
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1fe5a00] nal_unit_type: 0(TRAIL_N), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1fe5a00] Output frame with POC 1.
[hevc @ 0x1ffeba0] Decoded frame with POC 5.
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1ffeba0] nal_unit_type: 0(TRAIL_N), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1ffeba0] Output frame with POC 2.
[hevc @ 0x200c4d0] Decoded frame with POC 3.
[Parsed_fps_0 @ 0x201a6c0] Setting 'fps' to value '1'
[Parsed_fps_0 @ 0x201a6c0] fps=1/1
[graph 0 input from stream 0:0 @ 0x201abb0] Setting 'video_size' to value '1920x800'
[graph 0 input from stream 0:0 @ 0x201abb0] Setting 'pix_fmt' to value '0'
[graph 0 input from stream 0:0 @ 0x201abb0] Setting 'time_base' to value '1/24000'
[graph 0 input from stream 0:0 @ 0x201abb0] Setting 'pixel_aspect' to value '0/1'
[graph 0 input from stream 0:0 @ 0x201abb0] Setting 'sws_param' to value 'flags=2'
[graph 0 input from stream 0:0 @ 0x201abb0] Setting 'frame_rate' to value '24/1'
[graph 0 input from stream 0:0 @ 0x201abb0] w:1920 h:800 pixfmt:yuv420p tb:1/24000 fr:24/1 sar:0/1 sws_param:flags=2
[format @ 0x201aad0] compat: called with args=[yuvj420p|yuvj422p|yuvj444p]
[format @ 0x201aad0] Setting 'pix_fmts' to value 'yuvj420p|yuvj422p|yuvj444p'
[auto_scaler_0 @ 0x201a350] Setting 'flags' to value 'bicubic'
[auto_scaler_0 @ 0x201a350] w:iw h:ih flags:'bicubic' interl:0
[format @ 0x201aad0] auto-inserting filter 'auto_scaler_0' between the filter 'Parsed_fps_0' and the filter 'format'
[AVFilterGraph @ 0x201a2f0] query_formats: 4 queried, 2 merged, 1 already done, 0 delayed
[auto_scaler_0 @ 0x201a350] picking yuvj420p out of 3 ref:yuv420p alpha:0
[swscaler @ 0x21d7da0] deprecated pixel format used, make sure you did set range correctly
[auto_scaler_0 @ 0x201a350] w:1920 h:800 fmt:yuv420p sar:0/1 -> w:1920 h:800 fmt:yuvj420p sar:0/1 flags:0x4
[mjpeg @ 0x1fe2ba0] Forcing thread count to 1 for MJPEG encoding, use -thread_type slice or a constant quantizer if you want to use multiple cpu cores
[mjpeg @ 0x1fe2ba0] intra_quant_bias = 96 inter_quant_bias = 0
Output #0, image2, to './out_img/ffmpeg-msa_x265_%d.jpg':
Metadata:
major_brand : iso4
minor_version : 1
compatible_brands: iso4hvc1
encoder : Lavf57.71.100
Stream #0:0(und), 0, 1/1: Video: mjpeg, yuvj420p(pc), 1920x800, q=2-31, 200 kb/s, 1 fps, 1 tbn, 1 tbc (default)
Metadata:
creation_time : 2014-08-25T18:10:46.000000Z
handler_name : hevc:fps=24@GPAC0.5.1-DEV-rev4807
encoder : Lavc57.89.100 mjpeg
Side data:
cpb: bitrate max/min/avg: 0/0/200000 buffer size: 0 vbv_delay: -1
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
...
No more output streams to write to, finishing.
frame= 15 fps=0.7 q=24.8 Lsize=N/A time=00:00:15.00 bitrate=N/A speed=0.668x
video:1084kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
Input file #0 (./Tears_400_x265.mp4):
Input stream #0:0 (video): 335 packets read (701773 bytes); 335 frames decoded;
Total: 335 packets (701773 bytes) demuxed
Output file #0 (./out_img/ffmpeg-msa_x265_%d.jpg):
Output stream #0:0 (video): 15 frames encoded; 15 packets muxed (1109604 bytes);
Total: 15 packets (1109604 bytes) muxed
bench: utime=22.300s
335 frames successfully decoded, 0 decoding errors
bench: maxrss=72432kB
[Parsed_fps_0 @ 0x201a6c0] 335 frames in, 15 frames out; 320 frames dropped, 0 frames duplicated.
[AVIOContext @ 0x1fd6220] Statistics: 734659 bytes read, 2 seeksffmpeg started on 2010-10-18 at 00:28:31
Report written to "ffmpeg-20101018-002831.log"
Command line:
./ffmpeg-mips/ffmpeg-soft/bin/ffmpeg -i "./The Simpsons Movie - Trailer_x264.mp4" -vf "fps=1/10" "./out_img/ffmpeg-soft_x264_%d.jpg" -report -benchmark
ffmpeg version 3.3 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 4.9.2 (Codescape GNU Tools 2016.05-03 for MIPS MTI Linux)
configuration: --enable-cross-compile --prefix=../ffmpeg-soft --cross-prefix=/home/stas/mipsfpga/toolchain/mips-mti-linux-gnu/2016.05-03/bin/mips-mti-linux-gnu- --arch=mips --cpu=p5600 --target-os=linux --extra-cflags='-EL -static' --extra-ldflags='-EL -static' --disable-iconv --disable-msa
libavutil 55. 58.100 / 55. 58.100
libavcodec 57. 89.100 / 57. 89.100
libavformat 57. 71.100 / 57. 71.100
libavdevice 57. 6.100 / 57. 6.100
libavfilter 6. 82.100 / 6. 82.100
libswscale 4. 6.100 / 4. 6.100
libswresample 2. 7.100 / 2. 7.100
Splitting the commandline.
Reading option '-i' ... matched as input url with argument './The Simpsons Movie - Trailer_x264.mp4'.
Reading option '-vf' ... matched as option 'vf' (set video filters) with argument 'fps=1/10'.
Reading option './out_img/ffmpeg-soft_x264_%d.jpg' ... matched as output url.
Reading option '-report' ... matched as option 'report' (generate a report) with argument '1'.
Reading option '-benchmark' ... matched as option 'benchmark' (add timings for benchmarking) with argument '1'.
Finished splitting the commandline.
Parsing a group of options: global .
Applying option report (generate a report) with argument 1.
Applying option benchmark (add timings for benchmarking) with argument 1.
Successfully parsed a group of options.
Parsing a group of options: input url ./The Simpsons Movie - Trailer_x264.mp4.
Successfully parsed a group of options.
Opening an input file: ./The Simpsons Movie - Trailer_x264.mp4.
[file @ 0x1f4a0e0] Setting default whitelist 'file,crypto'
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] Format mov,mp4,m4a,3gp,3g2,mj2 probed with size=2048 and score=100
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] ISO: File Type Major Brand: isom
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] Unknown dref type 0x206c7275 size 12
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] Unknown dref type 0x206c7275 size 12
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] Before avformat_find_stream_info() pos: 73516232 bytes read:65587 seeks:1 nb_streams:2
[h264 @ 0x1f4acb0] nal_unit_type: 7, nal_ref_idc: 3
[h264 @ 0x1f4acb0] nal_unit_type: 8, nal_ref_idc: 3
[h264 @ 0x1f4acb0] nal_unit_type: 6, nal_ref_idc: 0
[h264 @ 0x1f4acb0] nal_unit_type: 5, nal_ref_idc: 3
[h264 @ 0x1f4acb0] user data:"x264 - core 54 svn-620M - H.264/MPEG-4 AVC codec - Copyleft 2005 - http://www.videolan.org/x264.html - options: cabac=1 ref=5 deblock=1:0:0 analyse=0x1:0x131 me=umh subme=6 brdo=1 mixed_ref=0 me_range=16 chroma_me=1 trellis=1 8x8dct=0 cqm=0 deadzone=21,11 chroma_qp_offset=0 threads=1 nr=0 decimate=1 mbaff=0 bframes=1 b_pyramid=0 b_adapt=1 b_bias=0 direct=3 wpredb=0 bime=0 keyint=250 keyint_min=25 scenecut=40 rc=2pass bitrate=4214 ratetol=1.0 rceq='blurCplx^(1-qComp)' qcomp=0.60 qpmin=10 qpmax=51 qpstep=4 cplxblur=20.0 qblur=0.5 ip_ratio=1.40 pb_ratio=1.30"
[h264 @ 0x1f4acb0] Reinit context to 1280x544, pix_fmt: yuv420p
[h264 @ 0x1f4acb0] no picture
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] All info found
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] After avformat_find_stream_info() pos: 94845 bytes read:141348 seeks:2 frames:13
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from './The Simpsons Movie - Trailer_x264.mp4':
Metadata:
major_brand : isom
minor_version : 1
compatible_brands: isomavc1
creation_time : 2007-02-19T05:03:04.000000Z
Duration: 00:02:17.30, start: 0.000000, bitrate: 4283 kb/s
Stream #0:0(und), 12, 1/24000: Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 1280x544, 4221 kb/s, 23.98 fps, 23.98 tbr, 24k tbn, 47.95 tbc (default)
Metadata:
creation_time : 2007-02-19T05:03:04.000000Z
handler_name : GPAC ISO Video Handler
Stream #0:1(und), 1, 1/48000: Audio: aac (HE-AAC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 64 kb/s (default)
Metadata:
creation_time : 2007-02-19T05:03:08.000000Z
handler_name : GPAC ISO Audio Handler
Successfully opened the file.
Parsing a group of options: output url ./out_img/ffmpeg-soft_x264_%d.jpg.
Applying option vf (set video filters) with argument fps=1/10.
Successfully parsed a group of options.
Opening an output file: ./out_img/ffmpeg-soft_x264_%d.jpg.
Successfully opened the file.
detected 2 logical cores
[h264 @ 0x1f951e0] nal_unit_type: 7, nal_ref_idc: 3
[h264 @ 0x1f951e0] nal_unit_type: 8, nal_ref_idc: 3
Stream mapping:
Stream #0:0 -> #0:0 (h264 (native) -> mjpeg (native))
Press [q] to stop, [?] for help
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[h264 @ 0x1f951e0] nal_unit_type: 6, nal_ref_idc: 0
[h264 @ 0x1f951e0] nal_unit_type: 5, nal_ref_idc: 3
[h264 @ 0x1f951e0] user data:"x264 - core 54 svn-620M - H.264/MPEG-4 AVC codec - Copyleft 2005 - http://www.videolan.org/x264.html - options: cabac=1 ref=5 deblock=1:0:0 analyse=0x1:0x131 me=umh subme=6 brdo=1 mixed_ref=0 me_range=16 chroma_me=1 trellis=1 8x8dct=0 cqm=0 deadzone=21,11 chroma_qp_offset=0 threads=1 nr=0 decimate=1 mbaff=0 bframes=1 b_pyramid=0 b_adapt=1 b_bias=0 direct=3 wpredb=0 bime=0 keyint=250 keyint_min=25 scenecut=40 rc=2pass bitrate=4214 ratetol=1.0 rceq='blurCplx^(1-qComp)' qcomp=0.60 qpmin=10 qpmax=51 qpstep=4 cplxblur=20.0 qblur=0.5 ip_ratio=1.40 pb_ratio=1.30"
[h264 @ 0x1f951e0] Reinit context to 1280x544, pix_fmt: yuv420p
[h264 @ 0x1f951e0] no picture
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[h264 @ 0x1fa2050] nal_unit_type: 1, nal_ref_idc: 2
[h264 @ 0x1fdcf00] nal_unit_type: 1, nal_ref_idc: 0
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[h264 @ 0x1f951e0] nal_unit_type: 1, nal_ref_idc: 2
[Parsed_fps_0 @ 0x1fa7f50] Setting 'fps' to value '1/10'
[Parsed_fps_0 @ 0x1fa7f50] fps=1/10
[graph 0 input from stream 0:0 @ 0x1fa86f0] Setting 'video_size' to value '1280x544'
[graph 0 input from stream 0:0 @ 0x1fa86f0] Setting 'pix_fmt' to value '0'
[graph 0 input from stream 0:0 @ 0x1fa86f0] Setting 'time_base' to value '1/24000'
[graph 0 input from stream 0:0 @ 0x1fa86f0] Setting 'pixel_aspect' to value '0/1'
[graph 0 input from stream 0:0 @ 0x1fa86f0] Setting 'sws_param' to value 'flags=2'
[graph 0 input from stream 0:0 @ 0x1fa86f0] Setting 'frame_rate' to value '24000/1001'
[graph 0 input from stream 0:0 @ 0x1fa86f0] w:1280 h:544 pixfmt:yuv420p tb:1/24000 fr:24000/1001 sar:0/1 sws_param:flags=2
[format @ 0x1fa8030] compat: called with args=[yuvj420p|yuvj422p|yuvj444p]
[format @ 0x1fa8030] Setting 'pix_fmts' to value 'yuvj420p|yuvj422p|yuvj444p'
[auto_scaler_0 @ 0x1fa8660] Setting 'flags' to value 'bicubic'
[auto_scaler_0 @ 0x1fa8660] w:iw h:ih flags:'bicubic' interl:0
[format @ 0x1fa8030] auto-inserting filter 'auto_scaler_0' between the filter 'Parsed_fps_0' and the filter 'format'
[AVFilterGraph @ 0x1fa7b80] query_formats: 4 queried, 2 merged, 1 already done, 0 delayed
[auto_scaler_0 @ 0x1fa8660] picking yuvj420p out of 3 ref:yuv420p alpha:0
[swscaler @ 0x1fa8f00] deprecated pixel format used, make sure you did set range correctly
[auto_scaler_0 @ 0x1fa8660] w:1280 h:544 fmt:yuv420p sar:0/1 -> w:1280 h:544 fmt:yuvj420p sar:0/1 flags:0x4
[mjpeg @ 0x1f71f90] Forcing thread count to 1 for MJPEG encoding, use -thread_type slice or a constant quantizer if you want to use multiple cpu cores
[mjpeg @ 0x1f71f90] intra_quant_bias = 96 inter_quant_bias = 0
Output #0, image2, to './out_img/ffmpeg-soft_x264_%d.jpg':
Metadata:
major_brand : isom
minor_version : 1
compatible_brands: isomavc1
encoder : Lavf57.71.100
Stream #0:0(und), 0, 10/1: Video: mjpeg, yuvj420p(pc), 1280x544, q=2-31, 200 kb/s, 0.10 fps, 0.10 tbn, 0.10 tbc (default)
Metadata:
creation_time : 2007-02-19T05:03:04.000000Z
handler_name : GPAC ISO Video Handler
encoder : Lavc57.89.100 mjpeg
Side data:
cpb: bitrate max/min/avg: 0/0/200000 buffer size: 0 vbv_delay: -1
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[Parsed_fps_0 @ 0x1fa7f50] Dropping 1 frame(s).
[h264 @ 0x1fa2050] nal_unit_type: 1, nal_ref_idc: 0
...
[AVIOContext @ 0x2229af0] Statistics: 0 seeks, 1 writeouts
No more output streams to write to, finishing.
frame= 15 fps=0.1 q=1.6 Lsize=N/A time=00:02:30.00 bitrate=N/A speed=1.45x
video:1382kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
Input file #0 (./The Simpsons Movie - Trailer_x264.mp4):
Input stream #0:0 (video): 3288 packets read (72364468 bytes); 3288 frames decoded;
Input stream #0:1 (audio): 1 packets read (134 bytes);
Total: 3289 packets (72364602 bytes) demuxed
Output file #0 (./out_img/ffmpeg-soft_x264_%d.jpg):
Output stream #0:0 (video): 15 frames encoded; 15 packets muxed (1414925 bytes);
Total: 15 packets (1414925 bytes) muxed
bench: utime=164.240s
3288 frames successfully decoded, 0 decoding errors
bench: maxrss=39936kB
[Parsed_fps_0 @ 0x1fa7f50] 3288 frames in, 15 frames out; 3273 frames dropped, 0 frames duplicated.
[AVIOContext @ 0x1f52230] Statistics: 73517562 bytes read, 5 seeks
ffmpeg started on 2010-10-18 at 00:27:14
Report written to "ffmpeg-20101018-002714.log"
Command line:
./ffmpeg-mips/ffmpeg-soft/bin/ffmpeg -i ./Tears_400_x265.mp4 -vf "fps=1" "./out_img/ffmpeg-soft_x265_%d.jpg" -report -benchmark
ffmpeg version 3.3 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 4.9.2 (Codescape GNU Tools 2016.05-03 for MIPS MTI Linux)
configuration: --enable-cross-compile --prefix=../ffmpeg-soft --cross-prefix=/home/stas/mipsfpga/toolchain/mips-mti-linux-gnu/2016.05-03/bin/mips-mti-linux-gnu- --arch=mips --cpu=p5600 --target-os=linux --extra-cflags='-EL -static' --extra-ldflags='-EL -static' --disable-iconv --disable-msa
libavutil 55. 58.100 / 55. 58.100
libavcodec 57. 89.100 / 57. 89.100
libavformat 57. 71.100 / 57. 71.100
libavdevice 57. 6.100 / 57. 6.100
libavfilter 6. 82.100 / 6. 82.100
libswscale 4. 6.100 / 4. 6.100
libswresample 2. 7.100 / 2. 7.100
Splitting the commandline.
Reading option '-i' ... matched as input url with argument './Tears_400_x265.mp4'.
Reading option '-vf' ... matched as option 'vf' (set video filters) with argument 'fps=1'.
Reading option './out_img/ffmpeg-soft_x265_%d.jpg' ... matched as output url.
Reading option '-report' ... matched as option 'report' (generate a report) with argument '1'.
Reading option '-benchmark' ... matched as option 'benchmark' (add timings for benchmarking) with argument '1'.
Finished splitting the commandline.
Parsing a group of options: global .
Applying option report (generate a report) with argument 1.
Applying option benchmark (add timings for benchmarking) with argument 1.
Successfully parsed a group of options.
Parsing a group of options: input url ./Tears_400_x265.mp4.
Successfully parsed a group of options.
Opening an input file: ./Tears_400_x265.mp4.
[file @ 0x1f4a0e0] Setting default whitelist 'file,crypto'
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] Format mov,mp4,m4a,3gp,3g2,mj2 probed with size=2048 and score=100
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] ISO: File Type Major Brand: iso4
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] Unknown dref type 0x206c7275 size 12
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] Before avformat_find_stream_info() pos: 705972 bytes read:32827 seeks:1 nb_streams:1
[hevc @ 0x1f4aca0] nal_unit_type: 32(VPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f4aca0] Decoding VPS
[hevc @ 0x1f4aca0] Main profile bitstream
[hevc @ 0x1f4aca0] nal_unit_type: 33(SPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f4aca0] Decoding SPS
[hevc @ 0x1f4aca0] Main profile bitstream
[hevc @ 0x1f4aca0] Decoding VUI
[hevc @ 0x1f4aca0] nal_unit_type: 34(PPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f4aca0] Decoding PPS
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] All info found
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x1f49980] After avformat_find_stream_info() pos: 20299 bytes read:65595 seeks:2 frames:1
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from './Tears_400_x265.mp4':
Metadata:
major_brand : iso4
minor_version : 1
compatible_brands: iso4hvc1
creation_time : 2014-08-25T18:10:46.000000Z
Duration: 00:00:13.96, start: 0.125000, bitrate: 404 kb/s
Stream #0:0(und), 1, 1/24000: Video: hevc (Main) (hvc1 / 0x31637668), yuv420p(tv), 1920x800, 402 kb/s, 24 fps, 24 tbr, 24k tbn, 24 tbc (default)
Metadata:
creation_time : 2014-08-25T18:10:46.000000Z
handler_name : hevc:fps=24@GPAC0.5.1-DEV-rev4807
Successfully opened the file.
Parsing a group of options: output url ./out_img/ffmpeg-soft_x265_%d.jpg.
Applying option vf (set video filters) with argument fps=1.
Successfully parsed a group of options.
Opening an output file: ./out_img/ffmpeg-soft_x265_%d.jpg.
Successfully opened the file.
detected 2 logical cores
[hevc @ 0x1f61a00] nal_unit_type: 32(VPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f61a00] Decoding VPS
[hevc @ 0x1f61a00] Main profile bitstream
[hevc @ 0x1f61a00] nal_unit_type: 33(SPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f61a00] Decoding SPS
[hevc @ 0x1f61a00] Main profile bitstream
[hevc @ 0x1f61a00] Decoding VUI
[hevc @ 0x1f61a00] nal_unit_type: 34(PPS), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f61a00] Decoding PPS
Stream mapping:
Stream #0:0 -> #0:0 (hevc (native) -> mjpeg (native))
Press [q] to stop, [?] for help
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1f61a00] nal_unit_type: 39(SEI_PREFIX), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f61a00] nal_unit_type: 39(SEI_PREFIX), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f61a00] nal_unit_type: 19(IDR_W_RADL), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f61a00] Decoding SEI
[hevc @ 0x1f61a00] Skipped PREFIX SEI 5
[hevc @ 0x1f61a00] Decoding SEI
[hevc @ 0x1f61a00] Skipped PREFIX SEI 6
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1f7aba0] nal_unit_type: 1(TRAIL_R), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f884d0] nal_unit_type: 1(TRAIL_R), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f884d0] Output frame with POC 0.
[hevc @ 0x1f61a00] Decoded frame with POC 0.
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1f61a00] nal_unit_type: 0(TRAIL_N), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f61a00] Output frame with POC 1.
[hevc @ 0x1f7aba0] Decoded frame with POC 5.
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1f7aba0] nal_unit_type: 0(TRAIL_N), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f7aba0] Output frame with POC 2.
[hevc @ 0x1f884d0] Decoded frame with POC 3.
[Parsed_fps_0 @ 0x1f966c0] Setting 'fps' to value '1'
[Parsed_fps_0 @ 0x1f966c0] fps=1/1
[graph 0 input from stream 0:0 @ 0x1f96bb0] Setting 'video_size' to value '1920x800'
[graph 0 input from stream 0:0 @ 0x1f96bb0] Setting 'pix_fmt' to value '0'
[graph 0 input from stream 0:0 @ 0x1f96bb0] Setting 'time_base' to value '1/24000'
[graph 0 input from stream 0:0 @ 0x1f96bb0] Setting 'pixel_aspect' to value '0/1'
[graph 0 input from stream 0:0 @ 0x1f96bb0] Setting 'sws_param' to value 'flags=2'
[graph 0 input from stream 0:0 @ 0x1f96bb0] Setting 'frame_rate' to value '24/1'
[graph 0 input from stream 0:0 @ 0x1f96bb0] w:1920 h:800 pixfmt:yuv420p tb:1/24000 fr:24/1 sar:0/1 sws_param:flags=2
[format @ 0x1f96ad0] compat: called with args=[yuvj420p|yuvj422p|yuvj444p]
[format @ 0x1f96ad0] Setting 'pix_fmts' to value 'yuvj420p|yuvj422p|yuvj444p'
[hevc @ 0x1f61a00] Decoded frame with POC 1.
[hevc @ 0x1f7aba0] Decoded frame with POC 2.
[auto_scaler_0 @ 0x1f96350] Setting 'flags' to value 'bicubic'
[auto_scaler_0 @ 0x1f96350] w:iw h:ih flags:'bicubic' interl:0
[format @ 0x1f96ad0] auto-inserting filter 'auto_scaler_0' between the filter 'Parsed_fps_0' and the filter 'format'
[AVFilterGraph @ 0x1f962f0] query_formats: 4 queried, 2 merged, 1 already done, 0 delayed
[auto_scaler_0 @ 0x1f96350] picking yuvj420p out of 3 ref:yuv420p alpha:0
[swscaler @ 0x2153da0] deprecated pixel format used, make sure you did set range correctly
[auto_scaler_0 @ 0x1f96350] w:1920 h:800 fmt:yuv420p sar:0/1 -> w:1920 h:800 fmt:yuvj420p sar:0/1 flags:0x4
[mjpeg @ 0x1f5eba0] Forcing thread count to 1 for MJPEG encoding, use -thread_type slice or a constant quantizer if you want to use multiple cpu cores
[mjpeg @ 0x1f5eba0] intra_quant_bias = 96 inter_quant_bias = 0
Output #0, image2, to './out_img/ffmpeg-soft_x265_%d.jpg':
Metadata:
major_brand : iso4
minor_version : 1
compatible_brands: iso4hvc1
encoder : Lavf57.71.100
Stream #0:0(und), 0, 1/1: Video: mjpeg, yuvj420p(pc), 1920x800, q=2-31, 200 kb/s, 1 fps, 1 tbn, 1 tbc (default)
Metadata:
creation_time : 2014-08-25T18:10:46.000000Z
handler_name : hevc:fps=24@GPAC0.5.1-DEV-rev4807
encoder : Lavc57.89.100 mjpeg
Side data:
cpb: bitrate max/min/avg: 0/0/200000 buffer size: 0 vbv_delay: -1
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1f884d0] nal_unit_type: 0(TRAIL_N), nuh_layer_id: 0, temporal_id: 0
[hevc @ 0x1f884d0] Output frame with POC 3.
[Parsed_fps_0 @ 0x1f966c0] Dropping 1 frame(s).
frame= 0 fps=0.0 q=0.0 size=N/A time=00:00:00.00 bitrate=N/A speed= 0x
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[Parsed_fps_0 @ 0x1f966c0] Dropping 1 frame(s).
[hevc @ 0x1f61a00] nal_unit_type: 1(TRAIL_R), nuh_layer_id: 0, temporal_id: 0
cur_dts is invalid (this is harmless if it occurs once at the start per stream)
[hevc @ 0x1f61a00] Output frame with POC 4.
...
No more output streams to write to, finishing.
frame= 15 fps=0.5 q=24.8 Lsize=N/A time=00:00:15.00 bitrate=N/A speed=0.451x
video:1084kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
Input file #0 (./Tears_400_x265.mp4):
Input stream #0:0 (video): 335 packets read (701773 bytes); 335 frames decoded;
Total: 335 packets (701773 bytes) demuxed
Output file #0 (./out_img/ffmpeg-soft_x265_%d.jpg):
Output stream #0:0 (video): 15 frames encoded; 15 packets muxed (1109604 bytes);
Total: 15 packets (1109604 bytes) muxed
bench: utime=52.330s
335 frames successfully decoded, 0 decoding errors
bench: maxrss=72480kB
[Parsed_fps_0 @ 0x1f966c0] 335 frames in, 15 frames out; 320 frames dropped, 0 frames duplicated.
[AVIOContext @ 0x1f52220] Statistics: 734659 bytes read, 2 seeksВыводы
- MIPS SIMD является достаточно мощным инструментом повышения производительности и позволяет в разы сократить реальное время вычислений и соответствующим образом увеличить их скорость;
- оптимизация — это дорого в части трудозатрат разработчика. Реализация какого-либо алгоритма с использованием MIPS SIMD ближе к написанию ассемблерных вставок, нежели к высокоуровневому программированию. Что требует взвешенного подхода при принятии решений о переработке кода;
- Байкал-Т1 — это не вымысел маркетологов, он существует, работает, под него вполне спокойно была собрана последняя версия достаточно сложного программного пакета и она на нем без проблем запустилась.
Ссылки
[L1] — Процессор Байкал-Т1;
[L2] — Проект MIPSfpga-plus на github;
[L3] — P-Class P5600 Multiprocessor Core;
[L4] — Добавляем инструкции в микропроцессор MIPS, которые работают в конвейере как его собственные;
[L5] — Texas Instruments. Digital Signal Processors;
[L6] — Альтернативное использование мощностей GPU;
[L7] — OpenCL. Что это такое и зачем он нужен;
[L8] — Wikipedia: Фильтр с конечной импульсной характеристикой;
[L9] — TFilter. Free online FIR filter design tool;
[L10] — Wikipedia: Цифровой сигнальный процессор;
[L11] — Wikipedia: Полосно-заграждающий фильтр;
[L12] — Wikipedia: Амплитудно-частотная характеристика;
[L13] — Wikipedia: SIMD;
[L14] — Wikipedia: Векторный процессор;
[L15] — MIPS SIMD;
[L16] — GCC: MIPS SIMD Architecture (MSA) Support;
[L17] — GCC: MIPS SIMD Architecture Built-in Functions;
[L18] — Проект ffmpeg на github (каталог libavcodec/mips/);
[L19] — FFmpeg multimedia framework;
[L20] — Codescape MIPS SDK;
[L21] — H.264 Demo Clips;
[L22] — x256. Sample HEVC Video Files;
[L23] — Логи работы ffmpeg
[L24] — Материалы семинара Специализированные интегральные схемы наноуровня;
Документация
[D1] — Титце У., Шенк К. — Полупроводниковая схемотехника;
[D2] — MIPS Architecture for Programmers Volume IV-j: The MIPS32 SIMD Architecture Module;
[D3] — MIPS SIMD programming. Optimizing multimedia codecs;
Изображения и таблицы
[P1] — Блок-схема Байкал-Т1. (Источник: L1);
[P2] — TFilter. Пример настройки режекторного фильтра 1 (скриншот);
[P3] — TFilter. АЧХ режекторного фильтра 1;
[P4] — TFilter. Пример настройки режекторного фильтра 2 (скриншот);
[P5] — TFilter. АЧХ режекторного фильтра 2;
[P6] — Сравнение традиционного подхода и SIMD-реализации фильтра (Источник: D3);
[P7] — MSA Vector registers (Источник: D2);
[P8] — MADDV Operation description (Источник: D2);
Автор: SparF






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}