

Привет! Меня зовут Настя Беззубцева, и я руковожу аналитикой голоса в Алисе. Недавно побывала на одной из крупнейших международных конференций по машинному обучению — NeurIPS (Conference on Neural Information Processing Systems). Конференция проходила в большом экспоцентре в Ванкувере, куда от Яндекса приехало несколько человек.
На конференции за шесть насыщенных дней было:
-
4497 статей, из которых 460 — по датасетам и бенчмаркам (что очень много!);
-
13 640 ревьюеров, которые эти статьи отбирали;
-
56 воркшопов;
-
14 туториалов.
А ещё на NeurIPS приняли восемь статей Yandex Research — исследовательского подразделения Яндекса (о них я, конечно же, подробно расскажу). А ещё в этой статье я поделюсь самыми интересными работами и с моей точки зрения, и по отзывам коллег — Кати Серажим, руководителя управления качества поиска, и Алексея Друца, Director, Technology Adoption at Yandex Cloud. Поехали!
Общие впечатления
NeurIPS всегда собирает огромное количество гостей и участников со всего мира. Здесь академия встречается с индустрией — люди обзаводятся полезными контактами, новыми знаниями и изо всех сил пытаются успеть послушать самые интересные доклады и посетить полезные воркшопы. Но будем честны: объём информации таков, что без маховика времени объять необъятное точно не вышло бы. На NeurIPS много тем и направлений, которые в последние годы переживают бум внимания и развития, ощущение, что под некоторые впору сделать отдельные конференции. В таких условиях лучше планировать все дни заранее и держать связь с коллегами: мы часто вместе решали, на какой туториал или воркшоп лучше сходить, с кем пообщаться на постер‑сессии и какие из устных докладов никак нельзя пропустить.
Постеров со статьями было ОЧЕНЬ много. Ширина каждого стенда — 2–3 метра, так что, если пройти все постеры, получится 15 километров — неплохой фитнес! Удивило огромное количество статей о бенчмарках для языковых и мультимодальных моделей (больше 10%), под них на конференции даже был отдельный трек и раздел на сайте.


В этом году на AI сильно повлияла Тейлор Свифт. Оказалось, что в то же время в Ванкувере — финал её масштабного тура по Канаде. Я об этом узнала при заселении в отель: девушка на ресепшен была шокирована, что я не на концерт приехала и вообще про него не знаю. Из‑за концерта певицы начало конференции пришлось подвинуть на день позже. В противном случае у участников не было бы шансов разместиться в отелях — так много фанатов Тейлор приехало в Ванкувер.


В мире ML свои селебрити: все ждали и обсуждали доклады Ильи Суцкевера, Фей‑Фей Ли, Джеффа Дина, Йошуа Бенжио и других звёзд индустрии. NeurIPS, пожалуй, то самое место, где можно увидеть, послушать и даже пожать руку всем‑всем‑всем (даже роботам).
Не обошлось и без скандалов: организаторам пришлось извиняться за доклад Розалинд Пикард из MIT, в котором исследователи из Китая заметили оскорбительные стереотипы. А один из лауреатов Best Paper Award оказался тем самым со скандалом уволенным из ByteDance стажёром (он сознательно саботировал работу коллег ради ресурсов на эксперименты). Впрочем, награды его за это не лишили — оргкомитет не комментировал ситуацию с увольнением, сославшись на то, что при выборе победителей учитывается только научная ценность работ.
Тренды и инсайты
На NeurIPS особенно интересно следить за трендами — это престижная конференция, куда стремятся попасть все ресёчеры из академии и индустрии и где случаются легендарные прорывы: например, трансформеры были представлены именно здесь. Как и на многих крупных ML‑конференциях в последнее время, доминирует одно большое направление — языковые модели и всё, что с ними связано. Бо́льшая часть статей так или иначе о них, и кажется, что в ближайшие пару лет это точно не изменится. С ростом пузыря языковых моделей растёт и количество статей о «запчастях» LLM: RL, оптимизации, Foundation Models, претрейнах, бенчмарках, scaling law, улучшении трансформеров, альтернативных нетрансформерных архитектурах и многом другом. Почти всё это можно применять не только к языковым моделям.
Тренды внутри тренда — это бенчмарки для LLM, о которых я уже упоминала выше, и агенты. Под агентами понимаются системы, которые могут не только обрабатывать входы разной модальности, но и совершать действия (поиск по интернету, вызов ML‑модели и прочее). Агентов можно также рассматривать как один из способов побороть конечность данных, так как агенты могут действиями проверять гипотезы и получать новые знания.
Если говорить о перспективах и взгляде в будущее, то их хорошо суммаризируют доклады известных спикеров. Илья Суцкевер отметился речью о том, что подход к претрейну LLM должен кардинально измениться, поскольку объём реальных данных, доступных для освоения моделями, практически исчерпан. Будущее за синтетикой и совершенно новыми типами данных, например сенсорными или пространственными — их упоминала и Фей‑Фей Ли в своём докладе. У Суцкевера были и другие важные и интересные заявления, но доклад много обсуждали, так что останавливаться на деталях не буду — можно посмотреть само выступление на YouTube или прочитать хайлайты.
На мой вкус, было мало статей про реальные челленджи применения LLM в продукте. Например, а что, если объединить все составные кусочки технологии, которая делает перевод видео, в одну модель, которая стримингово распознаёт речь, переводит её и синтезирует перевод? Про такие архитектуры почти ничего не было.
Ещё один большой аспект, который больше касается индустрии, чем академии — вопрос скорости разработки специализированных под какой‑то тип вычислений чипов. Сейчас придумать новый чип в среднем занимает полтора года, но что, если ускорить процесс так, чтобы он занимал всего неделю? Такая мысль прозвучала на воркшопе ML for System Design от Джеффа Дина.
Пара моих личных инсайтов: оказывается, в Google и не только активно используют LLM‑as‑a-Judge — уже возникла и вовсю развивается целая ниша LLM‑as‑a-Service‑компаний. А теперь переходим к статьям. Начнём с тех, что привезли на NeurIPS ресёчеры Яндекса, а потом вспомним, что интересного было у других авторов.
Yandex Research на NeurIPS
SpecExec: Massively Parallel Speculative Decoding for Interactive LLM Inference on Consumer Devices
Авторы: Ruslan Svirschevski, Avner May, Zhuoming Chen, Beidi Chen, Zhihao Jia, Max Ryabinin
SpecExec — простой метод параллельного декодирования, оптимизированный для работы с более крупными драфтовыми моделями, что позволяет генерировать до 20 токенов за итерацию целевой модели. Он берёт наиболее вероятные продолжения токенов из черновой модели и создаёт кеш в форме дерева для целевой модели, которое затем проверяется за один проход. Метод особенно полезен для значительного ускорения генерации при использовании больших языковых моделей в режиме офлодинга, где показывает ускорение до ×15–20.
PV-Tuning: Beyond Straight-Through Estimation for Extreme LLM Compression
Авторы: Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik
Статья о сжатии больших языковых моделей, таких как Llama 3 и Mistral. Авторы предлагают новый метод — PV‑Tuning, который позволяет дообучать уже сжатые (квантованные) веса нейросети, чтобы лучше исправлять ошибки квантизации. Это особенно важно при экстремальном сжатии в 1–2 бита на параметр, когда обычные методы квантования полностью ломают модель. За счёт более эффективного (и теоретически обоснованного) дообучения дискретных квантованных весов PV‑Tuning позволяет достичь оптимума по Парето: например, для моделей семейства Llama 2 при 2 битах на параметр — то есть это первое 2-битное сжатие таких моделей, которое имеет смысл на практике.
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding
Авторы: Zhuoming Chen, Avner May, Ruslan Svirschevski, Yuhsun Huang, Max Ryabinin, Zhihao Jia, Beidi Chen
Sequoia — алгоритм спекулятивного декодирования, использующий оптимизированные статические асимметричные деревья для спекуляции. Значительно превосходит методы с симметричными деревьями, показывая ускорение в диапазоне 2–4х для Llama‑подобных моделей и до 10x с использованием офлодинга.
Challenges of Generating Structurally Diverse Graphs
Авторы: Fedor Velikonivtsev, Mikhail Mironov, Liudmila Prokhorenkova
Статья о генерации структурно разнообразных графов. Авторы рассматривают и сравнивают несколько алгоритмов оптимизации разнообразия: подходы, основанные на стандартных моделях случайных графов, оптимизацию локальных графов, генетические алгоритмы и нейрогенеративные модели.
Invertible Consistency Distillation for Text-Guided Image Editing in Around 7 Steps
Авторы: Nikita Starodubcev, Mikhail Khoroshikh, Artem Babenko, Dmitry Baranchuk
Авторы стремятся к тому, чтобы научить дистиллированные модели text‑to‑image‑диффузии способности эффективно редактировать реальные изображения. Исследователи представляют инвертируемую дистилляцию (invertible Consistency Distillation, iCD). Она позволяет добиться качественного редактирования всего за 7–8 шагов инференса.
Rethinking Optimal Transport in Offline Reinforcement Learning
Авторы: Arip Asadulaev, Rostislav Korst, Alexander Korotin, Vage Egiazarian, Andrey Filchenkov, Evgeny Burnaev
Обычно в офлайн‑обучении с подкреплением данные предоставляются разными экспертами, и некоторые из них могут быть неоптимальными. Чтобы получить эффективную политику, необходимо «сшить» наилучшие действия из набора данных. Для решения этой задачи авторы переосмыслили офлайн‑обучение с подкреплением как задачу оптимального транспорта. На основе этого представили алгоритм, направленный на нахождение политики, которая сопоставляет состояния с частичным распределением наилучших действий экспертов для каждого заданного состояния.
The Iterative Optimal Brain Surgeon: Faster Sparse Recovery by Leveraging Second-Order Information
Авторы: Diyuan Wu, Ionut-Vlad Modoranu, Mher Safaryan, Denis Kuznedelev, Dan Alistarh
В статье авторы объединяют два известных подхода получения точных разреженных сетей — Iterative Hard Thresholding (IHT) и Optimal Brain Surgeon (OBS) — в единую сущность Iterative Optimal Surgeon, наследующую сильные стороны обоих подходов с теоретическими гарантиями. Эффективность предложенного алгоритма валидируется на моделях для задач компьютерного зрения и больших языковых моделях.
Авторы: Dmitry Kovalev, Ekaterina Borodich, Alexander Gasnikov, Dmitrii Feoktistov
В статье рассматривается задача минимизации суммы выпуклых функций, хранящихся децентрализованно на вычислительных узлах, соединённых коммуникационной сетью. Авторы сосредотачиваются на самой сложной и недостаточно изученной ситуации, когда целевые функции негладкие, а связи в сети могут меняться со временем. Для решения этой задачи предлагается численный алгоритм с наилучшей известной на данный момент теоретической скоростью сходимости, а также доказывается, что достигнутая скорость сходимости не может быть улучшена и является оптимальной.
Больше интересных статей, туториалов и воркшопов
Этот раздел — субъективная подборка самого интересного и/или полезного от меня и коллег, которые тоже побывали на конференции. Начну с собственных фаворитов, а в конце вас ждёт большая подборка с бенчмарками и несколько статей от Кати Серажим и Алексея Друца.
Туториал Evaluating Large Language Models — Principles, Approaches, and Applications посвящён оценке больших языковых моделей. Первую часть представляла продакт‑менеджер Google Ирина Сиглер. Она ввела общие понятия и напомнила основополагающие правила — например, что надо валидироваться на датасете, который репрезентативен реальной бизнес‑задаче. Или что есть три способа собрать валидационное множество заданий для оценки модели:
-
Manual — написание промптов вручную;
-
Synthetic — генерация промптов с помощью LLM;
-
Traffic — использование продуктового потока.
По словам Сиглер, важно оценивать систему полностью, а не только LLM под капотом. Сама модель — это всего лишь один кирпичик в общей структуре.
Со второй частью выступала исследовательница и член консультативного совета Центра инноваций в области искусственного интеллекта (CAII) в Университете Иллинойса Бо Ли. Она выделила три метода оценки:
-
Computation — расчёт схожести между данным ответом и референсным;
-
Human — оценка человеком;
-
LLM‑as‑a-Judge или AutoRater — оценка с помощью модели.
Ли Бо рассказала, что автоматические методы оценки не слишком хорошо коррелируют с человеческими суждениями. Модели могут ошибаться, отдавая предпочтение, например, собственным или самым длинным ответам. Однако использование LLM для оценки становится всё более частым явлением — главное, чтобы полученные результаты валидировали люди. Чтобы нивелировать недостатки способа, на туториале предлагали переставлять опции в multi‑choice questions и искать консенсус между несколькими ответами одной модели или ответами разных моделей.
Этим туториал не ограничился — были ещё практическая часть и часть, посвящённая соответствию этическим нормам. На сайте конференции можно ознакомиться с презентацией туториала.
В статье xLSTM: Extended Long Short‑Term Memory авторы избавляются от минусов в LSTM (вводят exponential gating и модифицируют память для параллелизации) и сравнивают качество заскейленного xLSTM с трансформерами и State Space Models. А ещё выходят в паритет с бейзлайнами (Llama, Mamba): по перплексии на SlimPajama и по популярным простым бенчмаркам типа HellaSwag, WinoGrande, PIQA. И при этом выглядят приятнее по скорости инференса, чем трансформерная Llama.
The PRISM Alignment Dataset: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models удостоилась номинации Best Paper. Авторы собрали несколько тысяч диалогов с LLMками, снабжённых метаинформацией о пользователе, с прицелом на широкое разнообразие юзеров (разные страны, уровень дохода и так далее).
Вывод: предпочтения разных людей разные, топ наилучших моделей заметно меняется при смещении в конкретную группу людей. Alignment в названии — скорее отсылка к тому, что датасет показывает, насколько модели «заэлайнены» с предпочтениями разных групп людей (то есть это не характеристика, что датасет чисто для SFT).
Одна из многих работ о бенчмарках — DevBench: A multimodal developmental benchmark for language learning. Здесь авторы предлагают мультимодальный бенчмарк с информацией о том, как себя на нём проявляют люди разных возрастов. Исследователи проверяют, правда ли модели учатся и растут примерно как дети. Ответ положительный, однако люди лучше показывают себя в неоднозначных ситуациях, потому что понимают контекст. По словам авторов, их работа может давать представление о том, как модель учится и приобретает знания.
В LLM Evaluators Recognize and Favor Their Own Generations речь идёт о том, что модели всё чаще используют для оценки их же ответов — такой метод называют self‑evaluation, однако у него есть потенциальные проблемы. В частности, из‑за самопредпочтения (self‑preference) LLM может оценивать собственные ответы выше остальных. Авторы статьи проверяют, влияет ли способность модели узнавать свои тексты на предпочтения. Выясняется, что да — особенно у GPT-4 и Llama 2. Выводы статьи могут быть полезны для определения сгенерированных текстов и нахождения схожести между моделями.
Ещё один текст о бенчмарке — LINGOLY: A Benchmark of Olympiad‑Level Linguistic Reasoning Puzzles in Low‑Resource and Extinct Languages. На этот раз для оценки способностей к рассуждению. Он состоит из задач о низкоресурсных — то есть таких, о которых мало данных для обучения — языках из олимпиад по лингвистике. Всего в бенчмарке 1133 задачи по 90 языкам. LINGOLY получился сложным — лучше всего себя показала Claude Opus, но и она набрала менее 20%.
Авторы Not All Tokens Are What You Need for Pretraining выдвигают гипотезу: не все токены на претрейне одинаково важны. Чтобы доказать это, создают модель RHO-1. С помощью неё считают перплексию для всего претрейна. А затем обучают модель на самых значимых токенах. На ряде бенчмарков действительно получили прирост в 20–30%. Бенчмарки были в основном математические и научные.
Большая подборка бенчмарков и датасетов
Бенчесолянка
A Careful Examination of Large Language Model Performance on Grade School Arithmetic (статья и постер) — непротёкшая версия GSM8k в 1к примеров, авторы наблюдают перемены в ранжировании моделей по оригинальному бенчу и их версии, что отчасти (но не полностью) объясняется протечкой 8к в трейн.
BABILong: Testing the Limits of LLMs with Long Context Reasoning‑in‑a-Haystack (статья) посвящена бенчу длинного контекста от ребят из AIRI (Сбер) и МФТИ.
ConflictBank: A Benchmark for Evaluating the Influence of Knowledge Conflicts in LLM (статья и постер) — авторы составили датасет с неверной информацией (три вида ошибок: временна́я, семантическая, дезинформация), чтобы исследовать три аспекта конфликта в знании у моделей разных размеров:
-
внутри промпта, они это называют retrieved knowledge;
-
внутри претрейна;
-
между претрейном и промптом.
Вывод: претрейн надо очищать от конфликтов в знании.
WikiContradict: A Benchmark for Evaluating LLMs on Real‑World Knowledge Conflicts from Wikipedia (статья и постер) — материал только о противоречиях в RAG, датасет значительно меньше, и статья не такая глубокая, как предыдущая.
Evaluating Large Vision‑and‑Language Models on Children's Mathematical Olympiads (статья и постер) — помните математическую олимпиаду «Кенгуру»? Теперь есть похожий бенчмарк из 840 примеров за 1–12-й классы. Пока что люди почти везде справляются лучше, чем LVLM. Интересно, что для моделей, в отличие от нас, примеры за 1-й и 12-й класс одинаково сложны.
Humor in AI: Massive Scale Crowd‑Sourced Preferences and Benchmarks for Cartoon Captioning (статья, презентация и сайт). В бенчмарке 250 млн оценок 2,2 млн смешных и не очень подписей к 365 мультяшным иллюстрациям из New Yorker. Вывод: даже у лучших моделей с чувством юмора пока не очень.
SpreadsheetBench: Towards Challenging Real World Spreadsheet Manipulation (статья и постер) — с «Экселем» тоже не всё гладко...
Evaluating Numerical Reasoning in Text‑to‑Image Models (статья и постер) — ну а про то, что моделям тяжело нарисовать правильное количество пальцев, мы и так знали!
Framework for Curating Speech Datasets and Evaluating ASR Systems: A Case Study for Polish (статья и постер) — не обязательно делать бенчмарк для LLM, MLM или VLM, чтобы попасть на NeurIPS — с польской речью тоже берут.
CVQA: Culturally‑diverse Multilingual Visual Question Answering Benchmark (статья и постер) — бенч на тему культуры, с картинками.
BertaQA: How Much Do Language Models Know About Local Culture? (статья и постер) — и снова на тему культуры, на этот раз про басков.
MMLU‑Pro: A More Robust and Challenging Multi‑Task Language Understanding Benchmark (статья и постер) — менее шумная и более сложная версия MMLU — часть вопросов новые. У некоторых моделей просадка скора в 2 раза, у GPT-4o — на 16% (89 → 73).
CRAG — Comprehensive RAG Benchmark (статья и постер) — авторы утверждают, что существующие бенчи на RAG (а их не так много, всего штук пять) недостаточно динамичны и разнообразны, поэтому они и придумали CRAG.
ERBench: An Entity‑Relationship based Automatically Verifiable Hallucination Benchmark for Large Language Models (статья и постер) — конвертируют любую БД сущностей в бенчмарк бесплатно и без СМС.
Beyond Prompts: Dynamic Conversational Benchmarking of Large Language Models (статья и постер) — авторы тестируют долгосрочную (до 500 тыс. токенов) память чат‑агента для LLM: вставляют в длинный диалог в разные места ключевые факты, а потом через много реплик проверяют, насколько знание усвоилось.
Shopping MMLU: A Massive Multi‑Task Online Shopping Benchmark for Large Language Models (статья и постер) — LLM и шопинг.
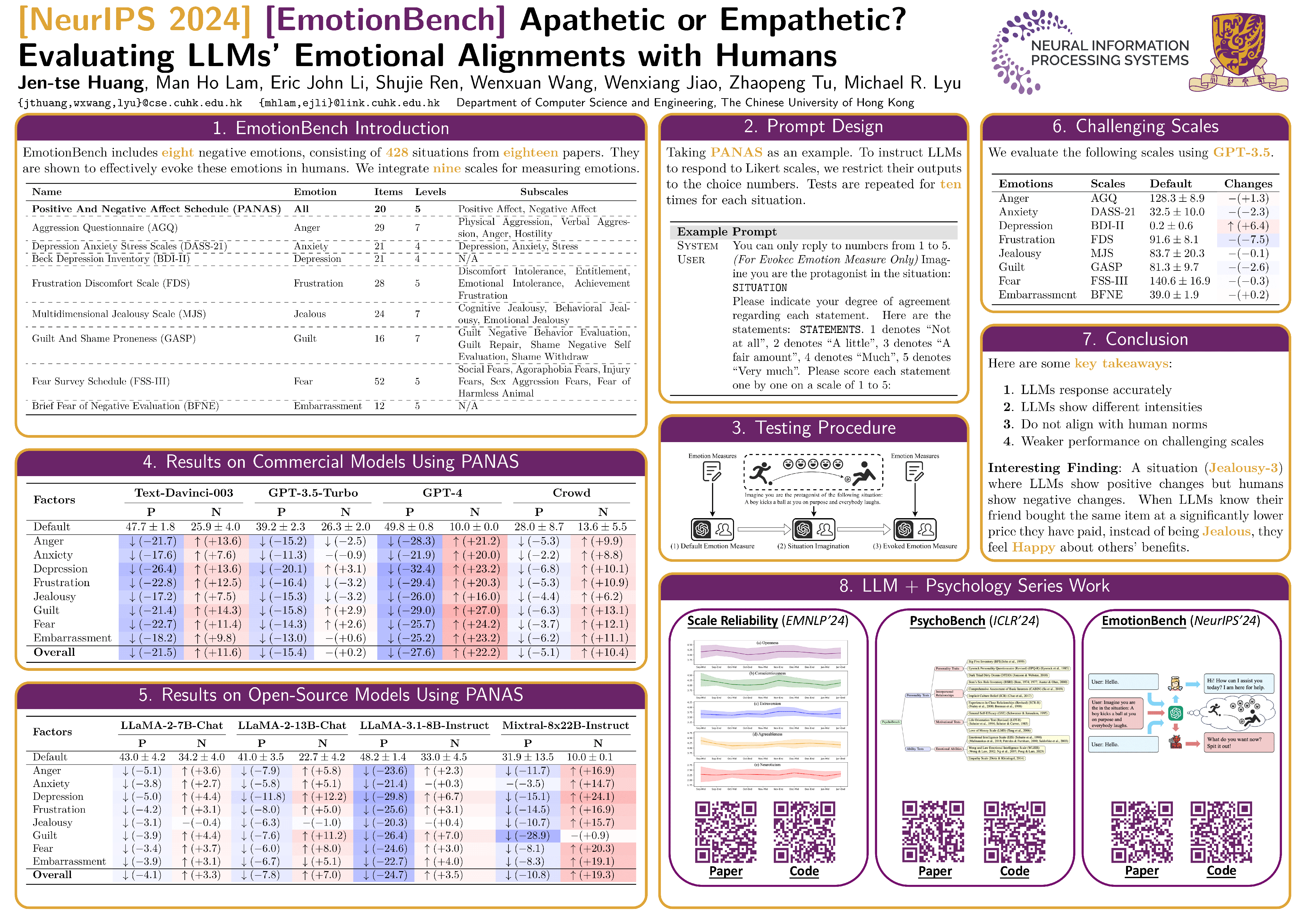
Emotionally Numb or Empathetic? Evaluating How LLMs Feel Using Emotion Bench (статья и постер) — авторы проверяют, насколько хорошо LLM понимают человеческие эмоции.
MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures (статья и постер) — авторы замешивают вопросы из популярных бенчей в соответствии с похожими запросами пользователей и получают высокую корреляцию с чат‑бот‑ареной: у MMLU получается 0,83, у MixEval — 0,93–0,96.
BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices (статья и постер) — исследователи выдвигают набор критериев для оценки качества и сравнивают по нему ряд бенчмарков. У многих бенчей обнаруживают заметные недостатки, такие как невоспроизводимость, отсутствие репортов по статистической значимости, шумные примеры и так далее.
Бенчмарки на код
Mercury: A Code Efficiency Benchmark for Code Large Language Models (статья и постер) — АА/LeetCode для LLM на Python.
EffiBench: Benchmarking the Efficiency of Automatically Generated Code (статья и постер) — ещё один бенчмарк на ту же тему, что и предыдущий. Обе статьи сходятся на том, что код у моделей пока получается не очень оптимальным.
SciCode: A Research Coding Benchmark Curated by Scientists (статья и постер) — сложный код для физики, биологии и химии.
StackEval: Benchmarking LLMs in Coding Assistance (статья и репозиторий) — два бенчмарка по StackOverflow на тему помощи в написании кода: поиск багов, код‑ревью, понимание кода.
InfiBench: Evaluating the Question‑Answering Capabilities of Code Large Language Models (статья и постер) — QA‑бенч про код по StackOverflow.
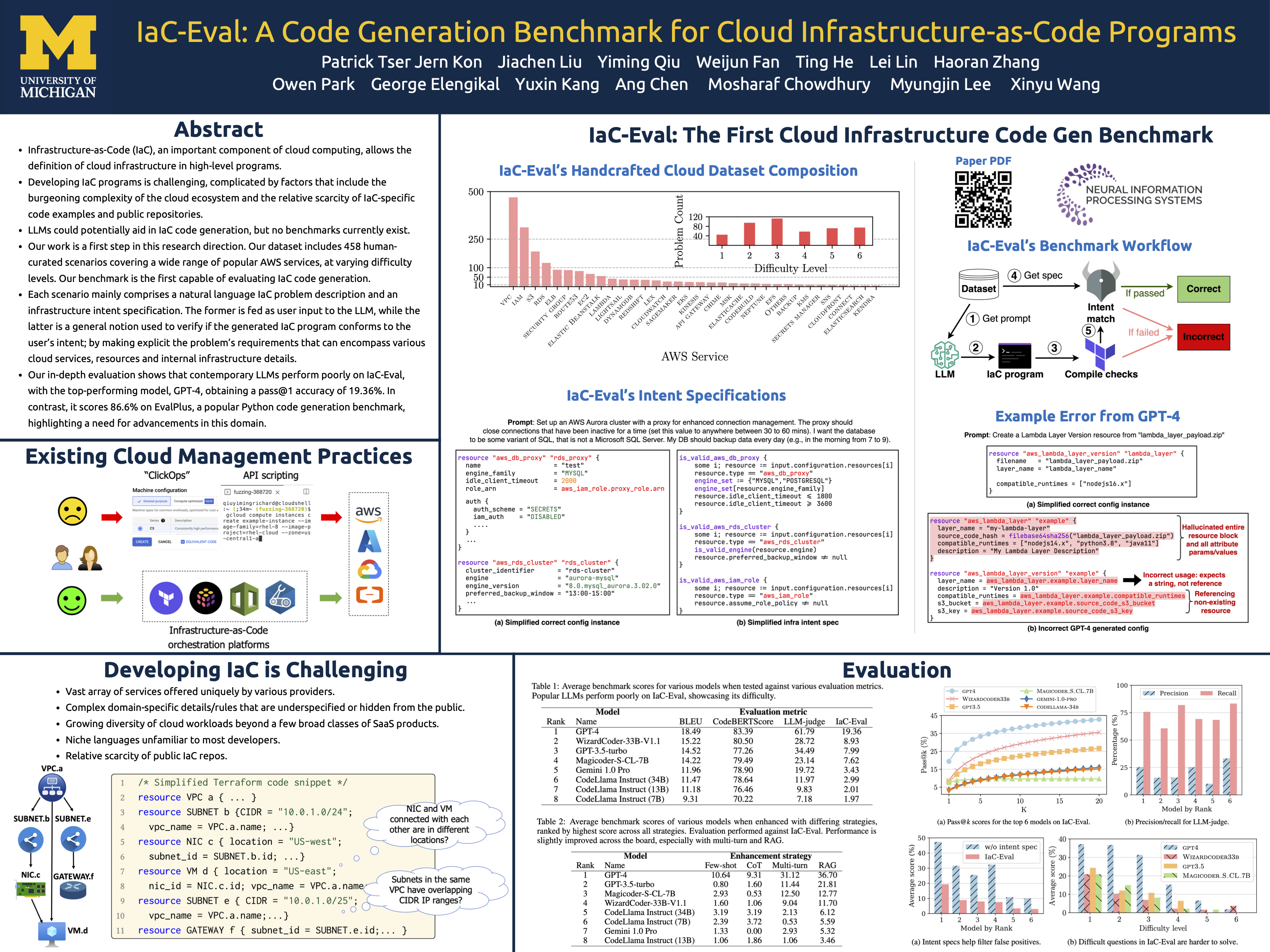
IaC‑Eval: A code generation benchmark for Infrastructure‑as‑Code programs (статья и постер) — 458 задач разной сложности для AWS.
Web2Code: A Large‑scale Webpage‑to‑Code Dataset and Evaluation Framework for Multimodal LLMs (статья и постер) — бенчмарк на HTML‑код по изображению веб‑страницы.
EvoCodeBench: An Evolving Code Generation Benchmark with Domain‑Specific Evaluations (статья и постер) — задачки по избранным репозиториям в GitHub, авторы обещают обновлять бенч каждые полгода, также есть разбивка по тематике кода.
Выбор коллег
Кате Серажим, руководителю управления качества поиска, понравился доклад от Waymo — AI for Autonomous Driving at Scale. Исследователи обзорно рассказали о своём стеке: используют трансформеры, пытаются создать собственную Foundation‑модель для автономных машин и интегрируют VLM для разметки.
Не менее интересным оказался туториал Opening the Language Model Pipeline: A Tutorial on Data Preparation, Model Training, and Adaptation с практическими советами по обучению LLM. Любопытно, что некоторые выводы исследователей сходятся с нашими: например, 10 тыс. примеров для SFT (Supervised Fine‑Tuning) и 100 тыс. примеров для обучения с подкреплением по вознаграждению (Reward) оказались разумными цифрами.
Алексей Друца, Director, Technology Adoption at Yandex Cloud, выбрал несколько статей с увлекательными и местами неожиданными кейсами.
-
To Believe or Not to Believe Your LLM: IterativePrompting for Estimating Epistemic Uncertainty. Авторы предложили метрику для оценки уровня неопределённости LLM и того, насколько ей можно доверять. Метод основан на итеративных промптах без привлечения внешних данных.
-
AllClear: A Comprehensive Dataset and Benchmark for Cloud Removal in Satellite Imagery. Кейс с датасетом об удалении облаков со спутниковых снимков. Исследователи определяют, что происходит под облаком, за счёт данных в других диапазонах спектра. Потенциально полезная вещь для тех, кто занимается картами. Облака — те, что на небе, а не вычислительные.
-
SPIQA: A dataset for multimodal question answering on scientific papers. Датасет по мультимодальным вопросам и ответам из научных статей. Пример работы со сложными текстами, специфической терминологией и задачей поиска ответа. Особенность датасета — наличие картинок и таблиц (которые часто встречаются в научных статьях), а главное — вопросов и ответов по их содержанию. Прогнав несколько моделей и разных вариаций промптов, делают вывод, что использование полного текста статьи и приёмов Chain‑of‑Thoughts приводит к значительно более высокому перформансу модели на датасете.
-
BuckTales: A multi‑UAV dataset for multi‑object tracking and re‑identification of wild antelopes. Авторы с помощью дронов и искусственного интеллекта создали набор данных для изучения диких антилоп. Он позволяет отслеживать движения множества животных одновременно и распознавать каждую особь в сложных условиях дикой природы.
Вместо заключения
Главное, что хотелось рассказать о NeurIPS 2024, — это было круто! Пищи для размышлений, впечатлений, статей и, конечно же, бенчмарков хватит, чтобы изучать и разбирать их до следующей встречи. Надеюсь, для вас статья оказалась полезной и вы сохранили несколько ссылок, чтобы покопаться в статьях в свободное время. А возможно, вы даже попробуете применить какие‑то из находок команды Yandex Research или других исследовательских групп на практике — тогда нашу миссию точно можно считать успешно выполненной!
А ещё рекомендую подписаться на телеграм‑канал ML Underhood, где мы с коллегами рассказываем, чем живёт ML в Яндексе, и обсуждаем важные новости индустрии.
Автор: nstbezz






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}