

Фото Florencia Viadana, Unsplash.com
После почти пятилетних разработок протокол HTTP/3 наконец приближается к окончательному выпуску. Предыдущие итерации уже доступны как экспериментальная функция, но в 2021 году мы ждём широкого распространения протокола. Что такое HTTP/3? Зачем выпускать его так рано после HTTP/2? Как его можно или нужно использовать? Как он влияет на производительность?
Вы, скорее всего, читали статьи или слушали выступления по этой теме и думаете, что уже всё знаете. Наверное, вы слышали что-то вроде: «HTTP/3 гораздо быстрее, чем HTTP/2, при потере пакетов» или «У HTTP/3-соединений меньше задержка и нужно меньше времени на установку соединения». И ещё, пожалуй: «HTTP/3 отправляет данные быстрее и может передавать больше ресурсов параллельно».
Все эти заявления и статьи упускают некоторые важные технические детали и нюансы и обычно верны только отчасти. Создается впечатление, будто HTTP/3 произведёт революцию в производительности. Я бы назвал это скорее эволюцией (не умаляя достоинств нового протокола). Беда в том, что на практике он вряд ли оправдает возложенные на него ожидания. Думаю, многие будут разочарованы, а новички и вовсе запутаются в этой мешанине слепо повторяемых заблуждений.
Во всяком случае, с HTTP/2 так и было. Мы ждали настоящего чуда, невероятных новых фич — server-push, параллельные потоки, приоритизация… Больше не нужно будет группировать сайты, балансировать нагрузку между несколькими бэкендами и старательно оптимизировать процесс загрузки страницы. По мановению волшебной палочки сайты разгонятся в полтора раза!
Прошло пять лет и теперь мы знаем, что server-push нестабилен в продакшене, потоки и приоритизация обычно реализованы не лучшим образом, а значит объединение ресурсов и даже шардинг по-прежнему вовсю используются в некоторых ситуациях (но реже).
Другие механизмы, например, preload hint, часто ведут себя не так, как ожидается и имеют баги, отчего их сложно правильно использовать.
В общем, предлагаю избавиться от заблуждений и завышенных ожиданий по поводу HTTP/3.
В этой серии статей мы подробно поговорим о новом протоколе, особенно о его характеристиках производительности. Мы увидим, что, хотя HTTP/3 и содержит перспективные новые концепции, к сожалению, большинство веб-страниц и пользователей ничего не заметят (хотя некоторым из них он принесёт много пользы). HTTP/3 довольно сложно правильно настроить и использовать, так что будьте особенно внимательно при конфигурировании.
Серия разделена на три части:
- История и ключевые концепции HTTP/3
Эта часть для тех, кто в целом мало что знает об HTTP/3 и протоколах. Здесь мы будем говорить о самых основах. - Характеристики производительности HTTP/3
Тут мы углубимся в технические детали. Если с основами вы уже знакомы, начинайте со второй части. - Развёртывание HTTP/3 на практике
Здесь описываются трудности, связанные с самостоятельным развёртыванием и тестированием HTTP/3. Мы поговорим, как нужно изменить веб-страницы и ресурсы и нужно ли вообще.
Эта серия статей предназначена для веб-разработчиков, которые не знают всех тонкостей протоколов, но хотели бы. При этом здесь достаточно технических деталей и ссылок на внешние ресурсы, чтобы заинтересовать даже продвинутых.
Зачем нам HTTP/3?
Я часто слышу вопрос: «Зачем выпускать HTTP/3 почти сразу после HTTP/2, который был стандартизирован в 2015?» Выглядит и правда странно, если не знать, что нам скорее был нужен апгрейд для TCP, нежели новая версия HTTP.
TCP — это основной протокол, который отвечает за важные функции, например, надёжность и доставка по порядку, для других протоколов, вроде HTTP. Благодаря ему, в том числе, в интернете может быть столько одновременных пользователей — благодаря внутренним механизмам балансировки полосы пропускания между пользователями, он распределяет её «по справедливости».
А вы знали?
Когда вы используете HTTP(S), на самом деле вы используете несколько протоколов, кроме HTTP, и у каждого протокола в стеке свои функции и обязанности (см. схему ниже). Например, HTTP занимается URL и интерпретацией данных, TLS отвечает за безопасность, обеспечивая шифрование, TCP обеспечивает надёжную передачу данных, повторно отправляя потерянные пакеты, а IP направляет пакеты из одной конечной точки в другую по промежуточным устройствам.
Такая слоистая структура позволяет повторно использовать функции каждого протокола по отдельности. Протоколы на более высоком уровне (например HTTP) не должны сами реализовывать некоторые сложные функции (вроде шифрования), потому что этим занимаются протоколы ниже (например TLS). Ещё один пример: большинство приложений в интернете используют TCP, чтобы гарантировать полную передачу всех данных. Поэтому TCP — один из самых распространённых протоколов в интернете.

Стеки для HTTP/2 и HTTP/3 (исходное изображение)
Десятилетиями весь интернет держался на TCP, но он начал устаревать ещё в конце 2000-х. Его предполагаемая замена, новый транспортный протокол под названием QUIC, настолько отличается от TCP по ключевым пунктам, что просто использовать поверх него HTTP/2 было бы очень сложно. Поэтому сам по себе HTTP/3 — это относительно незначительное изменение HTTP/2 для адаптации к новому протоколу QUIC. Вот он-то как раз и содержит те фичи, которые всех приводят в восторг.
TCP, который мы использовали с первых дней интернета, изначально был создан не на максимуме эффективности, поэтому нам и стал нужен QUIC. Например, TCP требует рукопожатие для установки нового соединения, чтобы проверить, что клиент и сервер существуют и готовы обмениваться данными. Нужно сделать полный круговой путь по сети, прежде чем можно будет делать что-то ещё. Если клиент и сервер находятся далеко, время кругового пути (round-trip time, RTT) может составить более 100 мс, что приводит к ощутимым задержкам.
Второй пример: TCP видит все данные, которые передает, как один «файл», или поток байтов, даже если мы передаем несколько файлов одновременно (например, загружаем страницу с несколькими ресурсами). На практике это означает, что, если пакеты TCP с данными одного файла теряются, все остальные файлы будут ждать восстановления этих пакетов.
Это так называемая блокировка начала очереди — head-of-line (HoL) blocking. На практике с этими недостатками можно бороться (иначе зачем бы мы мучились с TCP целых 30 с лишним лет), но они серьезно влияют на протоколы верхнего уровня, например, HTTP.
Мы пытались развивать и обновлять TCP, чтобы решить некоторые проблемы и даже реализовать новые функции для повышения производительности. Например, TCP Fast Open устраняет издержки рукопожатия, позволяя протоколам с верхнего уровня отправлять данные с самого начала. Ещё одно решение — MultiPath TCP. Здесь основная идея в том, что в мобильном телефоне обычно есть связь Wi-Fi и 4G, так почему бы не использовать их одновременно, чтобы увеличить пропускную способность и надёжность.
Реализовать эти дополнения к TCP не то чтобы чересчур сложно, а вот действительно развернуть их в масштабе интернета — практически невыполнимо. Поскольку TCP очень популярен, почти у каждого подключенного устройства есть своя реализация этого протокола. Если эти реализации слишком старые или содержат много багов, расширения будет невозможно использовать. То есть все реализации протокола должны знать о расширении, чтобы оно приносило пользу.
Проблем бы не было, если бы речь шла только об устройствах конечных пользователей (компьютерах, например, или веб-серверах), потому что обновить их вручную несложно. Но существует много других устройств между клиентом и сервером, у которых есть своя реализация кода TCP (например, файрволы, балансировщики нагрузки, роутеры, серверы кэширования, прокси и т. д.).
Промежуточные устройства обновлять сложнее, и обычно у них больше ограничений. Например, файрвол может быть настроен так, чтобы блокировать весь трафик, который содержит неизвестные расширения. На практике оказывается, что огромное число активных промежуточных устройств предъявляет к TCP определённые требования, которые больше не поддерживаются новыми расширениями.
Потребуются годы, может, даже больше десяти лет, чтобы обновить реализации TCP на промежуточных устройствах и реально использовать эти расширения в большом масштабе. Получается, что развивать TCP практически невозможно.
Оставалось только заменить его. Из-за сложных функций и многочисленных реализаций TCP создать что-то новое с нуля было бы неподъёмной задачей. В итоге в начале 2010-х решено было отложить эту работу.
В конце концов, проблемы были не только у TCP — с HTTP/1.1 тоже не всё было гладко. Мы решили сначала «исправить» HTTP/1.1. Так появился HTTP/2. Только потом мы приступили к работе над заменой TCP — QUIC. Поначалу мы надеялись, что нам удастся запустить HTTP/2 поверх QUIC напрямую, но на практике это серьёзно снизило бы эффективность реализации (из-за дублирования функций).
Так что мы скорректировали несколько важных аспектов HTTP/2, чтобы добиться совместимости с QUIC. Исправленную версию в итоге назвали HTTP/3 (вместо HTTP/2-over-QUIC) — в основном, в маркетинговых целях и для ясности. Так что между HTTP/1.1 и HTTP/2 различий гораздо больше, чем между HTTP/2 и HTTP/3.
Выводы
На самом деле нам нужен был не HTTP/3, а TCP/2. Просто в процессе у нас сам собой получился HTTP/3. Всё то, чего мы с таким нетерпением ждем от HTTP/3 (быстрая установка соединения, меньше блокировок HoL, миграция соединения и т. д.), — на самом деле уже реализовано в QUIC.
Что такое QUIC?
Почему это так важно? Какая разница, HTTP/3 это делает или QUIC? Мне кажется, разница есть, ведь QUIC — это универсальный транспортный протокол. Как и TCP, он может и будет использоваться в разных сценариях, не только для HTTP и загрузки сайтов. Например, поверх QUIC можно пристроить DNS, SSH, SMB, RTP и так далее. Давайте узнаем о QUIC чуть больше, ведь именно с ним связаны многие заблуждения по поводу HTTP/3.
Вы, наверное, слышали, что QUIC работает поверх ещё одного протокола — UDP. Это правда, но производительность тут ни при чём. В идеале QUIC мог бы быть полностью независимым транспортным протоколом сразу над IP в стеке, как на картинке выше.
Но тогда возникли бы те же сложности, что и при попытке развивать TCP: пришлось бы сначала обновить все устройства в интернете, чтобы они распознавали и разрешали QUIC. К счастью, мы можем разместить QUIC поверх ещё одного распространённого протокола транспортного уровня: UDP.
А вы знали?
UDP — это максимально примитивный транспортный протокол. Он не отвечает вообще ни за что, кроме номеров портов (например, HTTP использует порт 80, HTTPS — 443, а DNS — 53). Он не устанавливает соединение с помощью рукопожатия и не обеспечивает надежность — потерянный пакет UDP не передаётся снова автоматически. Получается, что UDP работает на максимальной производительности — без ожидания рукопожатий и блокировок HoL. На практике UDP обычно используется для динамического трафика, который обновляется на высокой скорости и меньше зависит от потери пакетов, потому что недостающие данные всё равно быстро устаревают (например, онлайн-конференции или игры). Ещё он хорошо подходит для сценариев, где нужна минимальная задержка, например, поиск доменных имен DNS требует всего одной передачи туда и обратно.
Многие говорят, что HTTP/3 создан поверх UDP в целях производительности. Якобы HTTP/3 работает быстрее, потому что, как и UDP, не устанавливает соединение и не ждет повторной передачи пакетов. Не верьте. Мы уже сказали, что UDP используется протоколом QUIC, а значит и HTTP/3, в надежде, что так их будет проще развернуть, ведь UDP уже знают и используют почти все устройства в интернете.
Расположенный поверх UDP, QUIC, по сути, реализует почти все функции, которые делают TCP таким эффективным и популярным (пусть и чуть более медленным) протоколом. QUIC абсолютно надёжен — он использует подтверждение полученных пакетов и повторные передачи, чтобы добрать то, что потерялось. QUIC по-прежнему устанавливает соединение и использует сложную систему рукопожатий.
Наконец, QUIC использует механизмы flow-control и congestion-control, которые не дают отправителю перегрузить сеть или получателя, но замедляют TCP по сравнению «чистым» UDP. Правда QUIC реализует эти функции умнее и эффективнее. В нём собраны десятилетия опыта и лучших практик TCP и новые функции. Позже мы рассмотрим эти функции подробнее.
Выводы
Ключевой вывод — бесплатный сыр бывает только в мышеловке. HTTP/3 не обгонит HTTP/2 волшебным образом, только потому что мы заменили TCP на UDP. Поэтому мы реализовали значительно улучшенную версию TCP и назвали ее QUIC. И поскольку мы хотим упростить развёртывание QUIC, мы прикрутили его на UDP.
Большие перемены
Почему QUIC лучше TCP? В чём разница? В QUIC есть несколько новых фич и возможностей (передача данных на 0-RTT, миграция соединений, больше устойчивости к потере пакетов и медленным сетям). Подробно мы поговорим о них в следующей части серии. Вкратце, все сводится к четырём основным изменениям:
- QUIC глубоко интегрирован с TLS.
- QUIC поддерживает несколько независимых потоков байтов.
- QUIC использует идентификаторы соединений.
- QUIC использует фреймы.
А теперь подробнее о каждом пункте.
Без TLS нет QUIC
Как мы уже говорили, протокол TLS (Transport Layer Security) отвечает за защиту и шифрование данных, отправленных через интернет. Когда вы используете HTTPS, открытый текст HTTP сначала шифруется TLS и только затем передается TCP.
А вы знали?
Вдаваться в технические детали TLS, к счастью, не обязательно. Достаточно знать, что шифрование выполняется с помощью сложных вычислений и очень больших простых чисел. Вся эта математика согласуется между клиентом и сервером во время отдельных криптографических рукопожатий, на которые, конечно, требуется время. В предыдущих версиях TLS (допустим, 1.2 и ниже) для этого требовалось два прохода туда-обратно. К счастью, новые версии TLS (сейчас последняя версия — 1.3) обходятся всего одним, потому что TLS 1.3 использует только математические алгоритмы, которые можно согласовать за одно рукопожатие. Это означает, что клиент может сразу догадаться, какие алгоритмы поддерживает сервер, не запрашивая и не получая список.

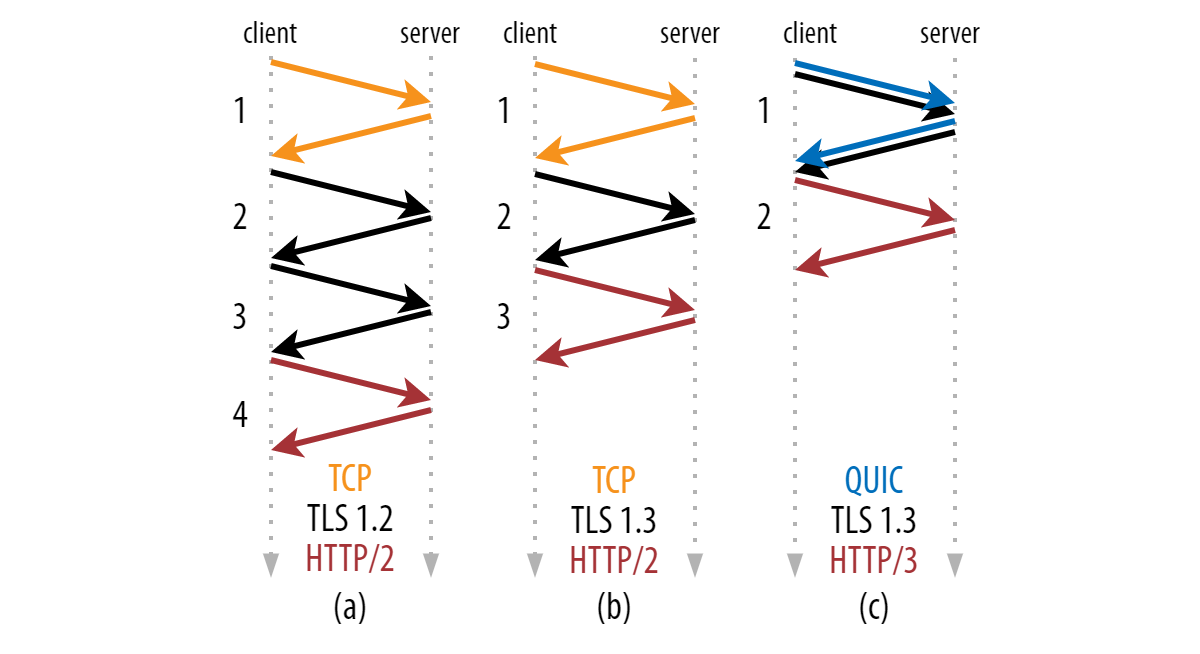
Рукопожатия для TLS, TCP и QUIC (исходное изображение)
На заре интернета шифрование трафика было ресурсозатратным. Считалось, что это нужно только в некоторых ситуациях. Исторически сложилось, что TLS стал полностью отдельным протоколом, который можно использовать поверх TCP по желанию. Поэтому мы разделяем HTTP (без TLS) и HTTPS (с TLS).
Со временем вектор развития интернета сместился в сторону принципа «защищено по умолчанию». В теории HTTP/2 можно поместить поверх TCP без TLS (это даже определено в спецификации RFC как открытый текст HTTP/2), но ни один популярный браузер не поддерживает этот режим. В каком-то смысле создатели браузеров решили усилить безопасность в ущерб производительности.
Раз теперь мы стремимся использовать TLS всегда (особенно для веб-трафика), неудивительно, что создатели QUIC вывели этот тренд на новый уровень. Вместо того, чтобы просто не определять режим открытого текста для HTTP/3, они решили встроить шифрование глубоко в сам QUIC. В первой версии QUIC от Google для этого использовалась кастомная настройка, а в стандартизированном QUIC есть сам TLS 1.3.
В итоге, по сути, чёткие границы между протоколами в стеке стираются, как видно на картинке выше. TLS 1.3 по-прежнему может работать независимо поверх TCP, но QUIC уже включает в себя TLS — невозможно использовать QUIC без TLS, поэтому QUIC (а значит и HTTP/3) всегда полностью зашифрован. Более того, QUIC шифрует почти все поля заголовков пакетов. Информация на транспортном уровне (номера пакетов, которые никогда не шифруются для TCP) больше недоступны для промежуточных точек (шифруются даже некоторые флаги заголовков пакетов).

В отличие от пары TCP + TLS, QUIC всегда шифрует метаданные на транспортном уровне в заголовке и полезной нагрузке пакета. (Примечание: размер полей нельзя менять.) (исходное изображение)
Для этого QUIC сначала использует рукопожатие TLS 1.3 примерно так же, как TCP, чтобы установить математические параметры шифрования. Затем QUIC берёт инициативу и шифрует пакеты сам, а в модели TLS-over-TCP шифрованием занимается TLS. Это, вроде бы, незначительно отличие — большой шаг к постоянному шифрованию, которое применяется на ещё более низких уровнях протоколов.
Такой подход дает QUIC несколько преимуществ:
- QUIC безопаснее для пользователей.
Использовать QUIC с открытым текстом просто невозможно, поэтому у злоумышленников и перехватчиков меньше шансов. (Недавние исследования показали, как опасен открытый текст в HTTP/2.) - С QUIC соединение устанавливается быстрее.
В паре TLS-over-TCP обоим протоколам нужны отдельные рукопожатия, а QUIC объединяет транспортное и криптографическое рукопожатие в одно, экономя один цикл приема-передачи (см. картинку выше). Подробнее мы поговорим об этом во второй части. - QUIC проще развивать.
Он полностью зашифрован, так что промежуточные устройства в сети не видят и не интерпретируют его работу, как с TCP. Поэтому новые версии QUIC будут работать так же легко, даже без обновления. Если мы захотим добавить в QUIC новые фичи, достаточно будет обновить конечное устройство, не трогая все промежуточные.
Шифрование требует больше ресурсов, и с этим связаны потенциальные недостатки нового протокола:
- Многие сети будут неохотно разрешать QUIC.
Компании захотят блокировать его на файрволах, потому что он мешает обнаруживать нежелательный трафик. Интернет-провайдеры и промежуточные сети будут его блокировать, потому что с ним сложнее определять разные метрики для диагностики, вроде средних задержек и процента потери пакетов. Это значит, что QUIC, скорее всего, никогда не будет использоваться повсюду. Подробнее об этом мы поговорим в третьей части.
1. У QUIC высокие издержки на шифрование.
QUIC шифрует через TLS каждый пакет по отдельности, а в TLS-over-TCP несколько пакетов шифруется за раз. Если трафик интенсивный, QUIC может работать медленнее (как мы увидим во второй части).
1. QUIC приводит к централизации.
Я часто слышу жалобы, что Google продвигает QUIC, чтобы получить полный доступ к данным и при этом не делиться ими ни с кем. Не соглашусь. Во-первых, QUIC скрывает от внешних наблюдателей не больше (и не меньше!) пользовательской информации (например, по каким URL вы переходите), чем TLS-over-TCP. В этом плане никаких изменений.
Во-вторых, хотя проект по QUIC затеяла Google, окончательные варианты протокола разработаны обширной командой Internet Engineering Task Force (IETF). QUIC IETF очень отличается от QUIC Google в техническом плане. Хотя в IETF и правда по большей части собрались ребята из крупных компаний, вроде Google и Facebook, и CDN, например, Cloudflare и Fastly. Из-за сложного устройства QUIC как раз у этих компаний будет достаточно знаний, чтобы правильно и эффективно развернуть HTTP/3 на практике. Возможно, это усилит централизацию, и это действительно смущает.
Личное мнение автора:
Я не просто так пишу эти статьи и выступаю, рассказывая о технических деталях, — я хочу помочь людям разобраться в тонкостях и использовать протокол не через корпорации.
Выводы
QUIC глубоко зашифрован по умолчанию. Это хорошо не только для безопасности и конфиденциальности, но и в плане развёртывания и возможностей развития. Шифрование немного утяжеляет протокол, зато, например, позволяет быстрее устанавливать соединение.
QUIC воспринимает несколько потоков байтов
Второе важное отличие TCP и QUIC связано с техническими нюансами, и его последствия мы подробно обсудим во второй части. Сейчас мы рассмотрим только общие аспекты.
А вы знали?
Даже простейшая веб-страница состоит из множества независимых файлов и ресурсов: HTML, CSS, JavaScript, изображения и т. д. Все эти файлы можно рассматривать как простые двоичные BLOB — набор нулей и единичек, которые интерпретирует браузер. При отправке этих файлов по сети мы передаем их не все сразу. Они делятся на небольшие фрагменты (обычно по 1400 байтов) и отправляются в отдельных пакетах. Поэтому каждый ресурс можно рассматривать как отдельный поток байтов, так как данные загружаются постепенно, потоком.
Для HTTP/1.1 все довольно просто, потому что каждый файл получает собственное TCP-соединение и загружается полностью. Например, для передачи файлов A, B и C у нас будет три TCP-соединения и три потока байтов — AAAA, BBBB, CCCC (каждая буква — отдельный пакет TCP). Это работает, но не слишком эффективно, потому что каждое соединение создает издержки.
На практике браузеры накладывают ограничения на количество соединений, а значит и на количество файлов, которые можно загрузить параллельно. Обычно это от 6 до 30 на загрузку одной страницы. Когда один файл загрузится, это соединение будет использоваться для следующего. Эти ограничения снижают производительность современных страниц, которые обычно включают куда больше 30 ресурсов.
HTTP/2 во многом был создан как раз для того, чтобы исправить эту проблему. Он не открывает по отдельному TCP-соединению для каждого файла, а загружает разные ресурсы через одно. Для этого используется мультиплексирование потоков байтов. Проще говоря, мы смешиваем данные из разных файлов при передаче. В нашем примере у нас будет одно TCP-соединение для трех файлов, и поток будет выглядеть примерно как AABBCCAABBCC (хотя схем порядка может быть много). Это выглядит довольно просто и работает неплохо, поэтому HTTP/2 работает не медленнее, чем HTTP/1.1, но требует меньше ресурсов.
Вот схема этого различия:

HTTP/1.1 не допускает мультиплексирование, в отличие от HTTP/2 и HTTP/3. (исходное изображение)
Правда, со стороны TCP есть проблема. Все-таки TCP очень старый и создан не только для загрузки веб-страниц, поэтому ни о каких A, B или C он не знает. С его точки зрения, он передаёт один файл, X, и ему нет дела, что XXXXXXXXXXXX на уровне HTTP на самом деле выглядит как AABBCCAABBCC. Обычно это и не важно, тем более что благодаря этому TCP довольно гибкий. Проблемы возникают, когда какой-нибудь пакет теряется.
Допустим, третий пакет TCP утерян (тот, где содержатся первые данные для файла B), а остальные данные доставлены. TCP в этом случае заново передаёт новую копию потерянных данных в новом пакете. Повторная передача требует времени (минимум один RTT). Вроде, не так и страшно, ведь у A и C ничего не потерялось, можно начать обработку, пока не придут данные для B. Так ведь?
К сожалению, не так. Логика повторной передачи обрабатывается на уровне TCP, а он о наших A, B и C даже не догадывается. TCP совершенно уверен, что потерялась часть X, а значит оставшиеся данные X обрабатывать нельзя, пока не дойдёт остальное. В двух словах, на уровне HTTP/2 мы знаем, что уже можно начать обработку A и C, но TCP об этом не подозревает, и обработка идет медленнее, чем могла бы. Это пример блокировки HoL.
Решить проблему блокировки HoL на транспортном уровне было одной из главных целей QUIC. В отличие от TCP, QUIC прекрасно понимает, что передаёт несколько независимых потоков байтов. Он, понятно, не в курсе, что передаёт CSS, JavaScript и изображения, но знает, что это отдельные потоки. Поэтому QUIC обнаруживает потерю и восстанавливает пакеты для отдельных потоков.
В нашем сценарии он задержит только данные для потока B, а остальное как можно скорее передаст на уровень HTTP/3. (см. схему ниже) В теории это позволит повысить производительность. На практике есть некоторые нюансы. Но об этом во второй части.

QUIC позволяет избавиться от блокировки HoL на уровне HTTP/3. (исходное изображение)
Как видите, между TCP и QUIC есть фундаментальное различие. Заодно это во многом объясняет, почему нельзя просто запустить HTTP/2 поверх QUIC без изменений. Мы уже говорили, что HTTP/2 может запускать несколько потоков в одном TCP-соединении. В итоге у HTTP/2-over-QUIC получилось бы две разных и конкурирующих абстракции потоков, одна поверх другой.
Их примирение было бы очень сложным и ненадёжным, поэтому главное отличие HTTP/3 от HTTP/2 в том, что он не содержит логику потоков и просто использует потоки QUIC. Во второй части мы увидим, что у этого подхода есть свои последствия, которые касаются реализации server push, сжатия заголовков и приоритизации.
Выводы
TCP изначально не был предназначен для передачи нескольких независимых файлов в одном соединении. Поскольку веб-браузер требует как раз этого, мы много лет терпели разные проблемы. QUIC решает их, делая передачу нескольких потоков байтов основой транспортного уровня и обрабатывая потерю пакетов для каждого потока по отдельности.
QUIC поддерживает миграцию соединений
Третье серьезное улучшение — в QUIC соединения могут дольше оставаться активными.
А вы знали?
Мы часто говорим о соединениях применительно к веб-протоколам. А что такое соединение? Обычно все говорят о TCP-соединении, когда между двумя конечными точками (допустим, браузером или клиентом и сервером) произошло рукопожатие. Поэтому часто (и не совсем справедливо) считается, что UDP не связан с соединением, ведь рукопожатия здесь нет. На самом деле, рукопожатие не так важно. Это просто отправка и получение нескольких пакетов в определённой форме. У него несколько целей, и главная из них — убедиться, что на том конце что-то есть, и оно готово и способно с нами взаимодействовать. Повторюсь: QUIC тоже выполняет рукопожатие, хотя работает поверх UDP, у которого рукопожатий нет.
Как пакеты прибывают в нужное место назначения? В интернете для маршрутизации пакетов между двумя конечными точками используются IP-адреса. Но недостаточно просто подключиться к IP-адресам телефона и сервера, потому что обоим устройствам нужна возможность запускать несколько сетевых программ одновременно.
Поэтому каждому соединению назначается номер порта на обоих устройствах, чтобы можно было различать эти соединения и приложения, которым они принадлежат. У серверных приложений обычно фиксированный номер порта в зависимости от функции (например, порты 80 и 443 для HTTP(S) и 53 — для DNS), а клиенты выбирают свои номера для каждого соединения отчасти рандомно.
Чтобы определить уникальное соединение между машинами и приложениями, мы используем четыре компонента: IP-адрес клиента + порт клиента + IP-адрес сервера + порт сервера.
В TCP соединения определяются этими четырьмя параметрами. Если один из них меняется, соединение разрывается и приходится устанавливать новое (с новым рукопожатием). Представьте задачу с парковкой. Вы используете смартфон в здании с Wi-Fi, и у вас есть IP-адрес этой сети.
Вы выходите на улицу, телефон переключается на сотовую сеть 4G, у которой, конечно, другой IP-адрес. Сервер видит, что TCP-пакет поступает с незнакомого IP (при этом оба порта и IP сервера не меняются). См. рисунок ниже.

Задача с парковкой для TCP: клиент получает новый IP, сервер не воспринимает это как прежнее соединение. (исходное изображение)
Как серверу узнать, что пакеты с нового IP относятся к тому же соединению? Как сервер понимает, что эти пакеты не связаны с новым соединением от другого клиента в той же сотовой сети, который случайно выбрал тот же клиентский порт (такое вполне может случиться)? К сожалению, он никак этого не сможет понять.
TCP был изобретен задолго до того, как появились сотовые сети и смартфоны, у него нет механизма, с помощью которого клиент мог бы сообщить серверу, что сменил IP. Там нет даже способа «закрыть» соединение, потому что команда сброса или завершения, отправленная по соединению со старыми четырьмя параметрами, даже не дойдет до клиента. Поэтому на практике при каждой смене сети существующие TCP-соединения больше нельзя использовать.
Нужно новое рукопожатие TCP (и, возможно, TLS), чтобы установить новое соединение. В зависимости от протокола на уровне приложений придется перезапустить некоторые действия. Например, если вы загружали большой файл по HTTP, возможно, придется повторно запросить файл (например, если сервер не поддерживает запросы на диапазон). Ещё один пример — веб-конференция в реальном времени будет ненадолго прерываться при смене сетей.
Для смены одного из четырех параметров могут быть и другие причины (например, повторная привязка NAT). Подробнее об этом мы поговорим во второй части.
Перезапуск TCP-соединений мешает работе (приходится ждать новых рукопожатий, перезапускать загрузку, снова устанавливать контекст). Чтобы решить проблему, QUIC вводит новую концепцию — идентификатор соединения CID. Каждому соединению между двумя конечными точками помимо четырёх параметров присваивается уникальный номер.
Поскольку CID определяется на транспортном уровне в самом QUIC, он не меняется при перемещении между сетями. См. рисунок ниже. Для этого CID указывается перед каждым пакетом QUIC наряду с IP-адресами и портами. Это один из немногих компонентов в заголовке пакета QUIC, который не зашифрован.

QUIC использует CID, чтобы соединение сохранялось после смены сети. (исходное изображение)
При таком раскладе, даже если один из четырех параметров изменится, серверу и клиенту нужно будет просто посмотреть на CID, чтобы узнать старое соединение и дальше использовать его. Новое рукопожатие можно опустить, состояние загрузки сохранится. Обычно это называется миграцией соединения. В теории это позволит повысить производительность, но тут тоже есть свои нюансы (подробности — во второй части).
У CID, конечно, есть недостатки. Например, если мы будем использовать один CID, хакерам будет очень просто отслеживать пользователей по сетям и хотя бы приблизительно определять, где они находятся. Чтобы избежать этих проблем, QUIC меняет CID при каждом переходе в новую сеть.
Да, знаю, я только что сказал, что CID будет одинаковым в разных сетях. Но это я упростил, конечно. На самом деле клиент и сервер договариваются об общем списке рандомно генерируемых CID, которые связаны с одним и тем же соединением.
Например, обе стороны знают, что CID K, C и D относятся к соединению X. Допустим, клиент помечает пакеты K в Wi-Fi, а затем использует C в 4G. Списки полностью зашифрованы в QUIC, так что никто со стороны не поймет, что K и C относятся к X, а клиент и сервер будут это знать, чтобы поддерживать соединение.

QUIC использует несколько согласованных CID, чтобы пользователя нельзя было отследить. (исходное изображение)
Все ещё сложнее, потому что у клиентов и серверов будут разные списки CID, которые они выбрали сами (так же, как у них есть разные номера портов). Это нужно для поддержки маршрутизации и балансировки нагрузки в масштабных системах (подробнее об этом в третьей части).
Выводы
При использовании TCP соединения определяются по четырём параметрам, которые могут меняться при смене сети конечной точки. Приходится тратить время на перезапуск таких соединений. QUIC добавляет ещё один параметр — идентификатор соединения CID. В QUIC клиент и сервер знают, какой CID с каким соединением связан, чтобы соединение можно было не разрывать.
Гибкость и простота развития QUIC
Наконец, QUIC специально создан так, чтобы его было легко развивать. Это связано с несколькими особенностями протокола. Во-первых, QUIC почти полностью зашифрован, так что, если мы захотим развернуть его новую версию, обновлять нужно будет только конечные точки (клиенты и серверы), а не промежуточные устройства. На это, конечно, тоже потребуется время, но речь идёт о месяцах, а не годах.
Во-вторых, в отличие от TCP, QUIC не использует один фиксированный заголовок пакета для отправки всех метаданных протокола. Вместо этого QUIC использует короткие заголовки пакета и разные фреймы (такие миниатюрные специализированные пакеты) в полезной нагрузке пакета, чтобы передать дополнительную информацию. Есть, например, фрейм ACK (acknowledgement — подтверждение), NEW_CONNECTION_ID (для миграции соединения) или STREAM (для передачи данных). См. рисунок ниже.
Это сделано для оптимизации, потому что не каждый пакет содержит все возможные метаданные (заголовки пакетов в TCP весили лишние байты). Ещё один плюс фреймов — в будущем можно будет легко добавлять в QUIC их новые разновидности. Например, фрейм DATAGRAM, которые позволяет отправлять ненадёжные данные по зашифрованному QUIC-соединению.

QUIC использует отдельные фреймы для отправки метаданных вместо большого фиксированного заголовка пакета. (исходное изображение)
В-третьих, QUIC использует кастомное расширение TLS для передачи параметров транспорта, чтобы клиент и сервер могли выбирать конфигурацию для QUIC-соединения. То есть они могут согласовать используемые функции (например, нужно ли разрешить миграцию соединения, какие расширения поддерживаются и т. д.) и передавать важные параметры по умолчанию для некоторых механизмов (например, максимальный поддерживаемый размер пакета, лимиты flow-control). В стандарте QUIC определён длинный список таких параметров, но можно определять и новые, что делает протокол ещё более гибким.
Наконец, сам QUIC этого не требует, но сейчас большинство реализаций выполняется в пользовательском пространстве (а не в пространстве ядра, как у TCP). Подробнее об этом мы поговорим во второй части, но по сути это означает, что нам будет гораздо проще экспериментировать с вариациями реализаций и расширениями QUIC и развёртывать их, чем это было с TCP.
Выводы
Пока что QUIC ещё находится в процессе стандартизации, но текущую реализацию следует считать QUIC version 1, и это указано в Request For Comments (RFC). Вторая версия не за горами. Помимо прочего, QUIC позволяет легко определять расширения, так что вариантов применения будет ещё больше.
Заключение
Подведем итоги по первой части серии. Мы много говорили о вездесущем протоколе TCP и о том, что создавался он в те времена, когда многие современные проблемы невозможно было предугадать. Мы пытались развивать TCP, чтобы хоть как-то адаптировать его, пока не стало ясно, что на практике это будет слишком сложно, потому что придётся обновлять его реализации на каждом устройстве.
Чтобы обойти эту проблему, мы создали новый протокол QUIC (по сути, это TCP 2.0). Чтобы QUIC было проще развёртывать, он работает поверх UDP (который поддерживается большинством сетевых устройств), а чтобы он соответствовал современным тенденциям развития, в нем почти все зашифровано по умолчанию и используется гибкий механизм фреймов.
Не считая этого, QUIC почти полностью повторяет TCP, например, в плане рукопожатий, надёжности и контроля перегрузки. Кроме шифрования и фреймов, добавлено определение нескольких потоков байтов и идентификатор соединения CID. Из-за этих изменений невозможно было использовать HTTP/2 поверх QUIC напрямую, и пришлось создать HTTP/3 (по сути, это HTTP/2-over-QUIC).
Новый подход QUIC даёт много улучшений в производительности, но потенциальные преимущества имеют свои оговорки, о которых редко упоминается в статьях о QUIC и HTTP/3. Зная основы, мы сможем подробно обсудить эти нюансы в следующей части серии. Следите за новыми выпусками.
Автор: Виктория Шевчук






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}