
Вопрос «как внедрить у себя девопс» стоит не первый год, но хороших материалов не так много. Иногда вы становитесь жертвой рекламы не особо умных консультантов, которым нужно продать свое время, неважно как. Иногда это мутные, крайне общие слова о том, как корабли мегакорпораций бороздят просторы вселенной. Возникает вопрос: а нам-то с этого что? Уважаемый автор, можете внятно списочком сформулировать свои идеи?
Все это происходит от того, что реальной практики и понимания исхода трансформаций культуры компании накопилось не так много. Изменения в культуре — это долгоиграющие штуки, результаты которых проявятся не через неделю и не через месяц. Нам нужен кто-то достаточно древний, повидавший, как создавались и рушились компании на протяжении многих лет.

Джон Уиллис — один из отцов DevOps. За плечами у Джона — десятки лет работы с огромным количеством компаний. В последнее время Джон стал для себя замечать специфические паттерны, которые имеют место быть в работе с каждой из них. Используя эти архетипы, Джон наставляет компании на истинный путь DevOps-трансформации. Подробнее об этих архетипах — в переводе его доклада с конференции DevOops 2018.
О докладчике:
Более 35 лет в IT-управлении, участвовал в создании предшественника OpenCloud в Canonical, принимал участие в 10 стартапах, два из которых продал Dell и Docker. Сейчас является Vice President of DevOps and Digital Practices в SJ Technologies.
Далее — повествование от лица Джона.
Меня зовут Джон Уиллис, и меня проще всего найти в Твиттере, @botchagalupe. Тот же псевдоним у меня на Gmail и GitHub. А по этой ссылке вы можете найти видеозаписи моих докладов и презентации к ним.
У меня много встреч с CIO различных крупных компаний. Они очень часто жалуются, что не понимают, что такое DevOps, а все, кто им пытается это объяснить, говорят о чем-то своем. Другая частая жалоба — DevOps не работает, хотя вроде бы директоры всё делают так, как им объяснили. Речь идет о крупных компаниях, которым по сто с лишним лет. Пообщавшись с ними, я пришел к выводу, что для многих проблем лучше всего подходят не высокие технологии, а относительно низкотехнологичные решения. Неделями я просто общался с людьми из разных отделов. То, что вы видите на самой первой картинке в посте — последний мой проект, комната так выглядела после трех дней работы.
Что такое DevOps?
Действительно, если спросить 10 разных человек, они дадут 10 разных ответов. Но вот что интересно: все эти десять ответов будут правильными. Неправильного ответа тут нет. Я довольно глубоко занимался DevOps, примерно 10 лет, был первым американцем на первом DevOpsDay. Не скажу, что я умнее всех, кто занимается DevOps, но вряд ли есть кто-либо, кто потратил на это столько же сил. Я считаю, что DevOps возникает тогда, когда соединяется человеческий капитал и технология. Мы зачастую забываем о человеческом измерении, хоть и говорим много о всякого рода культурах.

Сейчас у нас есть много данных, пять лет академических исследований, проверка теорий налажена в промышленных масштабах. Эти исследования говорят нам следующее: если в организационной культуре соединить некоторые поведенческие паттерны, можно получить ускорение в 2000 раз. Этому ускорению соответствует такое же улучшение в устойчивости. Это количественное измерение того преимущества, которое DevOps может дать любой компании. Пару лет назад я рассказывал о DevOps генеральному директору компании из списка Fortune 5000. Когда я готовился к презентации, я сильно нервничал, потому что мне нужно было за 5 минут изложить свой многолетний опыт.
В итоге я дал следующее определение DevOps: это набор практик и паттернов, позволяющих превратить человеческий капитал в высокопроизводительный организационный капитал. Пример — то, как последние 50 или 60 лет работает Toyota.

(Здесь и далее такие схемы приводятся не как справочный материал, а как иллюстрация. Их содержание будет отличаться для каждой новой компании. Тем не менее, картинку можно отдельно посмотреть и увеличить по вот этой ссылке.)
Одна из наиболее успешных таких практик — value stream mapping. Об этом написано несколько хороших книг, автор наиболее успешных из них — Карен Мартин (Karen Martin). Но за последний год я пришел к выводу, что даже этот подход слишком высокотехнологичный. У него, безусловно, есть множество достоинств, я им много пользовался. Но когда генеральный директор спрашивает у тебя, почему его компания не может перейти на новые рельсы, про value stream mapping разговаривать ещё рано. Есть множество значительно более фундаментальных вопросов, на которые предварительно нужно найти ответы.
Мне кажется, что ошибка многих моих коллег в том, что они просто дают компании руководство из пяти пунктов, а потом возвращаются через полгода и смотрят, что произошло. Даже у хорошей схемы вроде value stream mapping есть, скажем так, мертвые зоны (blind spots). После сотен интервью с директорами различных компаний я наработал определенный паттерн, который позволяет разложить проблему на составляющие, и сейчас мы по порядку обсудим каждую из этих составляющих. Прежде чем применять какие-либо технологические решения, я используют этот паттерн, и в результате у меня все стены оказываются увешаны схемами. Недавно я работал с одним взаимным фондом, и у меня в итоге оказалось 100-150 таких схем.
Плохая культура ест хорошие подходы на завтрак
Главная мысль такая: никакие Lean, Agile, SAFE и DevOps не помогут, если плоха сама культура организации. Это всё равно, что нырять на глубину без акваланга или оперировать без рентгеновского снимка. Иначе говоря, перефразируя Друкера и Деминга: плохая организационная культура поглотит любую хорошую систему и не поперхнется.
Чтобы решить эту главную проблему, необходимо предпринять следующие шаги:
- Make All Work Visible: нужно сделать всю работу видимой. Не в том смысле, что она обязательно должна отображаться на каком-нибудь экране, а в смысле, что она должна быть наблюдаемой.
- Consolidate Work Management Systems: необходимо консолидировать системы менеджмента. В проблеме «племенного» знания и знания институционального в 9 случаях из 10 узким местом являются люди. В книге «Phoenix Project» проблема была в одном-единственном человеке, Бренте, из-за которого проект отставал на три года. И на таких «Брентов» я наталкиваюсь повсюду. Для развязки этих узких мест я использую cледующие два пункта в нашем списке.
- Theory of Constraints Methodology: теория ограничений.
- Collaboration hacks: хаки сотрудничества.
- Toyota Kata (Coaching Kata): о Toyota Kata я много говорить не буду. Если интересно, на моем гитхабе есть презентации почти по каждой из этих тем.
- Market Oriented Organization: ориентированная на рынок организация.
- Shift-left auditors: аудит на ранних этапах цикла.

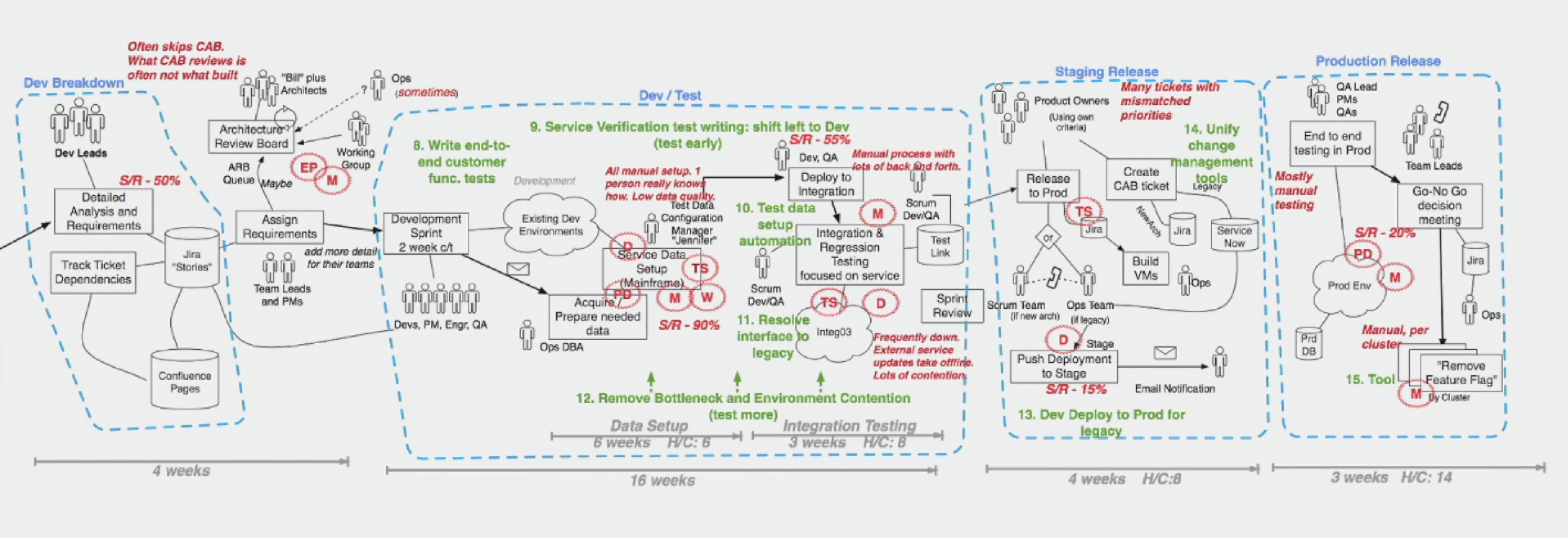
Начинаю работу с организацией я очень просто: иду в компанию и разговариваю с сотрудниками. Как видим, никаких высоких технологий. Всё, что нужно — это чтобы было на чем писать. Я собираю несколько команд в одной комнате и анализирую то, что они мне говорят, с точки зрения моих 7 архетипов. А потом я даю им самим маркер и прошу изложить на доске письменно всё то, что до сих пор они говорили вслух. Обычно на такого рода встречах есть один человек, который всё записывает, и в лучшем случае у него получается записать 10% дискуссии. При моём методе этот показатель удается поднять до где-то 40%.

(Отдельно эту иллюстрацию можно посмотреть по ссылке)
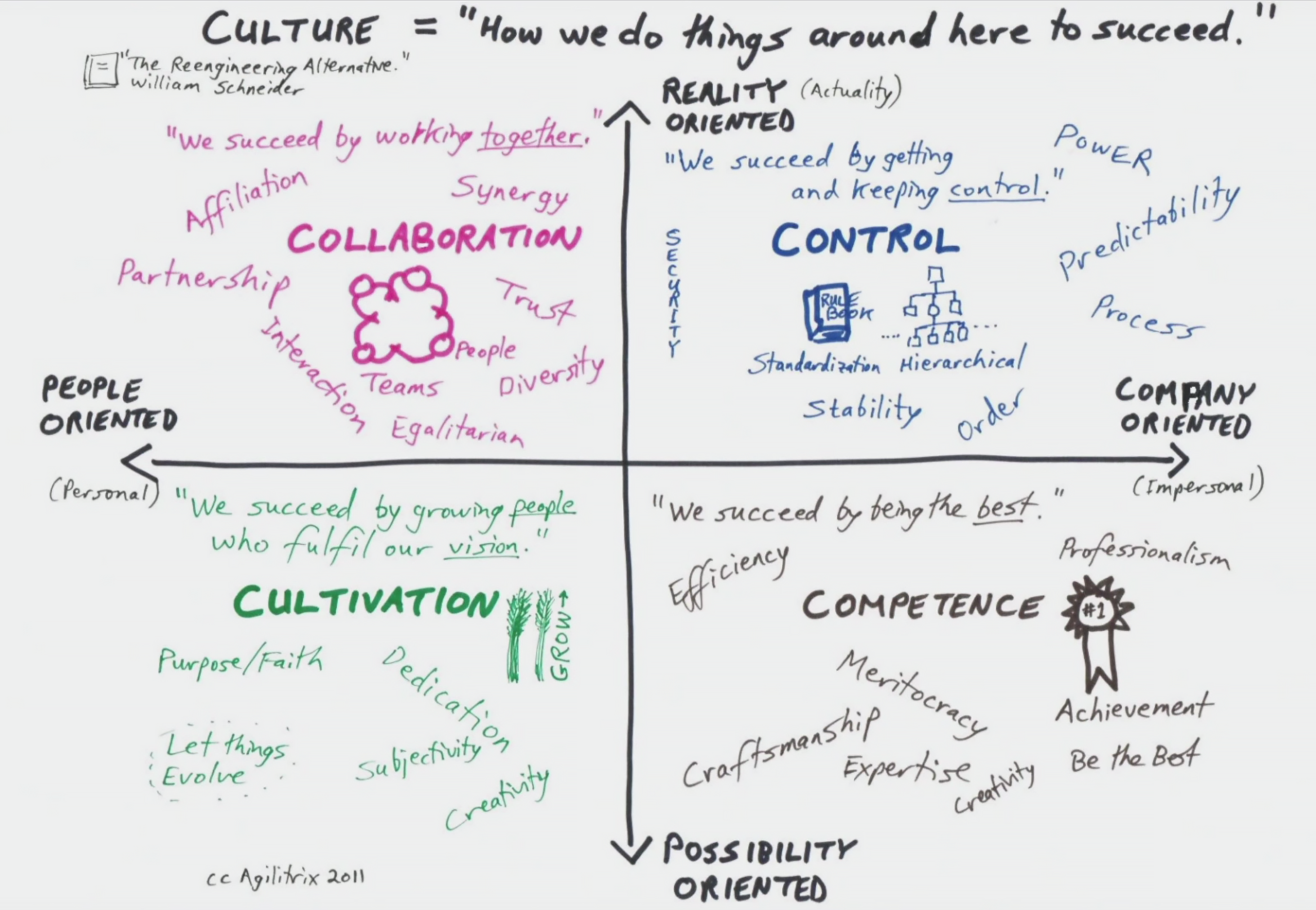
Мой подход основан на работе Уильяма Шнайдера (William Schneider, The Reengineering Alternative). В основе подхода лежит мысль, что любую организацию можно разложить на четыре квадрата. Эта схема у меня обычно является результатом работы с теми сотнями других схем, которые возникают при анализе организации. Предположим, мы имеем организацию с высоким уровнем контроля, но при этом с низкой компетенцией. Это крайне нежелательный вариант: когда все ходят по струнке, но при этом никто не знает, что нужно делать.
Несколько лучше вариант с высоким уровнем и контроля, и компетенции. Если такая компания имеет прибыль, то, возможно, DevOps ей и не нужен. Интереснее всего работать с компанией, у которой высокий уровень контроля, низкая компетенция и сотрудничество, но при этом высокий уровень культуры (cultivation). Это значит, что в компании много людей, которым нравится там работать, оборот рабочей силы низкий.

(Отдельно эту иллюстрацию можно посмотреть по ссылке)
Мне кажется, что методы с жестко заданными рекомендациями в конечном итоге мешают добиться истины. В частности, в value stream mapping есть много правил относительно того, как нужно структурировать информацию. На ранних этапах работы, о которых я сейчас говорю, эти правила никому не нужны. Если человек с маркером в руках описывает на доске реальную ситуацию в компании — это наилучший способ разобраться в положении дел. Такая информация не доходит до директоров. В этот момент глупо обрывать человека и говорить, что он неправильно нарисовал какую-то стрелку. На этом этапе лучше пользоваться простыми правилами, например: многоуровневую абстракцию можно создать, просто используя разноцветные маркеры.
Повторяю, никаких высоких технологий. Черным маркером изображается объективная реальность, как всё работает. Красным маркером люди отмечают, что именно им в существующем положении вещей не нравится. Важно, что это пишут они, а не я. Когда после собрания я иду к директору по информационным технологиям, я не предлагаю перечень из 10 вещей, которые нужно исправить. Я стремлюсь найти связи между тем, что говорят люди из компании, и существующими проверенными паттернами. Наконец, синим маркером предлагаются возможные решения проблемы.

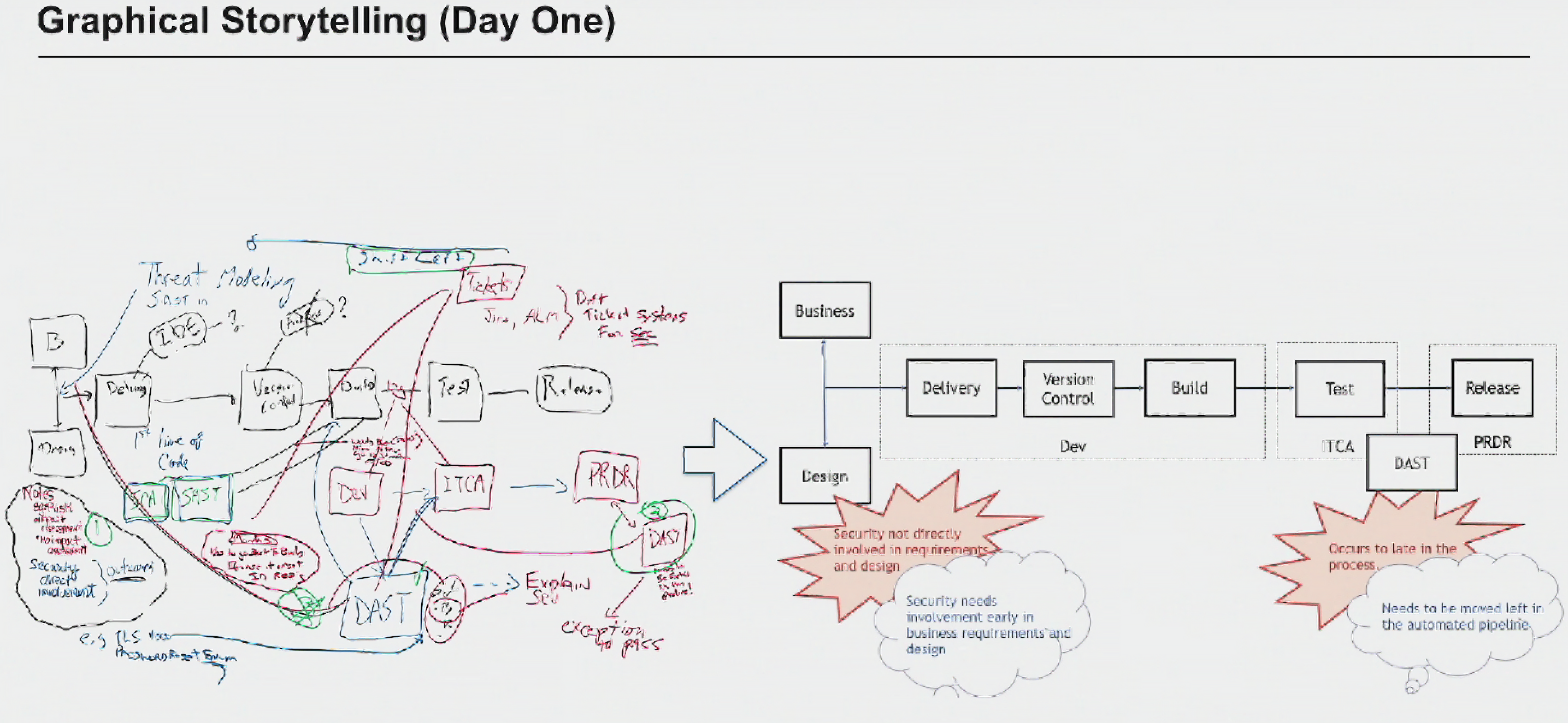
(Отдельно эту иллюстрацию можно посмотреть по ссылке)
Пример такого подхода сейчас изображен выше. В начале этого года я работал с одним банком. Работники из отдела безопасности там были убеждены, что им нельзя приходить на проверки требований и проектирования (design and requirement reviews).

(Отдельно эту иллюстрацию можно посмотреть по ссылке)
А потом мы поговорили с людьми из других отделов и выяснилось, что где-то 8 лет назад разработчики ПО выставили работников безопасности, потому что те замедляли работу. А потом это превратилось в запрет, который воспринимался как данность. Хотя на самом деле никакого запрета не было.
Наша встреча шла крайне запутанным ходом: в течение где-то трех часов пять различных команд никак не могли мне объяснить, что происходит между кодом и сборкой. А это, казалось бы, самая простая вещь. Большинство консультантов DevOps заранее предполагают, что это уже всем известно.
Потом человек, отвечавший за регулирование IT (IT governance), молчавший в течение четырех часов, вдруг ожил, когда мы дошли до его темы, и занял нас ещё на весьма длительное время. Под конец я спросил его, что он думает о встрече, и я никогда не забуду его ответ. Он сказал: «Раньше я думал, что в нашем банке всего два способа поставки софта, а теперь я знаю, что их целых пять, и о трех я даже не подозревал».

(Отдельно эту иллюстрацию можно посмотреть по ссылке)
Последняя встреча в этом банке была с командой, занимающейся ПО для инвестиций. Именно с ней выяснилось, что писать схемы маркером на листе лучше, чем на доске, и даже лучше, чем на смартборде.

Фотографии, которые вы видите — это то, как выглядел конференц-зал отеля на четвёртый день нашей встречи. И эти схемы мы использовали для поиска паттернов, то есть архетипов.
Итак, я задаю вопросы работникам, они записывают ответы маркерами трех цветов (черным, красным и синим). Их ответы я анализирую на предмет архетипов. Сейчас давайте обсудим все архетипы по порядку.
1. Make All Work Visible: Сделать работу видимой
В большинстве компаний, с которыми я работаю, очень высокий процент неизвестной работы. Например, это когда один сотрудник приходит к другому и просто просит что-то сделать. В больших организациях может быть 60% незапланированной работы. И вплоть до 40% работы никак не задокументировано. Если бы это был Boeing, то я в жизни ни разу бы больше не сел на их самолёт. Если документируется только половина работы, то неизвестно, правильно эта работа выполняется или нет. Все остальные методы оказываются бесполезны — нет никакого смысла пытаться что-либо автоматизировать, потому что известные 50% могут быть как раз наиболее слаженной и четкой частью работы, автоматизация которой больших результатов не даст, а всё самое жуткое — в невидимой половине. При отсутствии документации невозможно найти всякого рода хаки и скрытую работу, не найти узкие места, тех самых «Брентов», про которых я уже говорил. Есть прекрасная книга Доминики Де Грандис (Dominica DeGrandis) «Making Work Visible». Она выявляет пять различных «утечек времени» (thieves of time):
- Too Much Work in Process (WIP)
- Unknown Dependencies
- Unplanned Work
- Conflicting priorities
- Neglected Work
Это очень ценный анализ, и книга замечательная, но все эти советы бесполезны, если видны только 50% данных. Применять методы, предложенные Доминикой, можно в том случае, если достигнута точность выше 90%. Я говорю о ситуациях, когда начальник дает подчиненному 15-минутную задачу, а она занимает у того три дня; но начальник на самом деле не знает, что этот подчиненный зависит ещё от четырех или пяти других людей.

Phoenix Project — это замечательный рассказ о проекте, который опоздал на три года. Одному из героев из-за этого грозит увольнение, и он встречается с другим персонажем, который представлен как своего рода Сократ. Тот помогает разобраться, что именно пошло не так. Выясняется, что в компании есть один сисадмин, которого зовут Брент, и вся работа так или иначе проходит через него. На одной из встреч одного из подчиненных спрашивают: почему каждая получасовая задача занимает неделю? В ответ следует очень упрощенное изложение теории очередей и закона Литтла, и в этом изложении оказывается, что при 90%-й занятости каждый час работы занимает 9 часов. Каждое задание требуется отправить семи другим людям, поэтому этот час превращается в 63 часа, 7 умножить на 9. Я это говорю к тому, что, чтобы использовать закон Литтла или сколько-либо сложную теорию очередей, нужно хотя бы иметь данные.
Поэтому когда я говорю о видимости, я имею в виду не чтобы всё было на экране, а что необходимо хотя бы иметь данные. Когда они есть, зачастую выясняется, что есть очень большой объем незапланированной работы, которая почему-то направляется Бренту, хотя в этом нет никакой потребности. А Брент — отличный парень, он никогда не скажет «нет», но при этом он никому не рассказывает, как он делает свою работу.

Когда работа видима, можно аккуратно классифицировать данные (именно этим Доминика занимается на фото), можно применять абстракцию пяти утечек времени и автоматизировать.
2. Consolidate Work Management Systems: Управление задачами
Архетипы, о которых я говорю, представляют из себя своего рода пирамиду. Если первый выполнен правильно, то второй уже является своего рода надстройкой. Многие из них не работают для стартапов, их нужно иметь в виду в случае больших компаний, таких, которые попадают в список Fortune 5000. В последней компании, где я работал, было 10 систем отслеживания ошибок (ticketing system). В одной команде был Remedy, другая написала какую-то свою систему, третья пользовалась Jira, кто-то вовсе обходился электронной почтой. Та же самая проблема возникает, если в компании 30 разных пайплайнов, но времени на то, чтобы обсудить все подобные случаи, у меня нет.
Я обсуждаю с людьми, как именно создаются тикеты, что с ними дальше происходит, как их обходят. Самое интересное, что люди на наших встречах говорят довольно искренне. Я спросил, сколько людей выставляют «minor / no impact» для тикетов, которым на самом деле следовало присвоить «major impact». Выяснилось, что так делают почти все. Я не занимаюсь доносительством и всячески стараюсь не выявлять людей. Когда мне в чем-то искренне признаются, я не выдаю человека. Но когда практически все обходят систему, это значит, что вся безопасность, в сущности, является декорацией. Поэтому никаких выводов из данных этой системы делать нельзя.
Чтобы решить проблему с тикетами, необходимо выбрать одну главную систему. Если вы пользуетесь Jira, пускай будет только Jira. Если есть какая-то альтернатива, пусть будет только она. Суть в том, что тикеты нужно рассматривать как ещё один этап процесса разработки. У любого действия должен быть тикет, который должен проходить через рабочий процесс разработки. Тикеты отправляются команде, которая выкладывает их на storyboard, и затем несёт ответственность за них.
Это касается всех отделов, в том числе и инфраструктурного, и операционного. В таком случае можно составить хоть сколько-либо правдоподобное представление о положении вещей. Когда этот процесс налажен, вдруг оказывается, что можно легко установить, кто несет ответственность за каждое приложение. Потому что теперь мы получаем не 50%, а 98% новых сервисов. Если этот основной процесс работает, то точность повышается во всей системе.
Пайплайн сервисов
Это опять-таки касается только крупных корпораций. Если вы новая компания в новой области — закатайте рукава и работайте со своим Travis CI или CircleCI. Что же касается компаний Fortune 5000, показателен случай, который произошёл с банком, где я работал. К ним пришли из Google, и им показали диаграммы со старыми системами IBM. Ребята из Google c непониманием спросили — а где для этого исходный код? А никакого исходного кода нет, нет даже GUI. Это та реальность, с которой приходится работать крупным организациям: 40-летние банковские записи на древнем мейнфрейме. Один из моих клиентов использует контейнеры Kubernetes с паттернами Circuit Breaker, плюс Chaos Monkey, всё это для приложения KeyBank. Но подключаются эти контейнеры в конечном итоге к приложению на COBOL.
Ребята из Google были в полной уверенности, что они решат все проблемы моего клиента, а потом стали задавать вопросы: что такое IBM datapipe? Им отвечают: это коннектор. К чему она подключается? К системе Sperry. А это что? И так далее. На первый взгляд кажется: какой тут может быть DevOps? Но на самом деле, это возможно. Существуют системы доставки, которые позволяют передать рабочий процесс командам, занимающимся доставкой.
3. Theory of Constraints: Теория ограничений
Перейдем к третьему архетипу: институциональное / «племенное» знание. Как правило, в любой организации есть несколько человек, которые знают всё и всем руководят. Это те, кто дольше всего в организации работает и кто знает все обходные пути.

Когда это выявляется на диаграмме, я специально обвожу таких людей маркером: например, выясняется, что некий Лу присутствует на всех встречах. И для меня ясно: это местный Брент. Когда директор по информационным технологиям выбирает между мной в футболке и кроссовках и одетым в костюм парнем из IBM, меня выбирают потому, что я могу рассказать директору о вещах, которых тот, другой парень, не расскажет и о которых директору может быть неприятно слышать. Я говорю им, что в их компании есть узкое место, это некто по имени Фред и некто по имени Лу. Это узкое место нужно развязать, их знание нужно так или иначе у них добыть.
Чтобы решить такого рода проблему, я могу, например, предложить использовать Slack. Смышленый директор спросит — почему? Обычно в таких случаях консультанты по DevOps отвечают: потому что все так делают. Если директор действительно смышленый, он скажет: ну и что. И на этом диалог закончится. А я на это отвечаю: потому что в компании есть четыре узких места, Фред, Лу, Сьюзи и Джейн. Чтобы сделать их знание институциализированным, нужно, во-первых, ввести Slack. Все ваши вики — это полная чушь, потому что никто не знает об их существовании. Если команда инженеров занимается внешней и внутренней разработкой и все должны знать, что можно обратиться к команде внешней разработки или команде инфраструктуры с вопросами. Именно тогда, вероятно у Лу или Фреда появится время, чтобы подключиться к вики. А потом в Slack кто-то может спросить, почему не работает, скажем, шаг 5. И тогда Лу или Фред исправят инструкцию в вики. Если наладить этот процесс, дальше очень многое само встанет на свои места.
В этом моя основная мысль: чтобы рекомендовать какие-то высокие технологии, нужно сначала привести в порядок фундамент для них, и сделать это можно описанными только что низкотехнологичными решениями. Если же начать с высоких технологий и не объяснить, зачем они нужны, то, как правило, ничем хорошим это не заканчивается. Один из наших клиентов использует Azure ML, очень дешёвое и простое решение. Где-то на 30% вопросов у них отвечала уже сама самообучающаяся машина. А написали эту вещь операторы, которые не занимались data science, статистикой или математикой. Это показательно. Стоимость такого решения минимальная.
4. Collaboration hacks: Хаки сотрудничества
Четвертый архетип заключается в том, что необходимо бороться с изоляцией. Большая часть людей об этом уже знает: изоляция порождает вражду. Если каждый отдел на своём этаже, и люди друг с другом никак не пересекаются, кроме как в лифте, то вражда между ними зарождается очень легко. А если, напротив, люди находятся в одном помещении друг с другом, она сразу же уходит. Когда кто-то бросает некое общее обвинение, например, такой-то интерфейс никогда не работает — нет ничего проще такое обвинение деконструировать. Программистам, написавшим интерфейс, достаточно начать задавать конкретные вопросы, и скоро выяснится, что, например, пользователь просто неправильно использовал инструмент.
Есть много способов преодолеть изоляцию. Меня как-то просили консультировать банк в Австралии, я отказался это делать, потому что у меня двое детей и жена. Всё, чем я мог им помочь — я порекомендовал им graphical storytelling. Это вещь, которая доказуемо работает. Другой интересный способ — встречи формата lean coffee. В большой организации это отличный вариант распространения знания. Кроме того, можно проводить внутренние devopsdays, хакатоны и так далее.
5. Coaching Kata
Как я уже предупреждал в самом начале, сегодня я об этом не буду рассказывать. Если интересно, то можете посмотреть кое-что из моих презентаций.
Есть также хороший доклад на эту тему от Mike Rother:
6. Market Oriented: ориентированная на рынок организация
Здесь есть разные проблемы. Например, люди «I», люди «T» и люди «E». Люди «I» — это те, кто занимается только чем-то одним. Обычно они существуют именно в организациях с изолированными подразделениями. «T» — это если человек хорошо знает что-то одно, но также преуспевает и в некоторых других вещах. «E» или даже «расчёска» — это когда у человека много навыков.

Здесь работает закон Конвея (Conway’s law), который в максимально упрощённой форме можно изложить так: если три команды занимаются компилятором, то в итоге получится компилятор из трёх частей. Поэтому если внутри организации высокий уровень изоляции, то даже Kubernetes, Circuit breaker, API extensibility и прочие модные вещи в этой организации будут устроены так же, как и сама организация. Строго по Конвею и назло всем вам, юные гики.
Решение этой проблемы было описано много раз. Есть, например, организационные архетипы, описанные Фернандо Фернандезом (Fernando Fernandez). Та проблемная архитектура, о которой я только что говорил, с изоляцией — это функционально-ориентированная архитектура. Второй тип — худший, матричная архитектура, там каша из двух других. Третий — это то, что наблюдается в большинстве стартапов, и крупные компании также пытаются этому типу соответствовать. Это ориентированная на рынок организация. Здесь идёт оптимизация для достижения наиболее быстрого отклика на запросы клиентов. Иногда это называется плоской организацией.
Эту структуру многие описывают по-разному, мне нравится формулировка build/run teams, в Amazon это называют two pizza teams. В этой структуре все люди типа «I» группируются вокруг одного сервиса, и постепенно они становятся ближе к типу «T», а если налажен правильный менеджмент, могут стать даже «E». Первый контраргумент здесь — в такой структуре есть лишние элементы. Зачем нужен тестер в каждом отделении, если можно иметь специальный отдел тестировщиков? На что я отвечаю: лишние расходы в данном случае — это цена за то, чтобы в будущем вся организация стала типа «Е». В такой структуре тестировщик постепенно узнаёт о сетях, архитектуре, проектировании и т.п. В итоге каждый участник организации оказывается полностью осведомлен обо всём, что в организации происходит. Если хотите узнать, как эта схема работает в промышленности, почитайте Mike Rother, Toyota Kata.
7. Shift-left auditors: аудит на ранних этапах цикла. Соблюдение правил безопасности напоказ
Это когда ваши действия не проходят, так сказать, проверку на запах. Люди, которые на вас работают, не глупые. Если они, как в примере выше, везде выставляли minor/no impact, это продолжалось три года, и никто ничего не заметил, то все прекрасно знают, что система не работает. Или другой пример — совет по изменениям (change advisory board), куда каждую, скажем, среду, нужно подавать отчёты. Там работает группа людей (кстати говоря, не слишком хорошо оплачиваемых), которые в теории должны знать, как работает система в целом. А за последние лет пять вы, наверное, заметили, что наши системы безумно сложные. И пять-шесть человек должны принять решение относительно изменения, которое не они внесли и о котором они ничего не знают.
Конечно, такой подход не работает. Мне от таких вещей приходится избавляться, потому что эти люди не защищают систему. Решение должна принимать сама команда, потому что команда должна быть ответственной за него. В противном случае возникает парадоксальная ситуация, когда менеджер, никогда в жизни не писавший кода, сообщает программисту, сколько времени должно занять написание кода. В одной компании, с которой я работал, было 7 различных советов, которые рассматривали каждое изменение, в том числе совет по архитектуре, по продуктам и т.п. Существовал даже обязательный период ожидания, хотя один сотрудник мне сказал, что за десять лет работы никто ни разу в этот обязательный период не отклонил изменений, внесенных этим человеком.
Аудиторов нужно звать к себе, а не избавляться от них. Расскажите им, что вы пишете иммутабельные бинарные контейнеры, которые, если пройдут все тесты, остаются неизменными навсегда. Расскажите им, что у вас pipeline as code, и объясните, что это значит. Покажите им следующую схему: иммутабельный binary только для чтения в контейнере, который проходит все тесты на уязвимости; а дальше не только к нему никто не прикасается — не прикасаются даже к системе, которая создает пайплайн, поскольку она также создаётся динамически. У меня есть клиенты, Capital One, которые при помощи Vault создают нечто вроде блокчейна. Аудитору можно не показывать «рецептов» из Chef, достаточно показать блокчейн, из которого ясно, что произошло с тикетом Jira в продакшене и кто за него ответственный.

Согласно отчету, созданному в 2018 году Sonatype, в 2017 году было 87 миллиардов запросов на скачивание OSS.

Убытки, понесенные из-за уязвимостей, оказываются непомерно высокими. Причем те цифры, которые вы сейчас видите выше, не включают альтернативные издержки. В двух словах о том, что такое DevSecOps. Сразу же хочу сказать, что меня не интересуют разговоры о том, насколько удачно это название. Смысл в том, что, коль скоро DevOps были весьма успешными, нужно попробовать добавить к этому пайплайну безопасность.
Пример такой последовательности:

Это не рекомендация определенных продуктов, хоть мне они все и нравятся. Я их привел в качестве примера, чтобы показать, что DevOps, основанный изначально на парадигме организации в промышленности, позволяет автоматизировать каждый этап работы над продуктом.

И нет никакой причины, по которой мы не могли бы применить тот же подход к безопасности.
Итог
В качестве заключения дам несколько советов для DevSecOps. Нужно включить аудиторов в процесс создания ваших систем, потратить время на их образование. С аудиторами нужно сотрудничать. Далее, нужно вести абсолютно безжалостную борьбу с ложными срабатываниями. Даже с самым дорогим инструментом сканирования на уязвимости можно в итоге создать крайне вредные привычки у ваших разработчиков, если вы не знаете, какое отношение сигнала к шуму. Разработчики окажутся перегружены событиями, и они станут просто удалять их. Если вы слышали об истории с Equifax, то там примерно это и произошло, там был проигнорирован сигнал самого высокого уровня опасности. Кроме того, уязвимости нужно объяснять так, чтобы было ясно, как они влияют на бизнес. Например, можно сказать, что это та же уязвимость, что и в истории с Equifax. Уязвимости, относящиеся к безопасности, нужно рассматривать так же, как и другие проблемы с софтом, то есть их нужно включить в общий процесс DevOps. С ними нужно работать через Jira, Kanban и т.п. Разработчики не должны думать, что этим займётся кто-то другой — напротив, этим должны заниматься все. Наконец, нужно тратить силы на то, чтобы обучать людей.
Полезные ссылки
Вот несколько докладов с конференции DevOops, которые могут показаться вам полезными:
- Сергей Бердников, Артём Каличкин — История успеха, или «Dev+DevOps+Ops» (видео, расшифровка доклада)
- Барух Садогурский, Леонид Игольник — DevOps в масштабе: греческая трагедия в трёх актах (видео, расшифровка доклада)
- Александр Титов, Кирилл Толкачёв — DevOps, инженеры и сообщество
- Timothy Lister — Characters, community, and culture: Important factors for prosperity
Загляните в программу DevOops 2020 Moscow — там тоже много чего интересного.
Автор: Таня






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}