
С ростом сложности ИТ-систем и задач аналитики изменяются требования и к возможностям инструментов. Для многих сценариев приоритетными становятся решения, которые могут работать как с историческими данными, так и с теми, которые обновляются в реальном времени. То есть аналитикам все чаще нужен инструмент, работающий на стыке возможностей транзакционных и аналитических (OLAP и OLTP) систем.
Меня зовут Николай Карлов. Я директор инновационных проектов в VK Tech. В этой статье я расскажу, что такое HTAP-системы, какие преимущества они предоставляют, и познакомлю с нашей колоночной СУБД Tarantool Column Store, которая реализует HTAP-обработку.
Статья подготовлена по мотивам вебинара «Анализируем данные в Real-time». Его вы можете посмотреть здесь.
За пределами возможностей OLAP и OLTP
Требования пользователей к ИТ-системам растут. Например, сейчас люди хотят иметь возможность зайти в приложение банка и не только увидеть баланс счета, но и оценить расходы на разные категории покупок за любой период. Причем важно, чтобы учитывались и последние транзакции (например, покупки, сделанные минуту назад).
Подобные запросы не ограничены онлайн-банкингом. Возможность анализировать большой массив данных с учетом постоянно поступающих обновлений важна во многих сценариях: менеджменту, финансовым департаментам, телекому, специалистам по машинному обучению, производственникам и не только.
Тут надо понимать, что классические OLAP- и OLTP-системы используют под разные задачи: одни системы ориентированы на работу с историческими данными, а другие — на обработку данных на лету. Нюанс в том, что описанные в начале примеры и еще десятки других сценариев фактически требуют выхода за рамки привычных возможностей:
-
когда у транзакционных систем появляются функции аналитики с обработкой исторических данных;
-
когда аналитические системы умеют учитывать мгновенное изменение данных.
При наличии таких требований нужны системы, способные выполнять гибридную транзакционно-аналитическую обработку данных (HTAP, Hybrid Transaction/Analytical Processing).
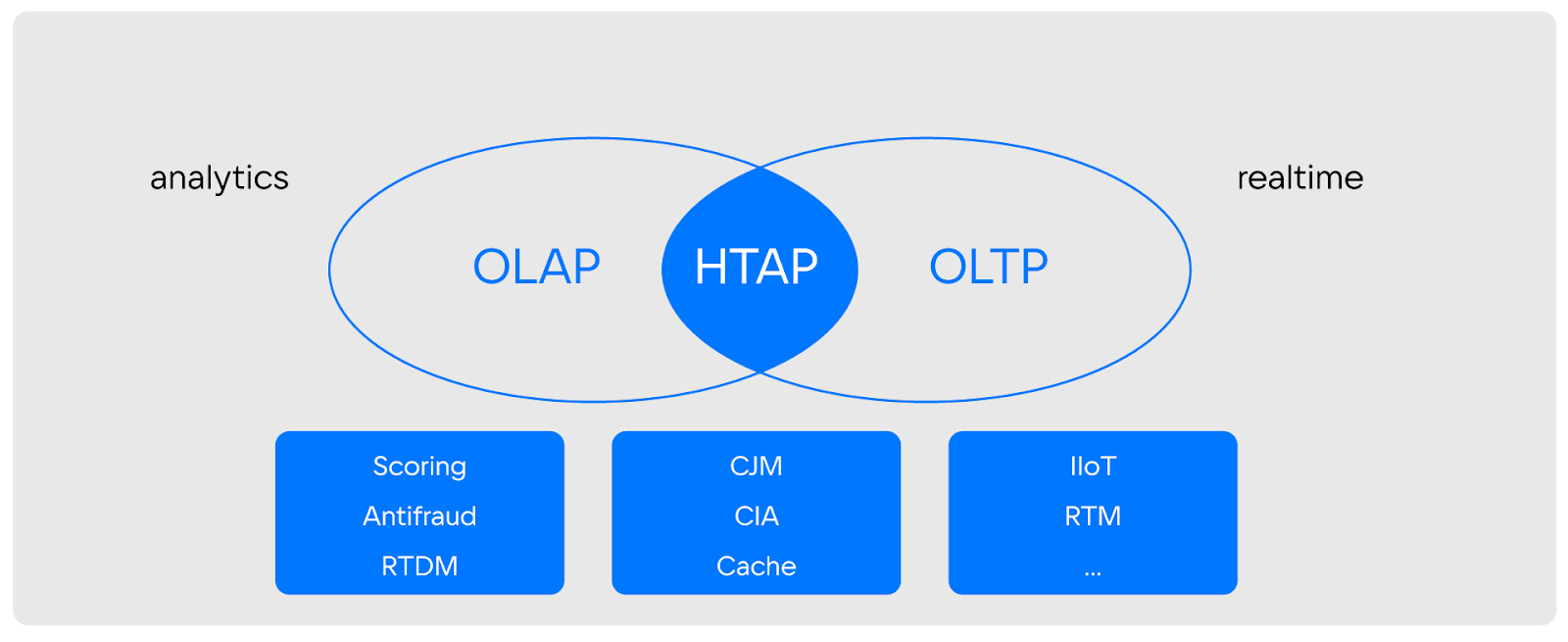
И задач, в которых нужны именно HTAP-системы, очень много — от скоринга, антифрода, реалтайм-маркетинга и машинного обучения до аналитики пользовательских действий и транзакционных операций в реальном времени.
Пример задач для HTAP: работа с ML
Один из распространенных сценариев использования HTAP-систем — работа с моделями машинного обучения. Здесь все очевидно: при подготовке ML-моделей обрабатывают и исторические данные, и те, что поступают в реальном времени — классическая задача для HTAP.
Рассмотрим небольшой пример, чтобы понять, где и когда при работе с ML-моделями нужны HTAP-решения.
Итак. Обычно пользовательские данные формируются из двух составляющих:
-
профиль,
-
поведение.
К профилю относятся признаки, которые не изменяются вообще или изменяются редко — например, пол, возраст, подключенные продукты, долгосрочные интересы. Обычно дата-сайентисты рассматривают эти признаки как статические фичи.
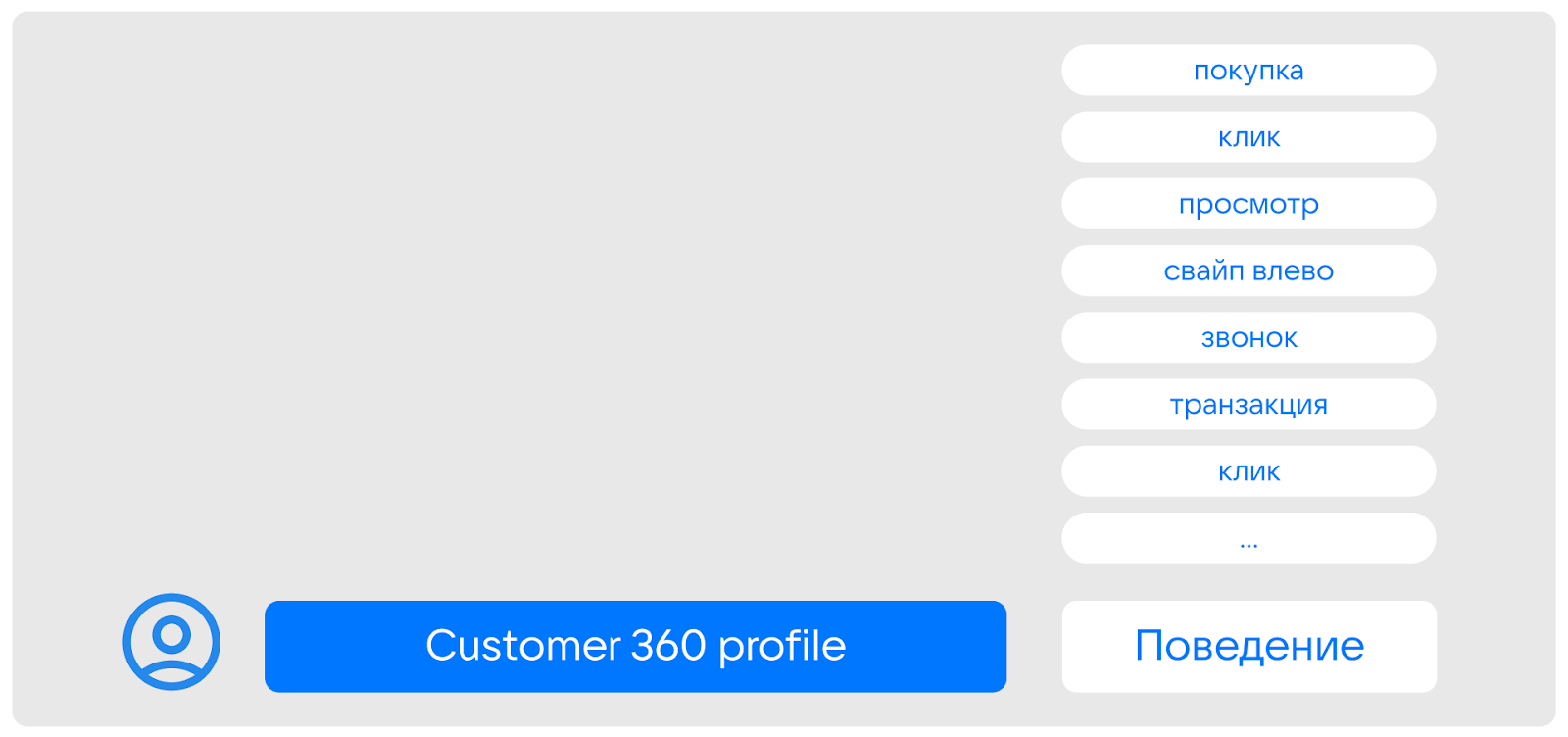
К поведению относят метрики, которые часто меняются и описывают последние события — например, репосты, комментарии, новые подписки. Дата-сайентисты могут рассматривать их в виде динамических фичей.
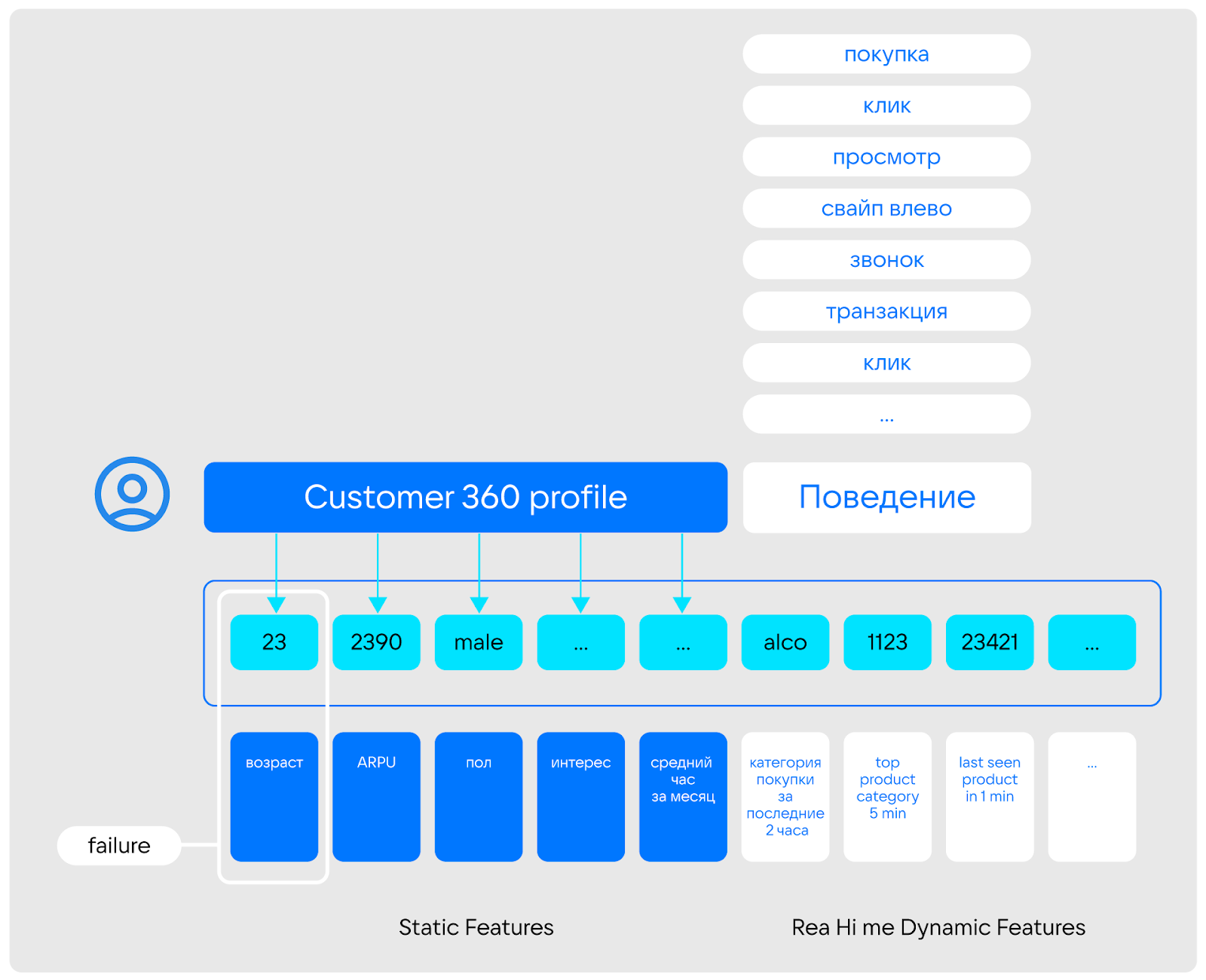
Важно, что для решения, например, задач реалтайм-маркетинга, надо обязательно учитывать как долгосрочные (профиль), как и краткосрочные (поведение) метрики. Здесь и появляется необходимость в гибридной транзакционно-аналитической обработке данных (HTAP) и системе, способной ее выполнять (HTAP-решении).
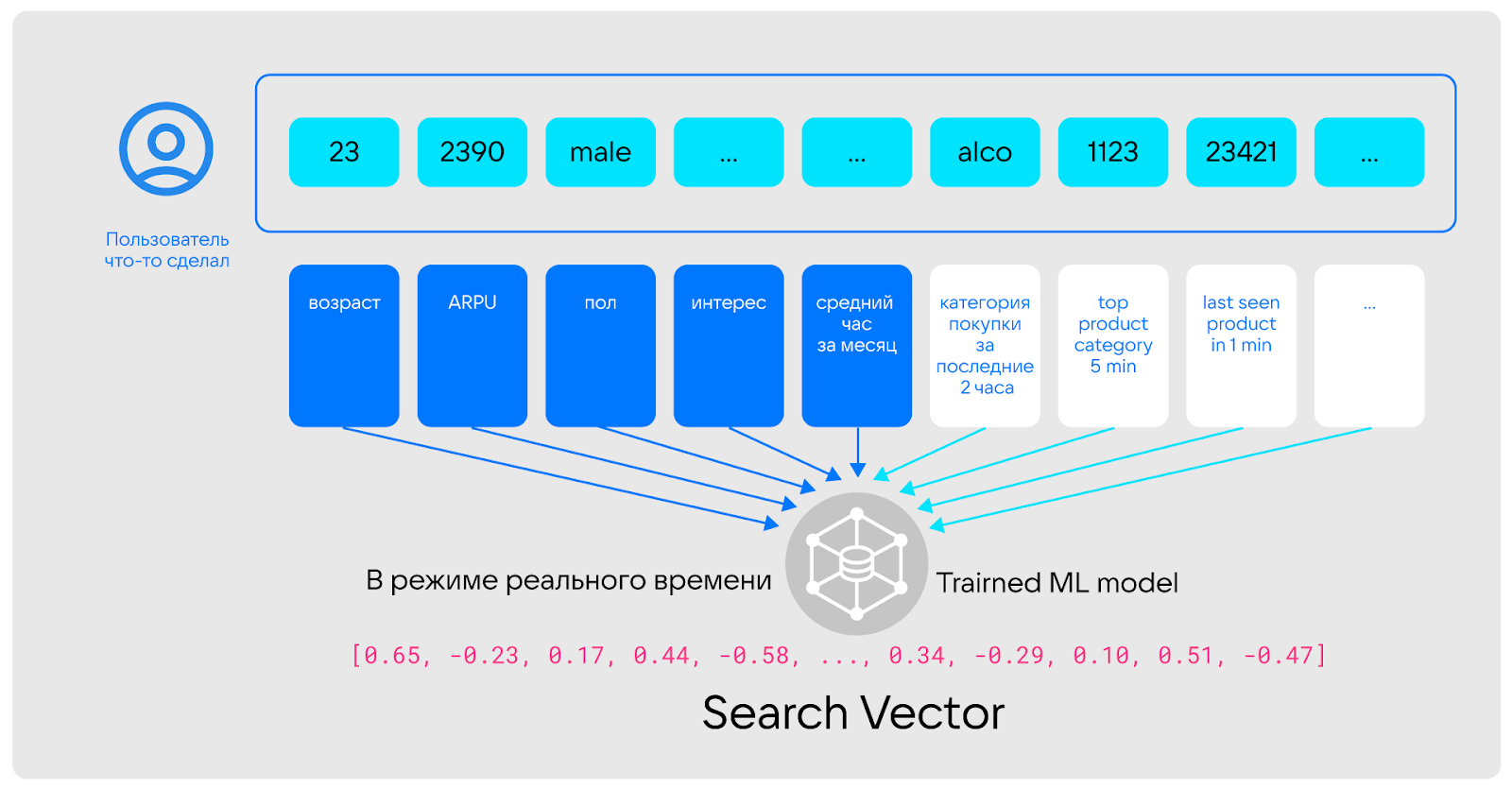
То есть именно HTAP-инструменты позволяют реализовать сценарий, при котором покупатель заходит в интернет-магазин и сразу получает релевантные предложения на основе прошлых покупок, предпочтений, пола и других факторов. Причем при подборе рекомендаций будут иметь значение не только статические метрики и признаки, но и действия, совершенные клиентом «здесь и сейчас». Это особенно важно, если запросы человека меняются кардинально. Например, если он всегда покупал наборы для шитья, а сейчас ищет удочку: продолжать предлагать только наборы для шитья и в этот момент — провальная история для бизнеса.
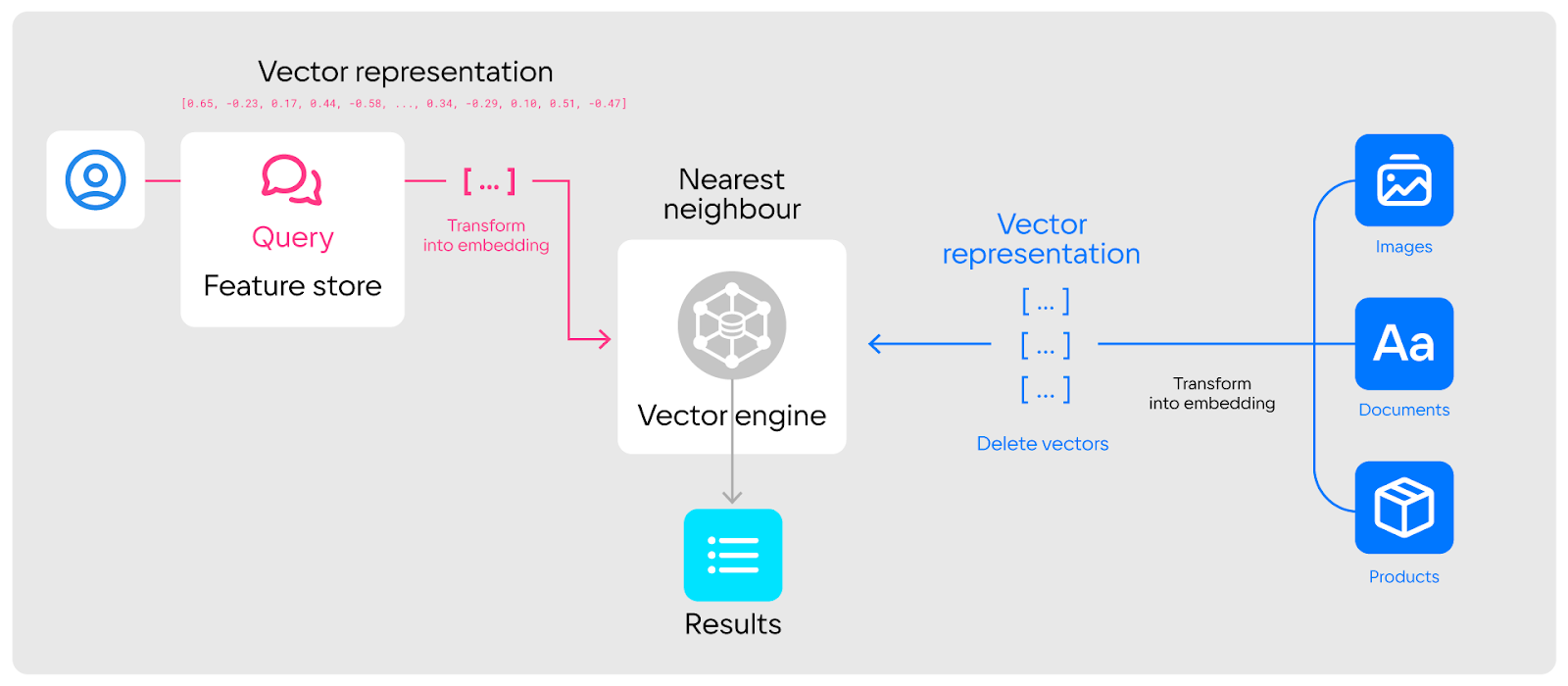
Примечание: В одной из предыдущих статей мы уже описывали развернутый пример работы с HTAP-системой в рамках построения антифрод-системы. Ознакомиться с ним можно здесь.
Архитектура HTAP
В строковых БД для получения каких-то записей из отдельных колонок база данных:
-
выполняет проход по индексу;
-
распаковывает каждую строчку;
-
извлекает из строк значения;
-
добавляет их в массив или временную эфемерную таблицу, которая далее используется для обработки запроса.

То есть БД вынуждена выполнять большой массив работы.
В случае колоночного размещения данных ситуация несколько иная: условно данные «сбиваются» в блоки данных одного типа.
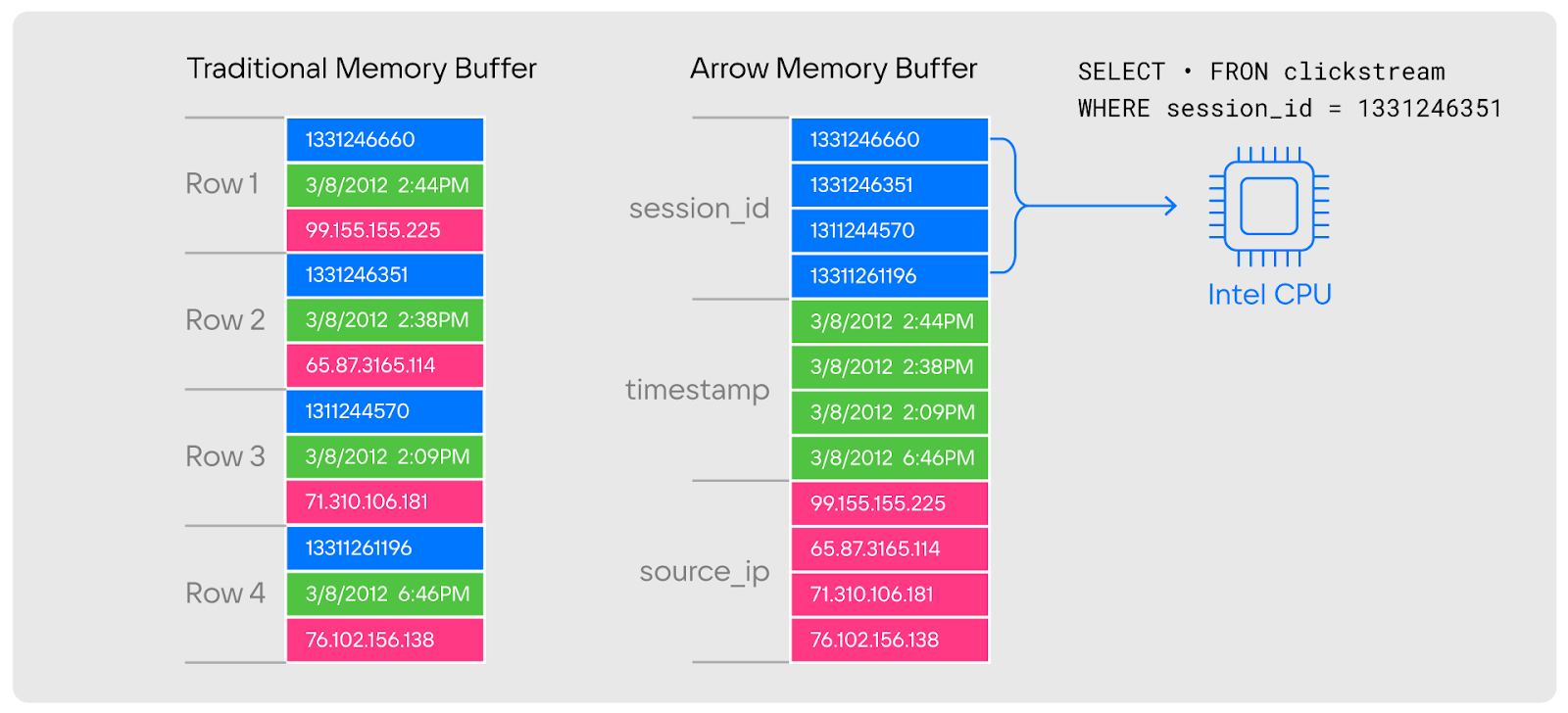
Для задач сканирования данных это гораздо более эффективный подход, поскольку:
-
кэш-процессор может забирать сразу большое количество значений;
-
агрегационные функции и фильтрация могут производиться с помощью векторизации;
-
можно использовать сжатие.
Но даже в случае такого формата хранения в контексте реалтайм-обработки есть подводные камни. Так, при работе с колоночными СУБД:
-
неэффективны единичные операции вставки;
-
операции UPDATE или выполняются неэффективно, или невозможны;
-
сложно выдерживать нагрузку при большом количестве одиночных чтений.
Данные недостатки необходимо компенсировать теми или иными способами. Например, с помощью многослойной архитектуры хранения, а также за счет подходов, аналогичных LSM.
В итоге, комбинируя преимущества каждого типа хранения, базы данных класса HTAP, как правило, используют колоночные движки вместе со строчными.
Что такое Tarantool Column Store
В продуктовом портфеле Tarantool также есть HTAP-решение. Это Tarantool Column Store — In-memory-колоночная СУБД для транзакционно-аналитической обработки данных в реальном времени.
В своем решении мы организовали четыре слоя хранения.
-
Memtx. Строчный буфер с классическими таблицами. Обеспечивает очень высокую производительность для OLTP, низкую для OLAP. Лучше подходит для хранения не большого массива данных, а последних записей — сотен или тысяч.
-
Memcs. Колоночный буфер с новым гибридным движком, который позволяет хранить данные в гибридном, промежуточном формате, делать единичные апдейты и вставки, выполнять full-сканы. Обеспечивает высокую производительность для OLTP и OLAP. Хранит данные непосредственно в индексах с использованием подхода bps-vector. В зависимости от профиля нагрузки может хранить от миллиона до нескольких сотен миллионов записей.
-
Memtx. Основное хранилище с блочно-колоночным типом хранения. Слой обеспечивает высокую производительность OLAP и поддерживает сжатие данных. Как результат, может хранить и обрабатывать миллиарды записей. Вместе с тем здесь обновления не так эффективны, как у Memcs.
Данные хранятся в формате Apache Arrow и имеют выравнивание для эффективной векторизации.
-
Parquet. Слой, на котором данные, которые не нужны постоянно, вытесняются на диск или в S3-хранилище (мы предпочитаем именно S3). Естественно, в таком случае скорость чтения ниже, чем у основного движка. При этом поддерживаются редкие UPDATEs.
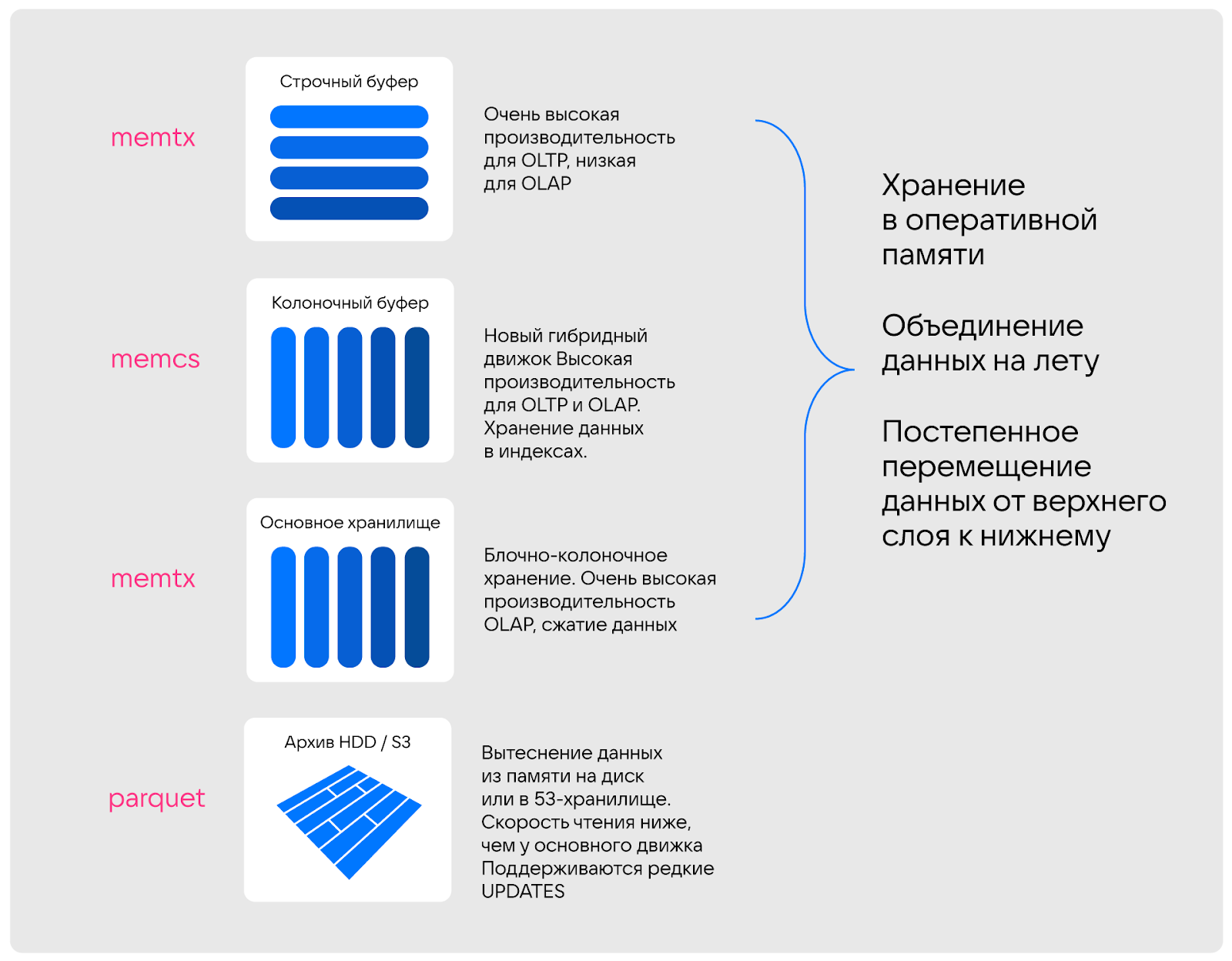
То есть Tarantool Column Store сочетает хранение данных в оперативной памяти и возможность их сброса в постоянную, гарантируя как высокую скорость доступа к информации, так и надежность ее хранения.
Важно, что движки всех уровней совместимы. В сочетании с гарантиями надежности Tarantool (WAL, снапшоты и другие техники) это обеспечивает стабильную, согласованную и эффективную обработку данных на всех этапах.
Query engine
Теперь об исполнении запросов и непосредственно языке исполнения. Использовать запросы в один поток для нас ошибочный путь. Поэтому у нас реализовано многопоточное исполнение запросов с разбиением больших датасетов на партиции и распараллеливанием.
Более того, мы не используем для выполнения запросов на чтение основной транзакционный поток. Это возможно благодаря механизму ReadView, который позволяет читать консистентные снимки данных вне основного потока. Этот механизм ранее применялся для создания консистентных снимков данных во время сохранения на диск снапшотов, но впоследствии был доработан для работы с пользовательскими запросами.
Важно, что у нас векторизованное исполнение (SIMD). Как результат, за один такт процессора может обрабатываться большое количество записей одной колонки, а также повышается эффективность использования кэшей процессора.
В качестве основного синтаксиса у нас выбран PG SQL (как в Postgres). К тому же есть поддержка UDF (User Defined Functions, пользовательские функции) и расширений на Rust. Причем кроме обычных пользовательских функций можно делать и агрегационные функции под разные задачи и сценарии использования — они также будут эффективно работать.
Движок выполнения запросов умеет работать с дата-фреймами, выполнять запросы с языка SQL, имеет несколько уровней логического физического плана выполнения запроса и оптимизаторы.
Архитектура пайплайна данных в Tarantool Column Store
Пайплайн работы с данными в Tarantool Column Store мы выстроили следующим образом:
-
данные попадают в строчный буфер, после чего передаются в колоночный буфер;
-
из колоночного буфера данные попадают в основное хранилище;
-
все изменения из строчного и колоночного буфера попадают в журнал транзакций (WAL Log).
Пайплайн не перегружен лишними этапами, что позволяет сократить время на обработку данных без ущерба качеству и эффективности обработки.
При этом мы предусматриваем возможность использования словарей и Tarantool spaces.
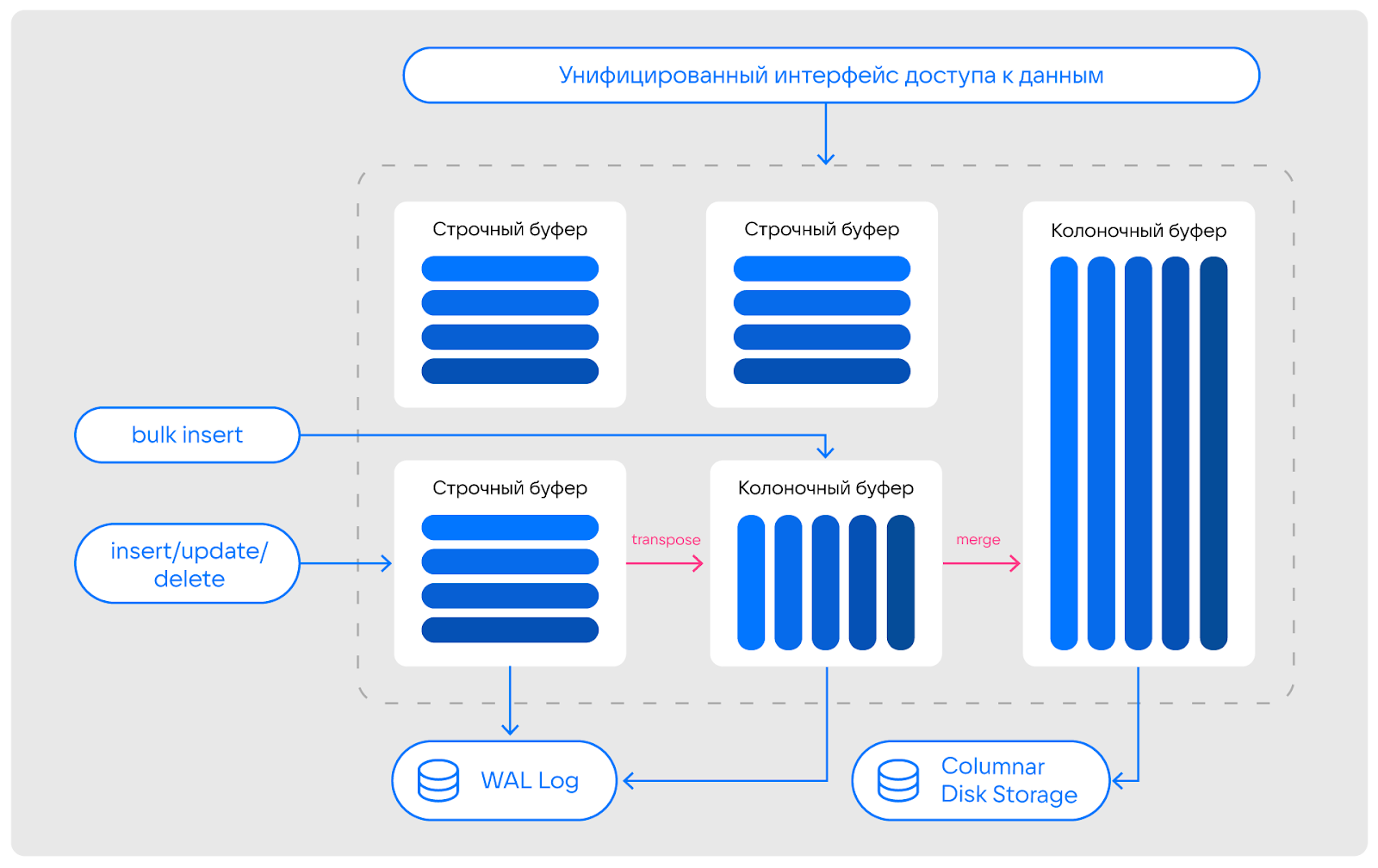
Архитектура Tarantool Column Store
В архитектуре инструмента скомбинированы компоненты, которые отвечают за взаимодействие внутри сервиса, трансфер и обработку запросов, а также другие операции. Среди них:
-
колоночный движок;
-
строчные и колоночные буферы;
-
Compute Kernel Engine (виртуализированная система исполнения запросов);
-
слои репликации и дискового хранилища.
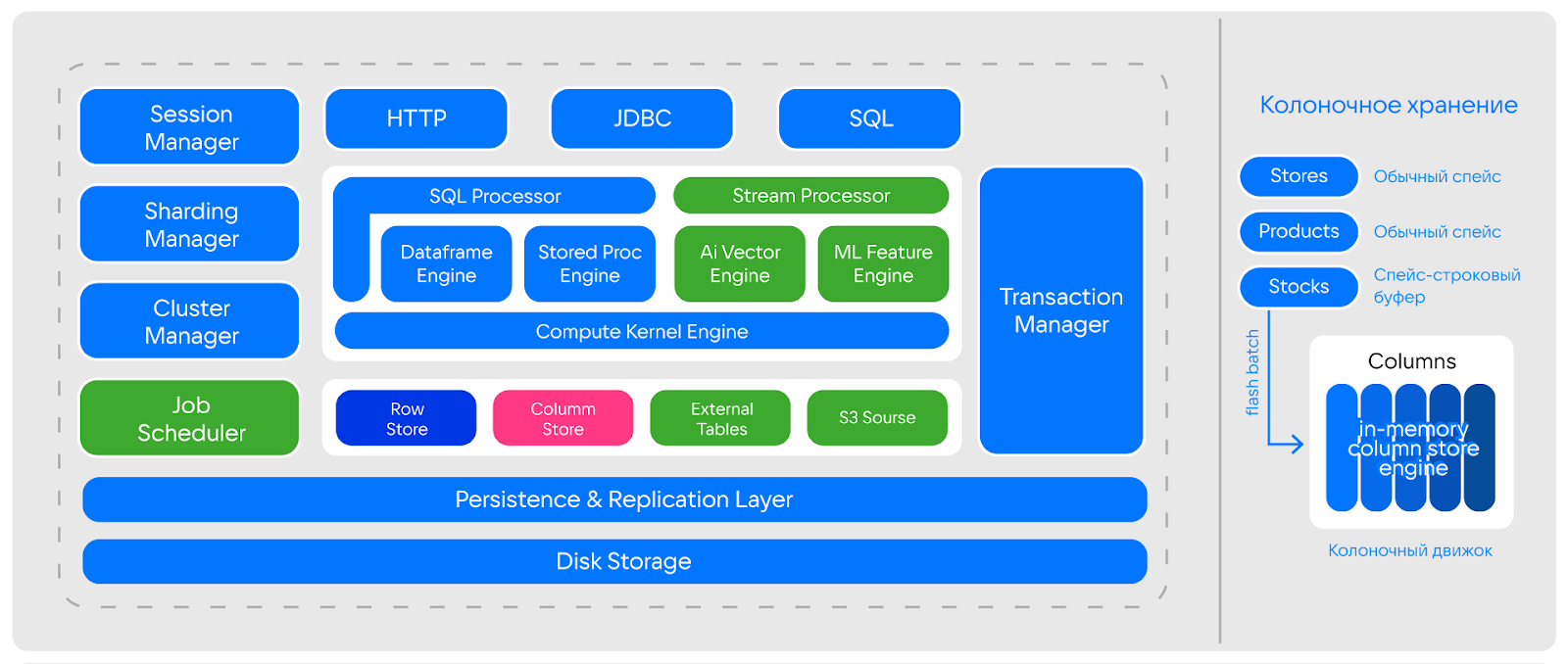
При этом работа над расширением возможностей инструмента на уровне архитектуры продолжается:
-
работаем над возможностью хранить и использовать векторы — у нас уже есть прототипы и успешные пилоты, в том числе многомерные векторы для приблизительного поиска;
-
разрабатываем обработчик потоков, который позволит реализовывать разные сценарии потоковой аналитики;
-
дорабатываем возможность интерпретировать внешние файлы в виде таблиц и использовать их как словари или внешние таблицы.
Протоколы
В Tarantool Column Store реализована поддержка сразу нескольких популярных протоколов.
Основным у нас является HTTP. Классически принято считать, что HTTP — медленный протокол. Но в нашем случае это не так: по результатам наших замеров на исполнение нескольких сотен тысяч запросов с соседнего сервера надо всего несколько сотен микросекунд. Причем за это время выполняется полноценный скан по данным.
Важно, что HTTP работает вне основного потока (TX Thread) — это отдельный HTTP-сервер (мы используем Tokio Runtime как один из самых производительных вариантов). Для работы с Tarantool он использует многопоточные чтения с использованием ReadView, благодаря чему чтение и обработка данных не зависят от основного транзакционного потока Tarantool tx и не тормозят его.
Tarantool Column Store также поддерживает протоколы семейства Apache Flight: Apache FlightRPC, Apache Flight SQL. Это колоночные протоколы, которые позволяют системам, включая Apache Stack и Big Data, работать с данными без их копирования. Например, если приложение на Python получает данные по такому протоколу, они могут быть сразу использованы, без копирования и конвертации. Это очень эффективно: из пайплайна обработки можно убрать двойное копирование, маппинг, сериализацию, десериализацию и другие лишние операции, на которые обычно может уходить более 70% процессорного времени работы систем.
Также мы ведем исследования в направлении использования Shared Memory в качестве способа передачи данных.
Помимо прочего, в ближайших релизах мы планируем добавить поддержку протоколов ODBC/JDBC и ADBC.
Что в итоге
Задач, для которых ни транзакционная (OLTP), ни аналитическая (OLAP) системы в чистом виде не подходят, становится все больше. Это вынуждает компании либо строить сложные архитектуры со множеством прослоек и налаживать избыточные пайплайны обработки данных, либо выбирать HTAP-системы, способные выполнять гибридную транзакционно-аналитическую обработку данных. И компании разумно все чаще выбирают именно HTAP-решения, которые заслуженно являются трендом не только 2024 года, но и, вероятно, следующих лет.
Важно, что HTAP-системы гибкие в контексте их применения — это хорошо видно на примере Tarantool Column Store. Наше решение комбинирует преимущества разных типов хранения данных, технологий, протоколов и функций. При этом оно обеспечивает высокую эффективность аналитической обработки с производительностью до 1,5 миллиарда сканов в секунду на одно ядро, то есть подходит для разных сценариев и профилей нагрузки.
Автор: Nikolay Karlov





