

Интересный факт: GPT-4o взимает по 170 токенов за обработку каждого тайла 512x512 , используемого в режиме высокого разрешения. При соотношении примерно 0,75 токенов на слово можно предположить, что картинка стоит примерно 227 слов, что всего в четыре раза меньше, чем в поговорке «картинка стоит тысячи слов».
(Кроме того, взимается 85 токенов за master thumbnail низкого разрешения каждого изображения, а изображения более высокого разрешения разбиваются на множество таких тайлов 512x512, но давайте ограничимся одним тайлом высокого разрешения.)
Но почему же 170? Необычное число, неправда ли? В своих ценах OpenAI указывает округлённые числа, например, $20 или $0,50, а в своих внутренних размерностях — степени двойки и тройки. Почему же в этом случае выбрано число 170?
Числа, которые без объяснений вставляют в кодовую базу, называют в программировании «магическими числами», и 170 кажется очевидным магическим числом.
И почему затраты на изображения вообще преобразуются в стоимость в токенах? Если бы это нужно было только для определения цены, то разве не удобнее было бы просто указать цену за тайл?
Что если OpenAI выбрала 170 не в рамках своей запутанной стратегии ценообразования, а потому что это в буквальном смысле так? Что если тайлы изображений действительно представлены в виде 170 последовательных векторов эмбеддингов? А если это так, то как реализовано?
Эмбеддинги
Первым делом стоит вспомнить, что модель трансформера работает с векторами, а не дискретными токенами. Входные данные должны быть векторами, в противном случае косинусный коэффициент, используемый внутри трансформера, не имел бы никакого смысла. Вся концепция токенов — это этап препроцессинга: текст преобразуется в токены, а токены преобразуются моделью эмбеддингов в векторы эмбеддингов, и только после этого они попадают в первый слой модели трансформера.
Например, внутри Llama 3 используется 4096 размерностей признаков. Рассмотрим предложение «My very educated mother just served us nine pizzas.». BPE преобразует его в 10 целочисленных токенов (с учётом точки), а затем каждый из них преобразуется моделью эмбеддингов в 4096-мерные векторы. В результате получается матрица 10x4096. Она и будет «реальными» входными данными для модели трансформера.
Но нет никакого закона, по которому эти векторы обязаны поступать из текстовой модели эмбеддингов. Эта стратегия хорошо работает для текстовых данных, но если наши данные находятся в другом формате, который мы хотим передать трансформеру, то можно просто использовать другую стратегию эмбеддингов.
Мы знаем, что OpenAI думала примерно так же, потому что в 2021 году компания выпустила модель эмбеддингов CLIP. CLIP выполняет эмбеддинги и текста, и изображений в одно пространство семантических векторов, что позволяет использовать косинусный коэффициент для поиска изображений, связанных с текстовыми строками, или изображений, семантически схожих с другими изображениями. Можете попробовать демо на Hugging Face, чтобы получить представление о том, как это работает:

Однако CLIP выполняет эмбеддинг всего изображения как одного вектора, а не 170 векторов. Значит, GPT-4o использует другую, более совершенную внутреннюю стратегию для описания изображений (а также видео, голоса и других типов данных; именно поэтому она считается «омнимодальной»).
Попробуем вычислить, что это за стратегия, в частности, для данных изображений.
Количество размерностей признаков
Давайте начнём с приблизительной оценки количества размерностей, которые используются внутри GPT-4o для описания векторов эмбеддингов. Мы не знаем точного числа, потому что это закрытая информация, но можем делать разумные предположения.
Похоже, OpenAI нравятся степени двойки, и иногда она добавляет множитель 3. Например, компания использовала 1536 для эмбеддингов ada-002 или 3072 для text-embedding-3-large. Известно, что GPT-3 везде использует 12288 размерностей. Вероятно, что в GPT-4o этот параметр или остался таким же, или увеличился.
Маловероятно, что при переходе от GPT-3 к GPT-4o количество эмбеддингов снизилось, но это возможно. Релизы наподобие GPT-4 Turbo оказались быстрее и дешевле, чем предыдущие версии, и это могло быть вызвано в том числе и снижением размерности эмбеддингов, если бенчмарки разработчиков показали, что уменьшение размера не снижает качество.
С учётом всего этого, есть вероятность, что количество используемых внутри GPT-4o размерностей признаков совпадает с одним из этих вариантов:
|
Размерность |
Простые делители |
|---|---|
|
1536 |
3⋅29 |
|
2048 |
211 |
|
3072 |
3⋅210 |
|
4096 |
212 |
|
12288 |
3⋅212 |
|
16384 |
214 |
|
24576 |
3⋅213 |
Предположу, что в качестве размерности векторов эмбеддингов GPT-4o использует значение 12288. На самом деле, не важно, ошиблись ли мы в 2 или 4 раза; те же самые рассуждения всё равно будут применимы.
Изображения эмбеддингов
Тайлы изображений — это квадраты, так что они, вероятно, представлены в виде квадратной сетки токенов. Число 170 очень близко к 13×13. Дополнительный токен может быть одним вектором эмбеддинга, кодирующим гештальт-образ всего изображения, аналогично CLIP (и схоже со стратегией компании по использованию «master thumbnail» из 85 токенов для каждого изображения).
Вопрос заключается в том, как нам перейти от 512x512x3 к 13x13x12288?
Стратегия 1: сырые пиксели
Вот крайне простой способ запихивания изображения в пространство векторов:
-
Делим изображение
512x512на сетку8x8из «минитайлов». -
Каждый минитайл имеет размер
64x64x3; делаем его плоским вектором с размерностью 12288. -
Каждый минитайл — это один вектор эмбеддингов.
-
Весь тайл изображения описывается 64 последовательными векторами эмбеддингов.
У такого подхода есть две проблемы:
-
64 ≠ 170, и
-
он крайне глуп.
«Крайне глуп», потому что нет никакого смысла выполнять эмбеддинг сырых значений RGB, а потом просто надеяться, что трансформер с этим всем разберётся. Трансформеры не особо приспособлены для работы с пространственной структурой 2D-изображений, особенно если их эмбеддинг выполнен таким тупым образом.
Чтобы понять, почему это так, представьте, что изображение сместилось на несколько пикселей влево. Векторное произведение между векторами эмбеддингов оригинала и смещённого изображения мгновенно уменьшится почти до нуля. То же самое произойдёт при изменении размера изображения.
В идеале нам бы хотелось, чтобы модель была устойчивой к таким преобразованиям; если говорить технически, она должна обладать трансляционной и масштабной инвариантностью.
Стратегия 2: CNN
К счастью, уже существует модель с такими характеристиками, уже более десятка лет успешно справляющаяся с обработкой данных изображений: Convolutional Neural Network. (свёрточная нейронная сеть). (Здесь я использую этот термин для описания семейства моделей глубокого обучения, в которых присутствуют свёрточные слои.)
Чтобы представить, какие у нас есть варианты, давайте рассмотрим классическую архитектуру CNN AlexNet, представленную в 2012 году:

Её базовые строительные блоки:
-
Свёрточный слой. Он сканирует изображение блоками размером k×k, обучая малую нейронную сеть.
-
Слой предвыборки (Max Pool Layer). Он тоже исследует блоки k×k, но просто берёт из каждого максимальное значение.
Углубляясь в слои сети, мы должны отметить две главных тенденции: высота и ширина становятся меньше, а количество «каналов» (иногда называемых «фильтрами») увеличивается. Это значит, что мы инкрементно перерабатываем множество низкоуровневых признаков в высокоуровневые концепции, пока в самом конце AlexNet не превратит всё изображение в какую-то простую категорическую концепцию, описывающую что-то наподобие «кошки» или «собаки». По сути, CNN — это воронки, выдавливающие из лимонов сырых пикселей лимонад семантических векторов.
Если воспользоваться этой натянутой аналогией, можно увидеть, почему CNN может превращать изображение в единый вектор эмбеддингов. Чтобы понять, как (и почему) CNN способна превратить изображение во множество векторов эмбеддингов, давайте рассмотрим чуть более новую (примерно 2018 год) архитектуру CNN, чуть более близкую по духу, необходимому нам для GPT-4o. Она называется YOLO, что расшифровывается как «You Only Look Once».

Здесь запись xN означает, что весь блок повторяется N раз. YOLOv3 в десять раз глубже AlexNet, но в некоторых аспектах очень на неё похожа. Архитектура её более современна: свёрточные слои со страйдом 2 вместо слоёв предвыборки для снижения размерности, остаточные слои для сохранения хороших градиентов в очень глубоких сетях и так далее.
Но основное отличие заключается в том, что она не редуцирует изображение до одного плоского вектора, а останавливается на 13x13. После этого не существует полностью связанных слоёв; на самом деле выходными данными YOLOv3 становятся 169 отдельных векторов, выстроенных в сетку 13x13; каждый из них имеет размерность 1024 и каждый описывает класс (а также данные ограничивающих прямоугольников, которые мы проигнорируем) объекта, найденного внутри или рядом с отдельной ячейкой сетки. Благодаря этому YOLO видит не только один объект в изображении, она может увидеть несколько за один проход. Отсюда и фраза «only look once» («смотришь только один раз»).
Эти примеры дают нам примерное представление о том, какой вид может (гипотетически) иметь CNN эмбеддингов изображений в GPT-4o. Теперь нам достаточно лишь сыграть в игру: как перейти от 512x512x3 к 13x13x12288 при помощи стандартных слоёв CNN?
Ходы в этой игре — это стандартные строительные блоки, которые мы видели в описанных выше архитектурах CNN. Можно выбирать типы слоёв и играть с такими гиперпараметрами, как размер ядра, длина страйда, стратегия паддинга и так далее. Стоит отметить, что мы игнорируем такие вещи, как остаточные слои, повторяющиеся блоки, нормализация батчей/слоёв и свёрточные слои 1x1, потому что они не влияют на общий размер тензора.
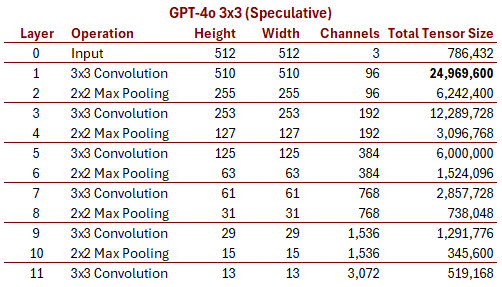
Наша задача: создать гипотетическую работающую архитектуру CNN, связывающую известный размер входных данных (изображения 512x512 с тремя цветовыми каналами RGB) со стандартной формой выходных данных (векторы эмбеддингов 13x13 с 12288 размерностями каждый).
Я попробовал множество разных вариаций, но большинство из них для соответствия требовало особых особых случаев в одном или нескольких слоях. Но потом я нашёл одну, которая изящно подошла без каких-либо особых случаев:

Красиво, не так ли? Она почти идентична AlexNet, и выполняет переход с 512 до 13 за пять идентичных повторяющихся блоков, одновременно учетверяя количество каналов с каждым блоком, чтобы получить на нижнем слое 12288. К сожалению, она кажется немного устаревшей из-за ядер 5x5 и слоёв предвыборки. В 2012 году AlexNet стала прорывом, но я бы удивился, если бы OpenAI использовала нечто подобное в 2024 году.
Вот альтернатива, которая почти подошла (получилось 12x12 вместо 13x13) и при этом остаётся близкой к более современной архитектуре YOLO:

Хотя это и невозможно доказать, подобные гипотетические архитектуры демонстрируют, что существуют реалистичные архитектуры CNN, способные представить изображение как сетку k×k векторов эмбеддингов.
Экспериментальная проверка
Действительно ли GPT-4o видит сетку 13x13 векторов эмбеддингов? Чтобы проверить это, придумал задачу, отдалённо напоминающую карты Зенера. Задача заключается в определении цвета и формы каждого символа на сетке в изображении.
Простая программа генерирует вот такие тестовые сетки:

Чтобы получить данные сравнения, я использовал следующий промт:
"""Divide this image into a {k}x{k} grid and describe the shape and color of
each cell. Report your results as a JSON array of arrays (no objects or row
labels) and use all lowercase."""Если гипотеза о сетке 13x13 верна, то GPT-4o должна справляться с этой задачей примерно до 13, после чего точность должна начать снижаться. CNN не буквально делит изображение на сетку, поэтому точность может начать снижаться и раньше, и может испытывать больше проблем с чётными размерами сеток, чем с нечётными, потому что ячейки не будут выровнены.
Однако на самом деле происходит не это. Точность идеальна для сеток 5x5 и меньшего размера (то есть 2x2, 3x3, 4x4), но после начинает быстро снижаться. К моменту, когда мы достигаем 13x13, тем же успехом можно было угадывать случайно.
Например, вот сетка 7x7:

Для неё GPT-4o вернул следующее:
[
["blue diamond", "purple triangle", "red plus", "purple circle", "orange square", "purple circle", "blue circle"],
["blue diamond", "red circle", "green plus", "red square", "orange diamond", "blue triangle", "purple plus"],
["blue diamond", "orange triangle", "red square", "orange square", "blue plus", "purple circle", "blue circle"],
["green diamond", "blue circle", "orange circle", "green circle", "purple diamond", "green triangle", "orange diamond"],
["purple square", "purple circle", "green plus", "green diamond", "green circle", "blue triangle", "purple triangle"],
["red plus", "red triangle", "purple circle", "blue triangle", "orange triangle", "red diamond", "orange diamond"],
["orange plus", "blue diamond", "green triangle", "green plus", "green triangle", "purple diamond", "purple square"]
]Она определил правильно 38⁄49 — точность 76%. Паттерн попаданий и промахов выглядит так (жёлтые — правильные, фиолетовые — ошибочные):

С ростом размера сетки точность продолжает деградировать, и когда мы достигаем сетки 13x13:

Результаты становятся не лучше, чем при угадывании:

Значит ли это, что я ошибался, предположив, что 169 описывают сетку 13x13? Да, ошибался. Моё разочарование безмерно и мой день испорчен.
«Великая трагедия науки: красивая гипотеза уничтожена уродливым фактом.» —Томас Гексли
Но результаты на сетке 5x5 дают нам подсказку. GPT-4o на самом деле может отслеживать до 25 уникальных объектов и их абсолютные позиции в изображении. Возможно, наша основная концепция верна и я ошибся только в размерностях. Можно с лёгкостью добавить ещё пару слоёв к нашей CNN, чтобы опуститься до 5x5 вместо 13x13:

Как можно структурировать выходные данные, чтобы достичь 170 токенов, если предположить, что используются только сетки 5x5 и меньше?
Пирамидная стратегия
Чтобы приблизиться и к 85, и к 170, можно предположить, что мы кодируем изображение серией всё более мелких уровней, как пирамиду. Мы начинаем с одного вектора эмбеддингов, описывающего гештальт-образ всего изображения, добавляем3x3, чтобы описать левую/среднюю/правую и верхнюю/среднюю/нижнюю части, затем добавляем 5x5, 7x7 и так далее.

Если мы остановимся на 7x7, то эта стратегия приведёт нас очень близко к 85 токенам master thumbnail:
12+32+52+72=1+9+25+49=84
И очень близко к 170, если мы добавим последнюю сетку 9x9:
12+32+52+72+92=1+9+25+49+81=165
Если мы добавим ситуативную сетку 2x2 для тайла 512x512 и предположим наличие для каждой особого токена <|image start|>, то получим идеальное совпадение:
1+12+32+52+72=1+1+9+25+49=85
1+12+22+32+52+72+92=1+1+4+9+25+49+81=170
В этой схеме не хватает ограничителей начала и конца строки, но я думаю, что это можно решить при помощи позиционного кодирования, аналогичного тому, как RoPE используется для кодирования позиционной информации текстовых токенов, но в 2D.
Приведённая выше гипотеза принимает только нечётные размеры сеток и выходит за рамки 5x5; учитывая то, что точность определения карточек Зенера начинает снижаться после сетки 5x5 , это не совсем совпадает с доказательством.
В качестве альтернативы мы можем взять все сетки (чётные и нечётные) до 5x5:

При таком подходе мы получаем 55 токенов:
12+22+32+42+52=55
Если мы предположим, что на минитайл используется по три токена с токеном-разделителем между каждым, то мы можем дойти до 170:
3×(12+22+32+42+52)+5=170
Это не совсем соответствует с точки зрения чисел, но хорошо совпадает с эмпирическими результатами. Пирамидная стратегия интуитивно понятна, она похожа на самый «очевидный» способ кодирования пространственной информации на разных уровнях зума и может объяснить хорошую точность на сетке 5x5 и сильное снижение на сетке 6x6 и выше.
Меня сводит с ума то, что каждая гипотеза так мучительно близка к объяснению всего, но числа не совсем подходят… Тем не менее, пирамидные стратегии — это лучшее, что я пока смог придумать.
Оптическое распознавание символов
Ни одна из приведённых выше гипотез не объясняет того, как GPT-4o выполняет OCR. CLIP нативно не очень хорошо справляется с OCR, по крайней мере, при больших блоках текста. (Но то, что она может делать это, поражает — очевидный пример эмергентной способности!) Однако GPT-4o способна выполнять высококачественное OCR: она может транскрибировать длинные блоки текста, читать рукописный текст или текст, который был смещён, повёрнут, спроецировал или частично скрыт.
Важно помнить, что современные движки OCR отлично справляются с подчисткой изображений, поиском ограничивающих прямоугольников и полос символов, после чего они прогоняют специализированные модели распознавания символов по этим полосам, по одному символу или слову за раз. Это не просто большие CNN.
Предполагаю, теоретически OpenAI могла бы создать действительно настолько хорошую модель, но это не соотносится с относительно низкой точностью распознавания сетки карточек Зенера. Если уж модель не может считать 36 символов из ровной сетки 6x6 в изображении, то она определённо не справится с точным распознаванием нескольких сотен текстовых символов.
У меня есть простая теория, объясняющая это расхождение: думаю, OpenAI использует готовый инструмент OCR наподобие Tesseract (или с большей вероятностью какой-то проприетарный современный инструмент) и передаёт распознанный текст в трансформер вместе с данными изображений. По крайней мере, я бы поступил так.
Это объяснило бы, почему первые версии можно было так легко запутать скрытым в изображениях текстом: с их точки зрения этот текст был частью промта. (Сейчас эту проблему устранили; GPT-4o хорошо справляется с игнорированием зловредных промтов, скрытых внутри изображений.)

Однако это не объясняет того, почему отсутствуют изменения на токен для текста, найденного в изображении.
Любопытно, что на самом деле отправлять текст как изображения эффективнее: изображение 512x512 с небольшим, но читаемым шрифтом может запросто уместить в себе текста на 400-500 токенов, но вы заплатите всего за 170 входных токенов плюс 85 за master thumbnail, то есть в сумме 255 токенов — гораздо меньше, чем количество слов в изображении.
Эта теория объясняет повышенную задержку при обработке изображений. CNN работала бы, по сути, мгновенно, но стороннее OCR добавляет лишнее время. Кстати (не скажу, что это что-то доказывает), в окружении Python, используемом интерпретатором кода OpenAI, установлен PyTesseract. Можно в буквальном смысле просто попросить его обработать любое загруженное изображение PyTesseract, чтобы получить ещё одно мнение.
Заключение
Итак, на основании единственного факта об использовании компанией OpenAI магического числа 170 мы сделали множество предположений.
Однако похоже, что это абсолютно допустимый подход для сопоставления тайлов изображений с векторами эмбеддингов, во многом соответствующий другим архитектурам CNN, например, YOLO.
Поэтому я не думаю, что 170 токенов — это просто аппроксимация, используемая для оплаты приблизительного объёма вычислительных ресурсов, необходимых для обработки изображения. И я не думаю, что модель выполняет конкатенацию слоёв для объединения изображения и текстовых данных, как это делают некоторые другие мультимодальные модели.
Нет, я считаю, что GPT-4o в буквальном смысле представляет изображения 512x512 в виде 170 векторов эмбеддингов, используя архитектуру CNN, состоящую из смеси CLIP и YOLO, чтобы выполнить эмбеддинг изображения напрямую в пространство семантических векторов трансформера.
Когда я начинал писать эту статью, то был полностью уверен, что уже полностью «взломал» систему и выясню, что 170 токенов предназначены для сетки 13x13 и одного токена гештальт-образа. Для меня оказалась совершенно неожиданной деградация точности задачи с карточками Зенера после 5x5 — как бы модель ни была устроена внутри, похоже, она гораздо меньше, чем 13x13.
Тем не менее, аналогия с YOLO выглядит правдоподобно, а точность выполнения задачи с карточками Зенера в формате 5x5 практически подтверждает, что мы имеем дело с некой сеткой. Эта теория имеет большую предсказательную силу и в других областях: например, она объясняет, почему GPT-4o способна обрабатывать несколько изображений и выполнять задачи наподобие сравнения двух изображений. Она объясняет то, что модель способна видеть множественные объекты на одном изображении, но «утомляется» когда в сцене их слишком много. Она объясняет, почему GPT-4o крайне смутно представляет абсолютное и относительное расположение отдельных объектов в сцене и почему она не может точно подсчитать количество объектов на изображении: если объект попадает в две соседние ячейки сетки, то в обеих активируются одни и те же классы, так что модель не уверена, один ли это объект или два.
Забавно, что эта теория не может дать чёткий ответ на вопрос, который и сподвиг меня на написание статьи: почему именно 170 токенов? Моей лучшей догадкой стала пирамидная теория (1x1 + 2x2 + 3x3 + 4x4 + 5x5), но и она не особо красива.
Мне бы хотелось узнать, есть ли у кого-нибудь теория, соответствующая данным чуть лучше (а может, и реальное знание; если, конечно, его разглашение не нарушает NDA!)
Постскриптум: проделки с альфа-каналом
При работе над этим проектом я также заметил, что GPT-4o игнорирует альфа-канал, что приводит к довольно контринтуитивному поведению.
Когда я говорю «игнорирует» я не имею в виду, что она избавляется от прозрачности, выполняя её композитинг на какой-то стандартный фон, например, как редактор изображений может преобразовывать PNG в JPG. Нет, я имею в виду, что она в буквальном смысле просто берёт каналы RGB и игнорирует альфа-канал.
Мы можем проиллюстрировать это четырьмя специально подготовленными изображениями. Для удобства я покажу эти изображения поверх шахматного паттерна, а сами они имеют прозрачные фоны. Однако половина из них имеет прозрачные чёрные фоны, а другая половина — прозрачные белые фоны.
Что я подразумеваю под «прозрачным чёрным» и «прозрачным белым»? Когда мы записываем цвет RGBA четырьмя байтами, байты RGB по-прежнему остаются в изображении, даже если альфа равна 100%. То есть (0, 0, 0, 255) и (255, 255, 255, 255) — это в каком-то смысле разные цвета, хотя ни в одной из ситуаций корректный рендерер не отобразит из по-разному, потому что они полностью прозрачны.
Давайте спросим GPT-4o, что она «видит» на этих четырёх изображениях:

Чёрный текст на прозрачном чёрном фоне
GPT-4o читает это как «»

Чёрный текст на прозрачном белом фоне
GPT-4o читает «ENORMOUS»

Белый текст на прозрачном чёрном фоне
GPT-4o читает «SCINTILLA»

Белый текст на прозрачном белом фоне
GPT-4o читает «»
Что здесь происходит? Возникает паттерн, что GPT-4o может читать текст тогда и только тогда, когда его цвет отличается от «цвета» прозрачного фона.
Это говорит нам, что GPT-4o не обращает внимания на альфа-канал и смотрит только на каналы RGB. Для неё прозрачный чёрный — это чёрный, а прозрачный белый — белый.
Мы можем показать это ещё нагляднее, если изменим изображение, сохранив три канала RGB и присвоив альфа-каналу значение 100%. Вот небольшая функция Pillow для этого:
from PIL import Image
def set_alpha(image, output_path, alpha_value):
# копируем изображение и преобразуем его, чтобы оно точно было в RGBA
image = image.convert("RGBA")
# присваиваем альфа-каналу каждого пикселя заданное значение
pixels = image.getdata()
new_pixels = [(r, g, b, alpha_value) for r, g, b, a in pixels]
image.putdata(new_pixels)
return imageПри помощи этого кода я создал два показанных ниже изображения; они содержат идентичные данные RGB и различаются только в альфа-канале:

Альфа-канал = 255

Альфа-канал = 0
GPT-4o без проблем увидела спрятанного утконоса:

Можете попробовать скачать изображение hidden_platypus.png из оригинала статьи и скинуть его в ChatGPT; модель опишет его правильно. Стоит также отметить, что изображение весит 39,3 КБ, то есть имеет тот же размер, что и platypus.png, хотя сжатие PNG должно было сделать его гораздо меньше, если бы это было полностью пустое прозрачное изображение. Или можно использовать приведённую выше функцию, чтобы вернуть альфа-каналу значение 255 и восстановить исходное изображение.
Не знаю, баг ли это, но точно неожиданное поведение; на самом деле, наверно, злонамеренный пользователь может передать так информацию напрямую GPT-4o в обход людей. Однако GPT-4o гораздо лучше справляется с распознаванием и игнорированием зловредных промтов, скрытых в изображениях, чем GPT-4v:

(Другие примеры успешного обнаружения и игнорирования скрытых в изображениях зловредных промтов моделью GPT-4o можно найти в моей галерее тестовых изображения GPT-4o, сгенерированной моей утилитой image_tagger.)
Так что, даже если это и баг, не совсем понятно, как его можно злонамеренно использовать. Но всё равно было бы менее неожиданно, если бы GPT-4o «видела» то же, что видит человек в браузере.
Автор: PatientZero






{kind=link}