

С увеличением сложности ИТ-систем все больше становится очевидной ограниченность привычных реализаций с простой архитектурой компонентов. Особенно это заметно в случае систем, которые должны стабильно работать с большими и интенсивными нагрузками.
Чтобы понять это, достаточно рассмотреть механику разворачивания большинства высоконагруженных систем. Например, разобрать построение системы авторизации пользователей для последующей сквозной аналитики авторизации/аутентификации между связанными сервисами компании.
Разбираемся на примере клиентского кейса, как может выглядеть такая система в части хранения данных, почему для таких задач оптимальна комбинация реляционной БД и Tarantool, а также показываем, какие показатели может обеспечить система с Tarantool.
Исходная задача
Построение систем авторизации пользователей для последующей сквозной аналитики авторизации/аутентификации между связанными сервисами — практически типовая задача для крупных компаний с развитым ИТ-ландшафтом и большим продуктовым портфелем. В том числе запросы на проработку таких систем часто поступают команде Tarantool от потенциальных клиентов. Поэтому в рамках статьи мы будем оперировать не выдуманными запросами и условными цифрами, а реальными требованиями одного из наших заказчиков.
Итак, один из клиентов обратился к нам со следующей задачей и требованиями к ее реализации.
Задача
Реализовать систему для авторизации пользователей для решения задачи сквозной авторизации/аутентификации между связанными сервисами компании.
При этом аутентификация может происходить по разным идентификаторам клиента:
-
Client_id;
-
серия/номер паспорта;
-
СНИЛС;
-
номер телефона;
-
адрес электронной почты и другим.
Контекст
Клиент предполагал, что к моменту запуска в прод количество пользователей будет достигать 50 миллионов человек, поэтому проектируемая система должна быть готова к высоким нагрузкам. При этом бизнес ожидал увеличения количества активных пользователей до 100 миллионов. Таким образом, уже на старте разработки надо учитывать не только текущую нагрузку, но и предусматривать возможность кратного масштабирования.
Нефункциональные требования
С учетом контекста и требуемой функциональности клиенту также было важно, чтобы на пике активного использования сервиса система могла обрабатывать до 100 тысяч запросов в секунду и обеспечивать скорость ответа до 100 мс.
Данные о пользователе (почта, пароль, ФИО) весят мало (несколько байтов), поэтому объем операционных данных предполагался на уровне 50 ГБ.
Варианты реализации
Архитектурно такую систему можно реализовать несколькими способами. Сразу отмечу, что основной акцент при рассмотрении будем делать именно на реализацию в части хранения данных и обращения к ним, поскольку проработка логики сервиса всегда остается на стороне разработчика проекта.
Вариант 1. Система с реляционной БД
В данном случае реализация предельно простая:
-
Используем реляционную базу данных.
-
Описываем схему пользователя.
-
Рядом поднимаем один или несколько сервисов на Go с описанной бизнес-логикой.
-
Перед сервисами ставим балансировщик.
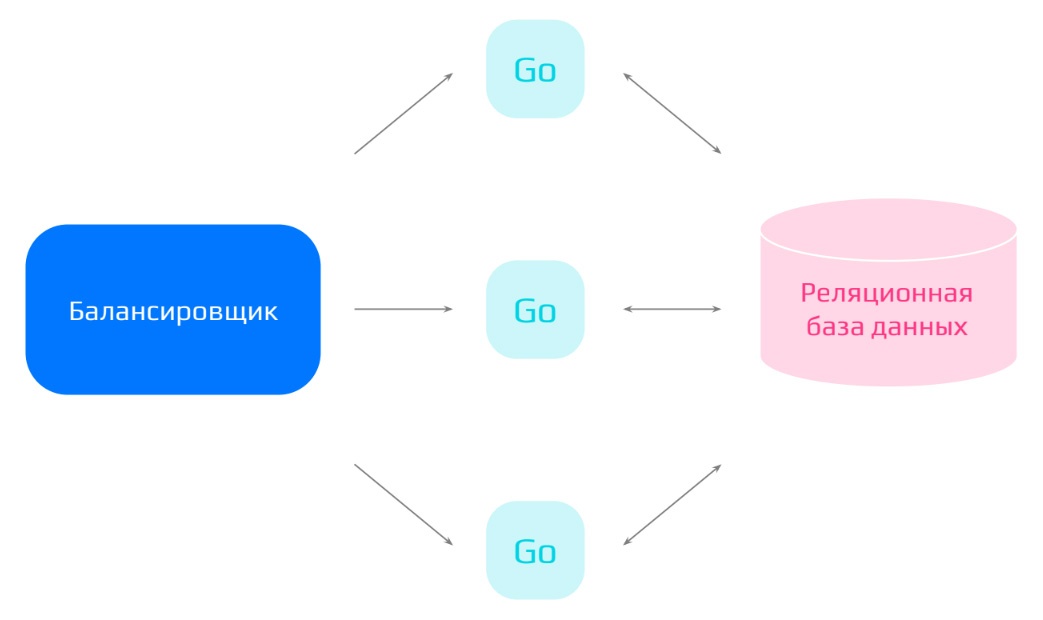
У такой реализации несколько преимуществ:
-
Реляционные БД активно и повсеместно используют. О них много информации в открытом доступе, то есть легко получить нужную экспертизу.
-
Реляционные БД сохраняют ACID-свойства транзакций, чем обеспечивают их надежность.
Вместе с тем есть и минусы:
-
Систему будет сложно масштабировать из-за ограничений на производительность и мощность серверов.
-
Изменения схемы данных затруднительны и требуют больших ресурсов.
-
При высоких нагрузках с производительностью и отзывчивостью системы могут возникать проблемы.
Из-за такой комбинации недостатков вариант очевидно не подходит для сервиса, работающего с постоянными высокими нагрузками.
Вариант 2. Система с реляционной БД и кэш-сервисами
В качестве оптимизации можно улучшить первый вариант, добавив к каждому сервису на Go отдельные кэши. В таком случае данные уже авторизованных пользователей будут храниться в кэшах, и запросы от них будут обрабатываться быстрее и с меньшей нагрузкой на ядро системы.
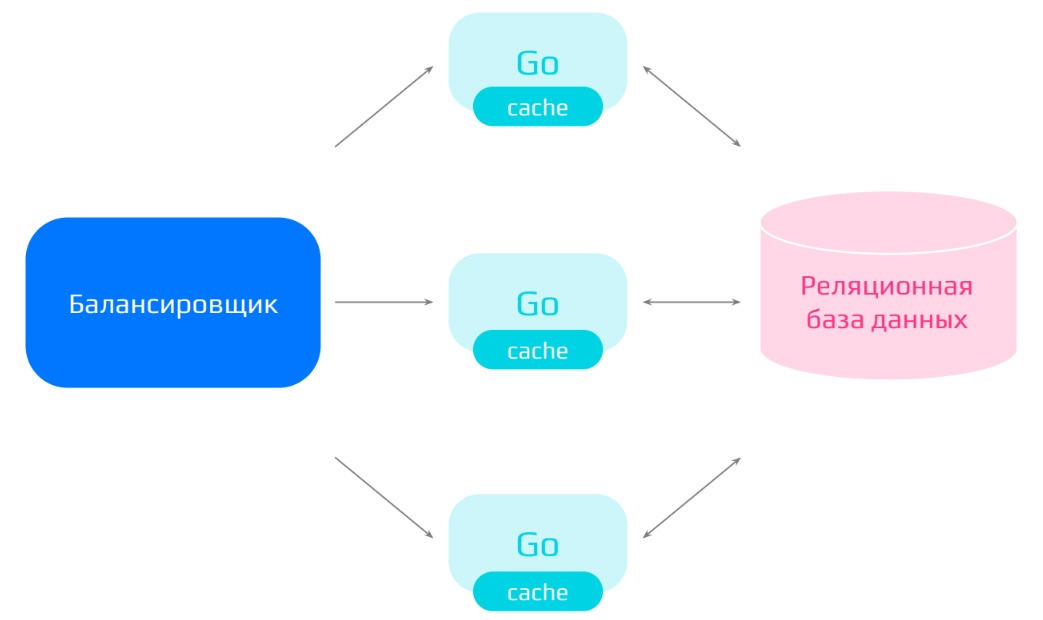
Из этого следуют и преимущества реализации:
-
Производительность системы авторизации повышается.
-
Задержки сокращаются.
-
В части выбора стратегии использования система становится более гибкой.
Вместе с тем подобная оптимизация скрывает в себе и некоторые недостатки:
-
Использование дополнительной системы усложняет решение и повышает требования к согласованности данных в кэше и реляционной базе данных.
-
Данные в кэше могут застревать, что может привести к нарушению их целостности и актуальности.
-
Для развертывания кэша нужна дополнительная инфраструктура.
Вариант 3. Системы с реляционной БД и общим внешним кэшем
Помимо варианта с выделением отдельного кэша под каждый сервис, также возможна архитектура, в которой рядом с реляционной БД будет один большой кэш.
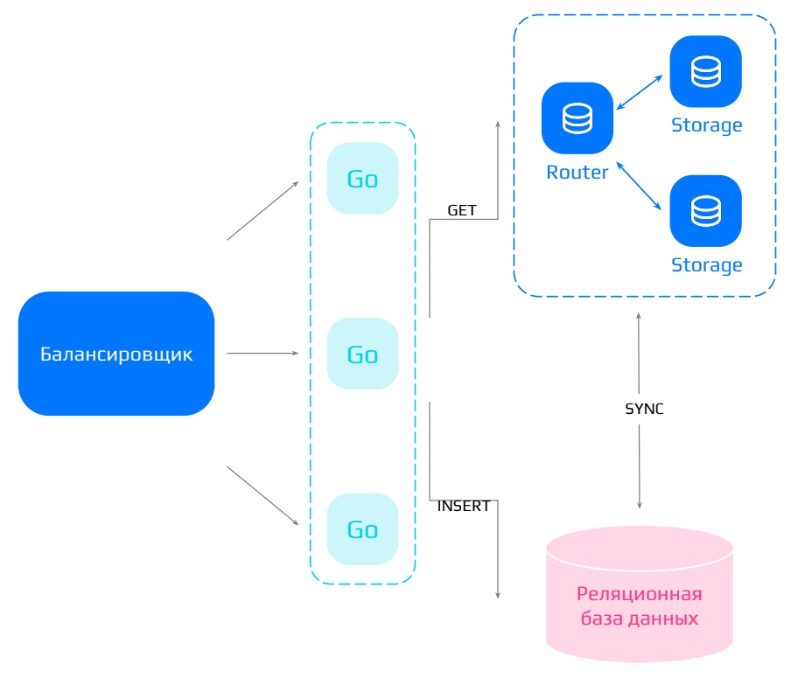
В таком случае можно реализовать следующий сценарий взаимодействия пользователей с системой:
-
запросы на добавление данных будут идти сразу в реляционную БД;
-
будет процесс, синхронизирующий данные в кэше и самой БД;
-
запросы на чтение в первую очередь будут приходить на отдельно стоящий большой кэш.
Преимущества такой реализации в высокой скорости обработки запросов, возможности гибкого горизонтального масштабирования, надежности и производительности.
Ключевым в данном случае является выбор инструмента для построения кэша: он должен обеспечивать высокую скорость обработки запросов, справляться с их большим массивом и работать без сбоев.
Под эти требования подходит Tarantool — отказоустойчивое распределенное Key-value-хранилище, которое можно гибко адаптировать под разные задачи и сценарии использования. В том числе в Tarantool можно строго задать схему данных с указанием вторичных индексов. В рамках рассматриваемого кейса также важно, что Tarantool поддерживает ACID-транзакции, гарантирует сохранение данных на диске, легко масштабируется как вертикально, так и горизонтально за счет встроенного модуля vshard.
Вместе с тем очевидно, что построение такой системы с реляционной БД и Tarantool в качестве единого кэша не лишено недостатков. Во-первых, столь массивную систему может быть сложно строить и администрировать. Во-вторых, работа с Tarantool требует экспертизы, которую многим приходится получать с нуля.
Выбор решения
При выборе варианта реализации рационально искать баланс между получаемым профитом и сопутствующими сложностями. Поэтому третий вариант предпочтительнее. Безусловно, он не лишен недостатков, но потенциальные трудности работы с Tarantool отчасти нивелируют подробная документация к инструменту и поддержка комьюнити. Одновременно с этим такая реализация полностью отвечает изначальным требованиям проекта.
Компоненты реализации и необходимый стек
Чтобы реализовать запрашиваемую систему, понадобятся:
-
Tarantool,
-
сервисы с бизнес-логикой на Go,
-
коннектор Go-Tarantool для обеспечения взаимодействия между сервисами с бизнес-логикой и Tarantool,
-
К6 для нагрузочного тестирования.
Для реализации приложения вместе с Tarantool мы также использовали три модуля:
-
Vshard,
-
Migration,
-
CRUD.
Vshard
Vshard — компонент, который обеспечивает распределенное хранение данных и горизонтальное масштабирование приложения на Tarantool.
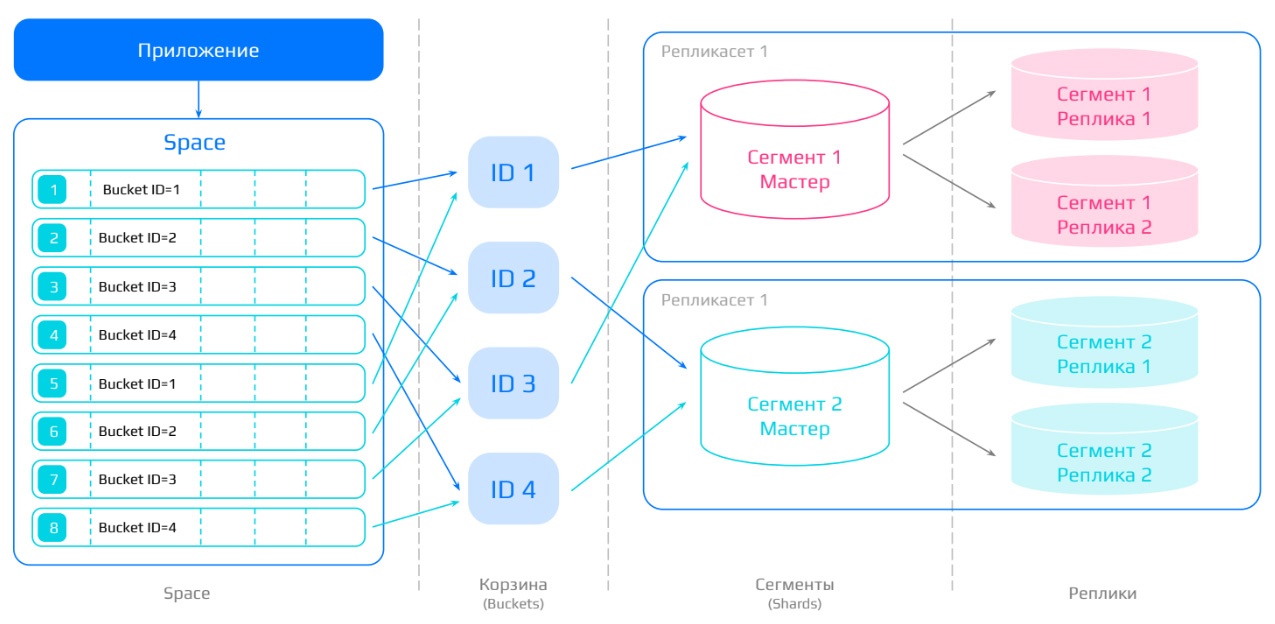
Ключевая особенность vshard в том, что он виртуализирует уровень хранения данных: поверх физических хранилищ поднимаются виртуальные хранилища (бакеты), и уже по ним распределяются записи. Пользователю не нужно думать о том, что и на каком физическом узле лежит.
Это позволяет легко масштабировать систему: при необходимости достаточно добавить физическое хранилище — и vshard автоматически начнет его задействовать под нагрузки.
Migrations
Migrations — компонент, который позволяет применять изменение схемы данных на распределенном кластере.
Благодаря модулю Migrations управлять схемой данных можно с помощью небольшого Lua-кода с указанием Space, описанием необходимых полей и созданием двух индексов:
-
основного — для поиска пользователей по почте;
-
вторичного — для корректной работы модуля vshard.
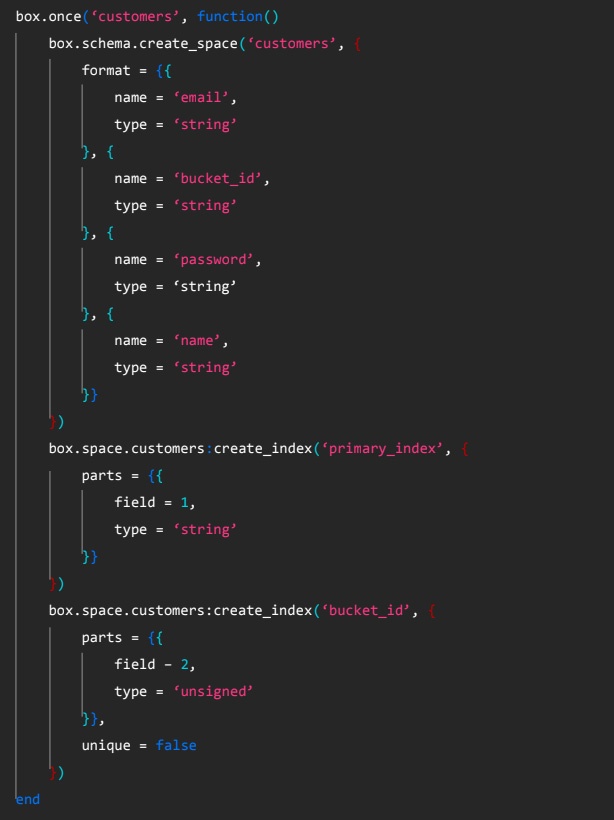
CRUD
CRUD — компонент, который позволяет выполнять CRUD-операции на кластере в Tarantool.
Со стороны Tarantool для применения CRUD мы можем у модуля вызвать Select, передав название Space и параметры поиска, либо сделать Invert object, указать название Space и передать объект, необходимый для вставки.

По такому же принципу можно работать и со стороны Go.
Реализация Go service
В рамках примера нам достаточно простого сервиса на Go без сложной логики и десятков компонентов.
Фактически нам достаточно описания трех этапов:
-
Установка соединения с кластером.
-
Описание ручки-логина.
-
Описание реализации ручки-логина.
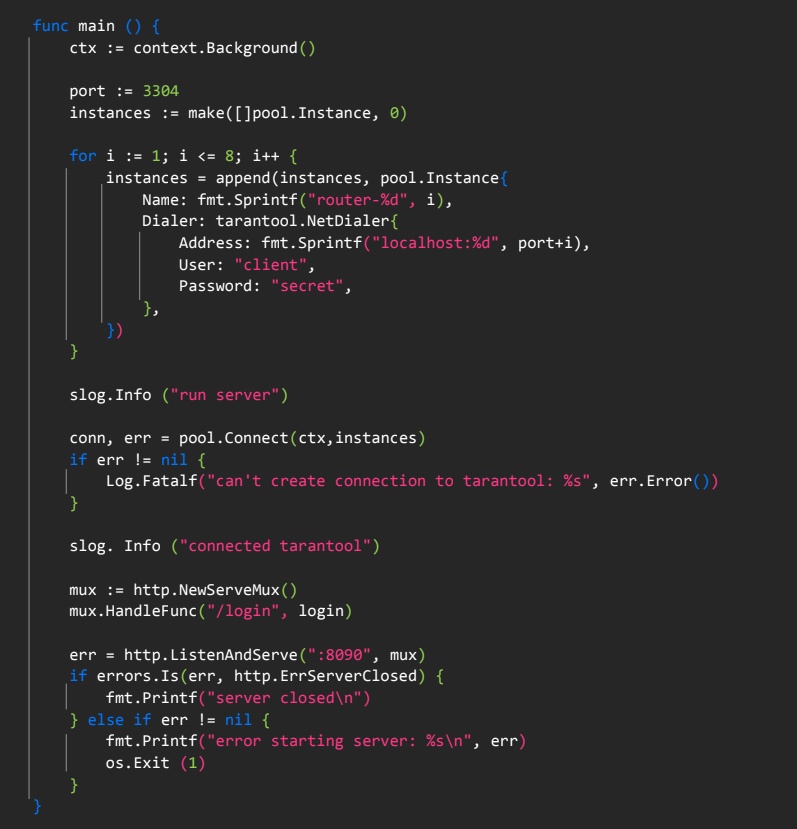
Установка соединения с кластером
Для соединения с Tarantool достаточно описать параметры подключения к каждому инстансу. Так, передав адрес, логин и пароль пользователя, под которым будут выполняться запросы, мы с помощью pool.connect создаем соединение.
Выбор в пользу pool.connect обусловлен тем, что он берет на себя задачу балансировки запросов между инстансами Tarantool, то есть пользователю не надо самостоятельно придумывать методы балансировки.
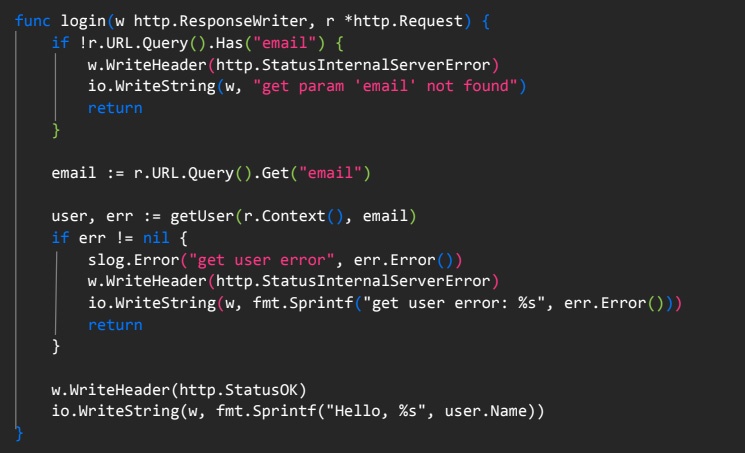
Описание ручки-логина
Для описания ручки-логина также достаточно простого набора команд.
Ключевое здесь — мы напрямую обрабатываем переданный параметр почты пользователя и после отдаем метод GetUser, в котором обращаемся к Tarantool и получаем данные. То есть в случае ошибки пользователь получает соответствующее уведомление, в случае успеха выдаем токен или отображаем приветственное сообщение (как в нашем случае).
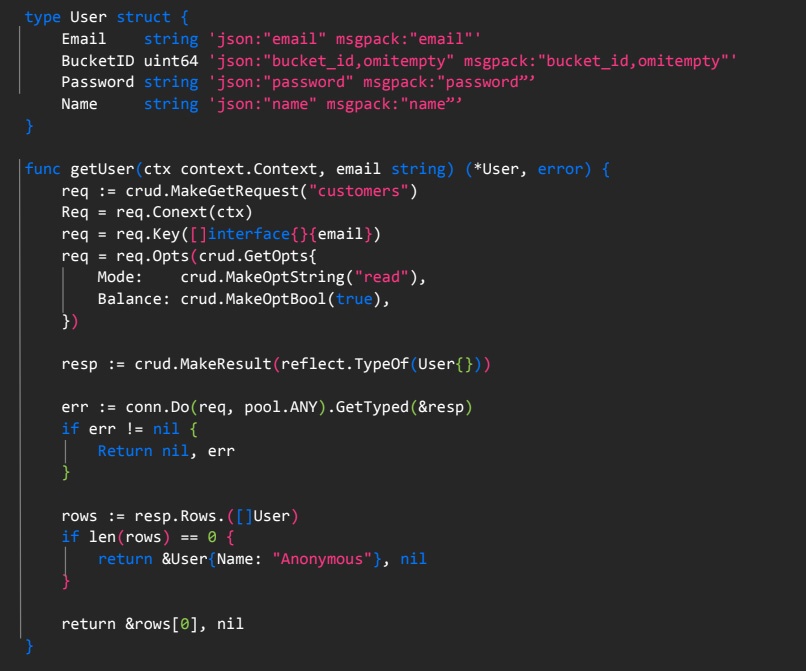
Описание реализации ручки-логина
С ручкой, обеспечивающей взаимодействие с Tarantool, тоже все просто.
-
Описываем структуру пользователя и в самой ручке составляем запросы, которые нужно выполнить.
-
С помощью CRUD составляем запрос на Get, указываем название Space, передаем необходимые параметры (контекст и почта пользователя).
-
В опциях настраиваем поведение запроса: указываем, что нужен режим чтения, чтобы запрос поступал на реплику. При этом, поскольку репликасет в нашем случае состоит из одного мастера и одной реплики, выставляем параметр Balance true, чтобы запросы выполнялись и на мастере.
-
Отправляем запрос Pull any в Tarantool. После обрабатываем ответ и полученные данные.
Первые итоги: нагрузочное тестирование
Для проверки разрабатываемой системы в боевых условиях разворачиваем в VK Cloud стенд:
-
3 виртуальные машины по 8 CPU и 16 ГБ RAM;
-
кластер Tarantool: 4 репликасета (4 мастера и 4 реплики) и 8 роутеров.
После этого запускаем сами тесты.
В итоге при средней нагрузке как мастера, так и реплики обрабатывают около 16 000 запросов в секунду — то есть суммарно около 120 000 запросов в секунду.
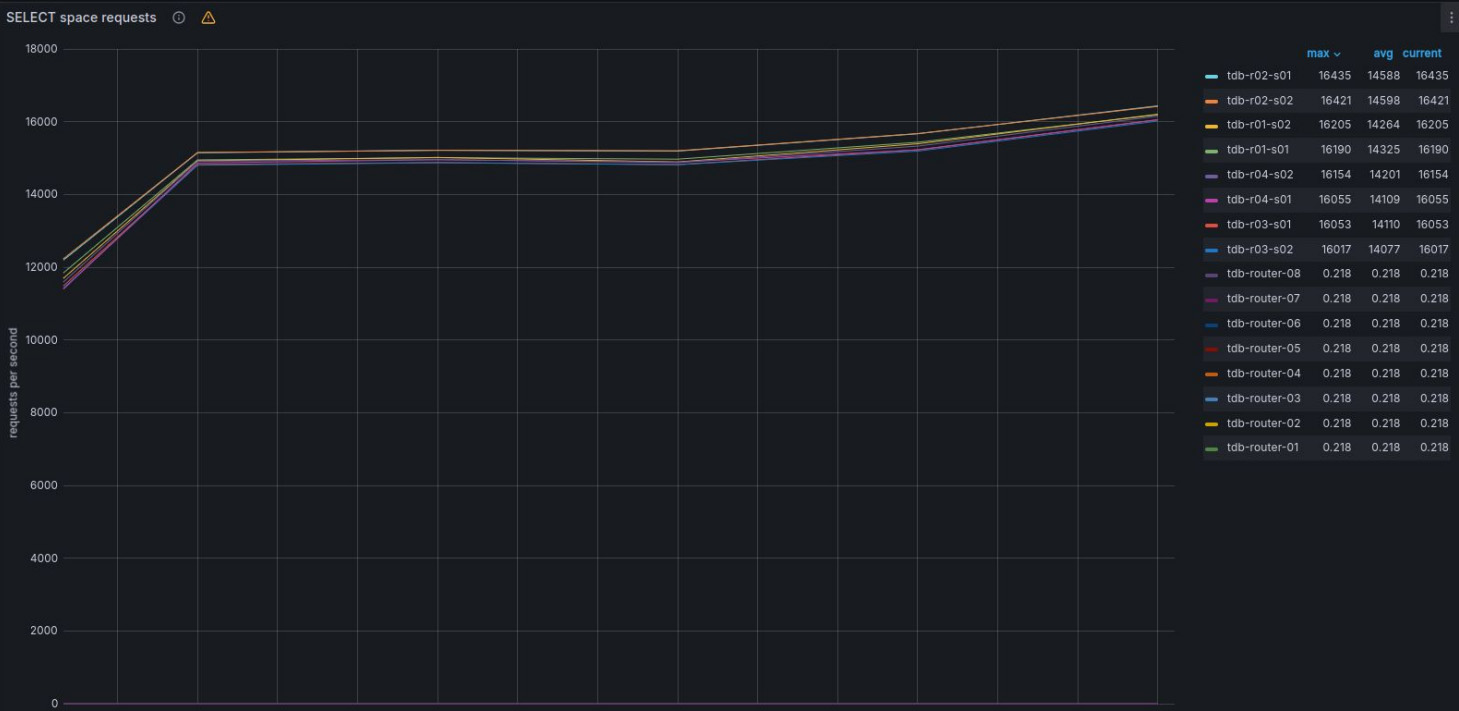
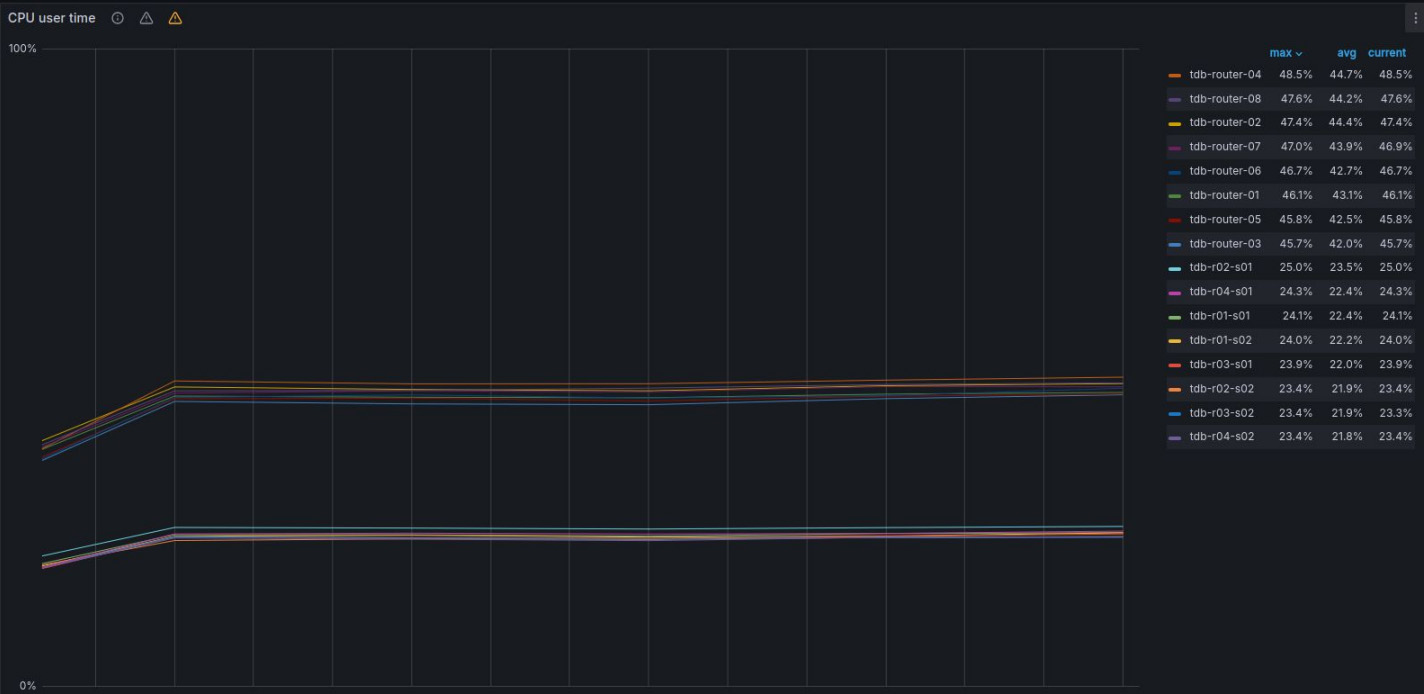
И такие метрики не предел кластера. Так, хранилища на пике потребляли всего 25% ресурсов процессора, а роутеры — около 50%.
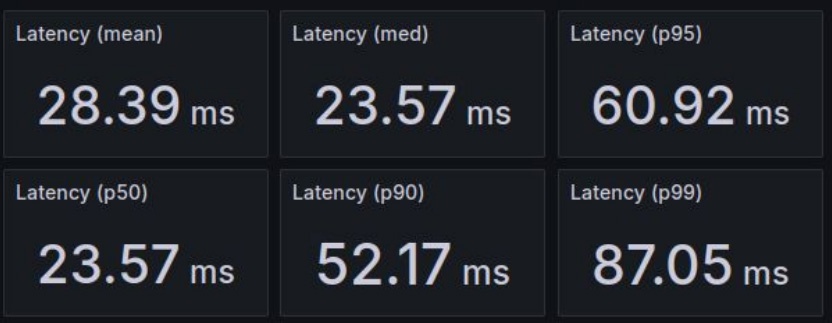
К тому же скорость обработки запросов вписывается в изначально заявленные требования (не более 100 мс).
Примечание: Важно, что такие системы легко масштабируются без ущерба показателям производительности. Если надо увеличить RPS, добавляем сторадж. Если нужно распределить нагрузку по ВМ, добавляем роутеры.
Итог
Построение высоконагруженных сервисов и систем — челлендж, с которым сталкивается все больше команд. И успех решения такой задачи, как правило, зависит от двух факторов:
-
Правильный выбор схемы реализации.
-
Подбор инструментов, отвечающих функциональным и нефункциональным требованиям проекта.
Наш опыт показал, что использование Tarantool в комбинации с Go позволяет строить высокопроизводительные системы с отличной отзывчивостью и масштабируемостью. Причем на этом сценарии применения Tarantool не ограничены благодаря гибкости и широкому продуктовому портфелю инструментов. Tarantool можно применять для ускорения распределенных вычислений, гибридной транзакционно-аналитической обработки больших данных, оперативного кэширования и не только. Причем даже в рамках одной реализации инстансы Tarantool можно задействовать для разных задач: Key-value-хранилище, кэш и основное хранилище.
Автор: Евгений Левашов





