

Сегодня мы посмотрим, как маленькие оптимизации в нужных местах приложения могут неплохо повысить его производительность. Убрали создание лишнего итератора в одном месте, избавились от упаковки в другом, а в итоге получается результат, несоизмеримый с правками.
Сквозь всю статью красной нитью будет протянута одна простая, хоть и не новая мысль, которую я прошу вас запомнить.
Преждевременные оптимизации — зло.
Позвольте пояснить. Бывает так, что оптимизация и читаемость идут немного в разных направлениях. Код может оптимальнее работать, но его тяжелее читать и поддерживать. И наоборот — код легко читается и модифицируется, но есть какие-то проблемы с производительностью. Поэтому важно понимать, чем вы готовы пожертвовать в том или ином случае.
Вы можете прочитать статью, кинуться править кодовую базу проекта и… не получить никаких улучшений характеристик производительности. Зато ваш код станет более сложным.
Именно поэтому (а впрочем, лучше всегда) к делу стоит подходить с холодной головой. Здорово, если вы будете знать узкие места приложения, где оптимизации смогут вам помочь. Если таких мест вы пока не знаете, на помощь придут различного рода профилировщики. Они могут предоставить большой объём информации о вашем приложении. В частности, описать его поведение в динамике: экземпляров какого типа создаётся больше всего, сколько времени приложение проводит в сборке мусора, как долго выполняется тот или иной фрагмент кода и т.п. Здесь хочу похвалить два инструмента JetBrains: dotTrace и dotMemory. Работа с ними удобна и, как правило, интуитивно понятна, информации много, она отлично визуализирована. JetBrains, вы крутые!
Но вернёмся ближе к нашим оптимизациям. На протяжении статьи мы разберём несколько кейсов, с которыми пришлось столкнуться и которые показались мне наиболее интересными. Каждое из описанных изменений давало положительный результат, так как было сделано в узких местах приложения, отмеченных профилировщиками. К сожалению, результатов изменения производительности от каждой конкретной правки у меня не осталось, но общий результат оптимизации будет приведён в конце статьи.
Примечание. В данной статье речь идёт про работу с .NET Framework. Как показывает практика (см. пример с Enum.GetHashCode), в некоторых моментах работа одного и того же участка кода на C# под .NET Core / .NET может быть более оптимальной, чем под .NET Framework.
А что, собственно, оптимизируем?
Советы, описанные в статье, актуальны для любого .NET приложения. Конечно, как я писал выше, особенно полезными правки кода будут тогда, когда делаются в узких местах приложения.
Сразу хочу отметить, что мы не будем вести какие-то абстрактные теоретические рассуждения. В таком ключе советы в духе "поменяй код, чтобы сэкономить создание одного итератора" выглядели бы максимально странно. Все проблемы, про которые будем сегодня говорить, выявлены по результатам профилирования статического анализатора PVS-Studio для C#. Основной целью профилирования было сокращение времени анализа.
После начала работ быстро стало ясно, что у анализатора большие проблемы со сборкой мусора: она занимала значительное время. На самом деле, мы знали это и раньше, просто убедились в очередной раз. К слову, ряд оптимизаций анализатора был проделан ранее, про что есть отдельная статья.
Тем не менее, проблема всё ещё была актуальной.
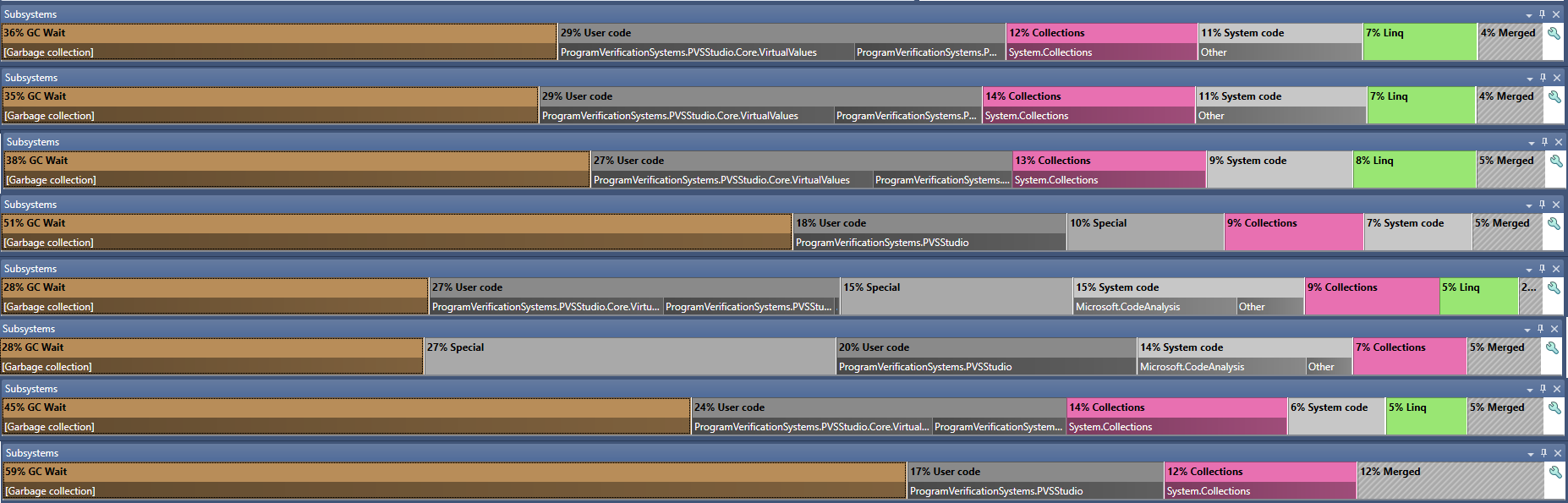
Посмотрите на скриншот ниже (полноразмерное изображение здесь). Это результат профилирования анализатора PVS-Studio C#, полученный в ходе анализа им одного из проектов. 8 полос — 8 потоков, которые использовались анализатором. Как видно, в каждом потоке значительную часть времени занимала работа сборщика мусора.

Отбросив советы переписать всё на Си, мы принялись более детально изучать информацию по результатам профилирования и точечно устранять создание ненужных/временных объектов. К нашей радости такой подход сразу начал давать плоды.
Собственно, на эту тему и будет сделан основной упор сегодня.
Какого выигрыша удалось достичь? Я обязательно расскажу про это, но попридержу интригу до конца статьи.
Вызов методов с params-параметром
Методы, в сигнатуре которых объявлен params-параметр, в качестве соответствующего аргумента могут:
- не принимать значений;
- принимать одно или несколько значений.
Например, у нас есть метод с такой сигнатурой:
static void ParamsMethodExample(params String[] stringValue)Посмотрим на его представление в IL коде:
.method private hidebysig static void
ParamsMethodExample(string[] stringValue) cil managed
{
.param [1]
.custom instance void
[mscorlib]System.ParamArrayAttribute::.ctor() = ( 01 00 00 00 )
....
}Как мы видим, это простой метод с одним параметром, отмеченным атрибутом System.ParamArrayAttribute. В качестве типа параметра выступает указанный нами массив строк.
Интересный факт. Напрямую использовать этот атрибут вы не можете — компилятор выдаст ошибку CS0674 и заставит вас использовать ключевое слово params.
Из приведённого IL кода следует очень простой вывод — каждый раз, когда нам понадобится выполнять вызов данного метода, вызывающему коду предварительно будет необходимо создавать массив. Ну, почти.
Чтобы лучше разобраться с тем, что происходит при вызове данного метода с разными аргументами, рассмотрим конкретные примеры.
Первый вызов без аргументов.
ParamsMethodExample()IL код:
call !!0[] [mscorlib]System.Array::Empty<string>()
call void Optimizations.Program::ParamsMethodExample(string[])Как мы помним, метод ожидает на вход массив, следовательно нужно его откуда-то взять. В данном случае в качестве аргумента используется результат вызова статического метода System.Array.Empty<T>. Использование Array.Empty<T> позволяет сэкономить на создании пустых коллекций и, как следствие, снижает нагрузку на GC.
А теперь ложка дёгтя. Более старые версии компилятора могут генерировать другой IL код. Например, такой:
ldc.i4.0
newarr [mscorlib]System.String
call void Optimizations.Program::ParamsMethodExample(string[])В таком случае на каждый вызов метода, когда для params-параметра отсутствует соответствующий аргумент, будет создаваться новый пустой массив.
Время задачи для самопроверки. Отличаются ли два следующих вызова, если да — чем?
ParamsMethodExample(null);
ParamsMethodExample(String.Empty);Если вы уже дали себе ответ на этот вопрос, давайте разбираться.
Начнём с вызова, когда аргумент — явный null:
ParamsMethodExample(null);IL код:
ldnull
call void Optimizations.Program::ParamsMethodExample(string[])В данном случае создания массива не происходит. В качестве аргумента просто передаётся значение null.
Теперь же рассмотрим случай, когда в метод передаётся non-null значение:
ParamsMethodExample(String.Empty);IL код:
ldc.i4.1
newarr [mscorlib]System.String
dup
ldc.i4.0
ldsfld string [mscorlib]System.String::Empty
stelem.ref
call void Optimizations.Program::ParamsMethodExample(string[])Как видно, кода здесь уже побольше, чем в предыдущих примерах. Перед вызовом метода создаётся массив. В этот массив будут записаны все те аргументы метода, которые соответствуют params-параметру. В данном случае в массив будет записано единственное значение — пустая строка.
Обратите внимание, что если аргументов несколько, то также будет создан массив, даже если аргументы — явные значения null.
Таким образом, вызовы методов с params-параметрами могут обойтись вам в копеечку за счёт неявного создания массивов. В некоторых случаях, например при отсутствии соответствующего аргумента и использовании современного компилятора, вызов может быть оптимизирован. Но в целом стоит помнить про временные объекты.
Во время профилирования анализатора я обнаружил несколько мест, где профилировщик выявил создание большого количества массивов, которые быстро попадали под сборку мусора.
В соответствующих методах был код примерно следующего вида:
bool isLoop = node.IsKindEqual(SyntaxKind.ForStatement,
SyntaxKind.ForEachStatement,
SyntaxKind.DoStatement,
SyntaxKind.WhileStatement);Сам метод IsKindEqual выглядел так:
public static bool IsKindEqual(this SyntaxNode node, params SyntaxKind[] kinds)
{
return kinds.Any(kind => node.IsKind(kind));
}Из теории, которую мы разобрали выше, следует, что для вызова метода нам нужно создать массив. Сам массив используется только для того, чтобы разок его обойти, после чего он становится не нужен.
Можно ли здесь избавиться от создания лишних массивов? Элементарно:
bool isLoop = node.IsKind(SyntaxKind.ForStatement)
|| node.IsKind(SyntaxKind.ForEachStatement)
|| node.IsKind(SyntaxKind.DoStatement)
|| node.IsKind(SyntaxKind.WhileStatement);Такая элементарная правка помогла уменьшить количество временно создаваемых массивов и, как следствие, снизить нагрузку на GC.
Примечание. В библиотеках .NET иногда используют ловкий приём. Для некоторых методов с params-параметрами также есть перегрузки, которые вместо params-параметра принимают 1, 2, 3 параметра соответствующего типа. Это позволяет избежать накладных расходов на создание временных массивов с вызывающей стороны.
Enumerable.Any<T>
Неоднократно в результатах профилирования мелькал вызов метода Any. Что с ним не так? Разбираться будем на основе реального кода — уже упоминавшегося метода IsKindEqual. Ранее мы делали больший акцент на params-параметре. Теперь же более детально взглянем на код метода изнутри.
public static bool IsKindEqual(this SyntaxNode node, params SyntaxKind[] kinds)
{
return kinds.Any(kind => node.IsKind(kind));
}Чтобы понять, в чём проблема с Any, нужно заглянуть "под капот" метода. Исходный код возьмём с нашего любимого referencesource.microsoft.com.
public static bool Any<TSource>(this IEnumerable<TSource> source,
Func<TSource, bool> predicate)
{
if (source == null)
throw Error.ArgumentNull("source");
if (predicate == null)
throw Error.ArgumentNull("predicate");
foreach (TSource element in source)
{
if (predicate(element))
return true;
}
return false;
}Исходная коллекция просто перебирается в цикле foreach. И если хотя бы для одного элемента вызов predicate вернул значение true, то результатом работы метода будет true, иначе — false.
Основная проблема здесь в том, что любая входная коллекция интерпретируется именно как IEnumerable<T>, а какие-либо оптимизации под специфичные типы коллекций отсутствуют. Напомню, что в рассматриваемом кейсе мы работаем с массивом.
Знатоки уже догадались, что основная проблема с Any — создание лишнего итератора для обхода коллекции. Если же вы не очень поняли, в чём проблема, не волнуйтесь, сейчас разберёмся.
Отсечём лишние фрагменты метода Any и упростим его, сохраним основной необходимый для нас код: цикл foreach и объявление коллекции, с которой цикл работает.
В итоге рассмотрим такой код:
static void ForeachTest(IEnumerable<String> collection)
{
foreach (var item in collection)
Console.WriteLine(item);
}Соответствующий IL код:
.method private hidebysig static void
ForeachTest(
class
[mscorlib]System.Collections.Generic.IEnumerable`1<string> collection)
cil managed
{
.maxstack 1
.locals init (
[0] class
[mscorlib]System.Collections.Generic.IEnumerator`1<string> V_0)
IL_0000: ldarg.0
IL_0001: callvirt instance class
[mscorlib]System.Collections.Generic.IEnumerator`1<!0> class
[mscorlib]System.Collections.Generic.IEnumerable`1<string>::GetEnumerator()
IL_0006: stloc.0
.try
{
IL_0007: br.s IL_0014
IL_0009: ldloc.0
IL_000a: callvirt instance !0 class
[mscorlib]System.Collections.Generic.IEnumerator`1<string>::get_Current()
IL_000f: call void [mscorlib]System.Console::WriteLine(string)
IL_0014: ldloc.0
IL_0015: callvirt instance bool
[mscorlib]System.Collections.IEnumerator::MoveNext()
IL_001a: brtrue.s IL_0009
IL_001c: leave.s IL_0028
}
finally
{
IL_001e: ldloc.0
IL_001f: brfalse.s IL_0027
IL_0021: ldloc.0
IL_0022: callvirt instance void
[mscorlib]System.IDisposable::Dispose()
IL_0027: endfinally
}
IL_0028: ret
}Как видите, тут много чего происходит. Так как компилятор ничего не знает о том, каким фактическим типом представлена коллекция, он сгенерировал общий код для обхода коллекции через итератор. Получение итератора происходит через вызов метода GetEnumerator (метка IL_0001). Получение итератора для массива (наш частный случай) посредством вызова метода GetEnumerator ведёт к созданию объекта на куче, и всё дальнейшее взаимодействие с коллекцией строится на использовании этого объекта.
Примечание. Компилятор может применить специальную оптимизацию при получении итератора для пустого массива. В таком случае вызов GetEnumerator не приведёт к созданию нового объекта. Но про это, пожалуй, я как-нибудь напишу отдельную заметку. В общем случае рассчитывать на такую оптимизацию явно не стоит.
Теперь немного поменяем код, чтобы компилятор точно знал, что мы работаем с массивом. C# код будет выглядеть так:
static void ForeachTest(String[] collection)
{
foreach (var item in collection)
Console.WriteLine(item);
}Соответствующий ему IL код:
.method private hidebysig static void
ForeachTest(string[] collection) cil managed
{
// Code size 25 (0x19)
.maxstack 2
.locals init ([0] string[] V_0,
[1] int32 V_1)
IL_0000: ldarg.0
IL_0001: stloc.0
IL_0002: ldc.i4.0
IL_0003: stloc.1
IL_0004: br.s IL_0012
IL_0006: ldloc.0
IL_0007: ldloc.1
IL_0008: ldelem.ref
IL_0009: call void [mscorlib]System.Console::WriteLine(string)
IL_000e: ldloc.1
IL_000f: ldc.i4.1
IL_0010: add
IL_0011: stloc.1
IL_0012: ldloc.1
IL_0013: ldloc.0
IL_0014: ldlen
IL_0015: conv.i4
IL_0016: blt.s IL_0006
IL_0018: ret
}В данном случае, когда компилятор точно знает, с какой коллекцией мы работаем, он сгенерировал намного более простой код. В частности, пропала вся работа с итератором — даже объект не создаётся (снижаем нагрузку на GC).
Кстати, вот вам вопрос для самопроверки. Если восстановить из этого IL кода C# код, какую конструкцию языка получим в итоге? Как можно видеть, этот код сильно отличается от того, что был сгенерирован для цикла foreach ранее.
Внимание, ответ.
Для представленного ниже метода на C# будет сгенерирован такой же IL код, как тот, что мы рассматривали выше (за исключением имён):
static void ForeachTest2(String[] collection)
{
String[] localArr;
int i;
localArr = collection;
for (i = 0; i < localArr.Length; ++i)
Console.WriteLine(localArr[i]);
}Таким образом, когда компилятор знает, что мы работаем с массивом, он генерирует более оптимальный код, раскрывая цикл foreach как for.
К сожалению, при использовании Any в нашем случае мы лишаемся подобной оптимизации, а также создаём лишний объект итератора для обхода последовательности.
Лямбда-выражения
Лямбды — очень удобная вещь, которая сильно облегчает жизнь. Конечно, пока не находится кто-нибудь, кто решает запихать лямбду внутрь лямбды, внутри лямбды… Любители так делать, одумайтесь, серьёзно.
В общем и целом использование лямбда-выражений сильно упрощает жизнь. Но не стоит забывать, что под капотом лямбды раскрываются в целые классы. Как следствие, экземпляры этих самых классов ещё необходимо создать.
Давайте вновь обратимся к методу IsKindEqual.
public static bool IsKindEqual(this SyntaxNode node, params SyntaxKind[] kinds)
{
return kinds.Any(kind => node.IsKind(kind));
}А теперь взглянем на соответствующий IL код:
.method public hidebysig static bool
IsKindEqual(
class
[Microsoft.CodeAnalysis]Microsoft.CodeAnalysis.SyntaxNode
node,
valuetype
[Microsoft.CodeAnalysis.CSharp]Microsoft.CodeAnalysis.CSharp.SyntaxKind[]
kinds)
cil managed
{
.custom instance void
[mscorlib]System.Runtime.CompilerServices.ExtensionAttribute::
.ctor() = ( 01 00 00 00 )
.param [2]
.custom instance void
[mscorlib]System.ParamArrayAttribute::
.ctor() = ( 01 00 00 00 )
// Code size 32 (0x20)
.maxstack 3
.locals init
(class OptimizationsAnalyzer.SyntaxNodeUtils/'<>c__DisplayClass0_0' V_0)
IL_0000: newobj instance void
OptimizationsAnalyzer.SyntaxNodeUtils/'<>c__DisplayClass0_0'::.ctor()
IL_0005: stloc.0
IL_0006: ldloc.0
IL_0007: ldarg.0
IL_0008: stfld
class [Microsoft.CodeAnalysis]Microsoft.CodeAnalysis.SyntaxNode
OptimizationsAnalyzer.SyntaxNodeUtils/'<>c__DisplayClass0_0'::node
IL_000d: ldarg.1
IL_000e: ldloc.0
IL_000f: ldftn instance bool
OptimizationsAnalyzer.SyntaxNodeUtils/'<>c__DisplayClass0_0'
::'<IsKindEqual>b__0'(
valuetype [Microsoft.CodeAnalysis.CSharp]Microsoft.CodeAnalysis
.CSharp.SyntaxKind)
IL_0015: newobj instance void
class [mscorlib]System.Func`2<
valuetype [Microsoft.CodeAnalysis.CSharp]
Microsoft.CodeAnalysis.CSharp.SyntaxKind,bool>::.ctor(
object, native int)
IL_001a: call bool
[System.Core]System.Linq.Enumerable::Any<
valuetype [Microsoft.CodeAnalysis.CSharp]Microsoft.CodeAnalysis
.CSharp.SyntaxKind>(
class [mscorlib]System.Collections.Generic.IEnumerable`1<!!0>,
class [mscorlib]System.Func`2<!!0,bool>)
IL_001f: ret
}Согласитесь, кода тут немного больше, чем в C#. Моментов, которые хотелось бы сейчас отметить, здесь два — инструкции создания объектов на метках IL_0000 и IL_0015. В первом случае как раз создаётся объект автоматически сгенерированного компилятором типа (то, что лежит "под капотом" лямбда-выражения). Второй вызов newobj — создание экземпляра делегата, который выполняет проверку IsKind.
Стоит отметить, что в некоторых случаях компилятор может применять оптимизации и не добавлять инструкцию newobj для создания экземпляра сгенерированного типа. Вместо этого он может, например, единожды создать объект, записать его в статическое поле и дальше работать с этим полем. Такое поведение наблюдается, например, когда в лямбда-выражении отсутствуют захваченные переменные.
Переписанный вариант IsKindEqual
Как мы с вами увидели, на каждый вызов IsKindEqual за кулисами будет создаваться несколько временных объектов. И, как показала практика (и профилирование), в некоторых случаях это может играть ощутимую роль с точки зрения нагрузки на GC.
Один из вариантов — отказаться от использования метода вовсе. Как мы видели, вызывающей стороне можно просто несколько раз вызывать метод IsKind. Другой вариант — переписать код.
Версия 'до' выглядит так:
public static bool IsKindEqual(this SyntaxNode node, params SyntaxKind[] kinds)
{
return kinds.Any(kind => node.IsKind(kind));
}Так выглядит одна из возможных версий 'после':
public static bool IsKindEqual(this SyntaxNode node, params SyntaxKind[] kinds)
{
for (int i = 0; i < kinds.Length; ++i)
{
if (node.IsKind(kinds[i]))
return true;
}
return false;
}Примечание. При желании код можно было бы переписать с использованием foreach. Как мы отмечали ранее, когда компилятор знает, что мы точно работаем с массивом, под капотом он всё равно сгенерирует IL код цикла for.
В итоге получилось немного больше кода, зато мы избавились от всех созданий временных объектов, которые рассмотрели ранее. В этом можно убедиться, посмотрев IL код — все инструкции newobj из него пропали.
.method public hidebysig static bool
IsKindEqual(class Optimizations.SyntaxNode node,
valuetype Optimizations.SyntaxKind[] kinds) cil managed
{
.custom instance void
[mscorlib]System.Runtime.CompilerServices.ExtensionAttribute::
.ctor() = ( 01 00 00 00 )
.param [2]
.custom instance void
[mscorlib]System.ParamArrayAttribute::
.ctor() = ( 01 00 00 00 )
// Code size 29 (0x1d)
.maxstack 3
.locals init ([0] int32 i)
IL_0000: ldc.i4.0
IL_0001: stloc.0
IL_0002: br.s IL_0015
IL_0004: ldarg.0
IL_0005: ldarg.1
IL_0006: ldloc.0
IL_0007: ldelem.i4
IL_0008: callvirt instance bool
Optimizations.SyntaxNode::IsKind(valuetype Optimizations.SyntaxKind)
IL_000d: brfalse.s IL_0011
IL_000f: ldc.i4.1
IL_0010: ret
IL_0011: ldloc.0
IL_0012: ldc.i4.1
IL_0013: add
IL_0014: stloc.0
IL_0015: ldloc.0
IL_0016: ldarg.1
IL_0017: ldlen
IL_0018: conv.i4
IL_0019: blt.s IL_0004
IL_001b: ldc.i4.0
IL_001c: ret
}Переопределение базовых методов в значимых типах
Пример кода для затравки:
enum Origin
{ }
void Foo()
{
Origin origin = default;
while (true)
{
var hashCode = origin.GetHashCode();
}
}Как думаете, даёт ли приведённый код нагрузку на GC? Ладно-ладно, с учётом того, что код находится в этой статье, ответ очевиден.
Поверили? На деле не всё так просто. Чтобы ответить на вопрос, нужно знать, например, работает ли приложение под .NET Framework или .NET. Кстати, а откуда вообще здесь может взяться нагрузка на GC? Вроде бы никаких объектов на управляемой куче не создаётся.
Чтобы разобраться в теме пришлось и в IL код заглянуть, и спецификацию почитать. Более подробно вопрос я раскрыл в отдельной статье.
Если в двух словах, вот вам спойлеры:
- здесь может происходить упаковка для вызова метода GetHashCode;
- чтобы избежать упаковки переопределяйте в своих значимых типах базовые методы.
Задание начальной ёмкости коллекций
Я слышал примерно следующее мнение: "Да зачем нужно задавать начальную ёмкость коллекции, под капотом всё и так оптимизировано". Конечно, что-то оптимизировано (мы ещё посмотрим, что именно). Но если говорить о тех местах приложения, где создание чуть ли не каждого объекта может влететь в копеечку, то не стоит пренебрегать возможностью сразу подсказать приложению, коллекция какого размера нам понадобится.
О том, зачем полезно задавать начальную ёмкость, поговорим на примере типа List<T>. Допустим, есть код следующего вида:
static List<Variable> CloneExample(IReadOnlyCollection<Variable> variables)
{
var list = new List<Variable>();
foreach (var variable in variables)
{
list.Add(variable.Clone());
}
return list;
}Очевидно ли, в чём проблема такого кода? Если да, жму руку. Если нет, ничего страшного, сейчас разберёмся.
Итак, мы создаём пустой список и постепенно его заполняем. Соответственно, каждый раз, когда ёмкость списка заканчивается, нам нужно:
- выделить память под новый массив, в который и будут складываться элементы списка;
- скопировать элементы старого массива в новый.
Откуда массив? Он лежит в основе типа List<T>, в чём можно убедиться всё на том же referencesource.microsoft.com.
Очевидно, что чем больше размер коллекции variables, тем большее количество таких операций будет выполнено.
Алгоритм роста списка в нашем случае (для версии .NET Framework 4.8) будет следующим: 0, 4, 8, 16, 32… То есть, если в коллекции variables 257 элементов, это потребует создания 8 массивов и 7 операций копирования.
Всех этих лишних накладных расходов можно избежать, если сразу задать начальную ёмкость списка:
var list = new List<Variable>(variables.Count);Пренебрегать такой возможностью явно не стоит.
LINQ: разное
Enumerable.Count<T>
Метод Enumerable.Count в зависимости от перегрузки может:
- вычислить количество элементов в коллекции;
- вычислить количество элементов в коллекции, удовлетворяющих предикату.
Более того, внутри метода реализовано несколько оптимизаций, но… есть нюанс.
Давайте для начала заглянем внутрь метода. Исходники, как обычно, возьмём с referencesource.microsoft.com.
Так выглядит версия, не принимающая предикат:
public static int Count<TSource>(this IEnumerable<TSource> source)
{
if (source == null)
throw Error.ArgumentNull("source");
ICollection<TSource> collectionoft = source as ICollection<TSource>;
if (collectionoft != null)
return collectionoft.Count;
ICollection collection = source as ICollection;
if (collection != null)
return collection.Count;
int count = 0;
using (IEnumerator<TSource> e = source.GetEnumerator())
{
checked
{
while (e.MoveNext())
count++;
}
}
return count;
}А так — версия с предикатом:
public static int Count<TSource>(this IEnumerable<TSource> source,
Func<TSource, bool> predicate)
{
if (source == null)
throw Error.ArgumentNull("source");
if (predicate == null)
throw Error.ArgumentNull("predicate");
int count = 0;
foreach (TSource element in source)
{
checked
{
if (predicate(element))
count++;
}
}
return count;
}Хорошие новости: в версии метода без предиката есть оптимизация, которая позволяет более эффективно вычислять количество элементов для коллекций, реализующих ICollection или ICollection<T>.
Однако, если это не так, для получения количества элементов будет ожидаемо пройдена вся коллекция. Особенно это интересно в рамках метода с предикатом.
Допустим, есть следующий код:
collection.Count(predicate) > 12;И при этом в collection — 100 000 элементов. Понимаете, да? Для того чтобы проверить это условие, нам достаточно было бы найти 13 элементов, для которых predicate(element) вернул бы true. Однако вместо этого predicate будет применён ко всем 100 000 элементам в коллекции. Особенно становится обидно, если predicate выполняет какие-то относительно тяжёлые операции.
Выход есть — велосипед! В смысле, написать свой аналог/аналоги Count. Какой делать сигнатуру методов (и делать ли их вообще) — решать вам. Можно сделать просто несколько разных методов, можно сделать метод с хитрой сигнатурой, через которую определялось бы, какое сравнение нам необходимо ('>', '<', '==' и т. д.). Если вдруг вы выявили узкие места, связанные с Count, но таких мест всего парочка — можно просто переписать их на использование цикла foreach, например.
Any -> Count / Length
Выше мы уже разобрали, что вызов метода Any может обходиться нам в один лишний итератор. Создания лишнего объекта можно избежать, если использовать свойства конкретных коллекций, например List<T>.Count или Array.Length.
Например:
static void AnyTest(List<String> values)
{
while (true)
{
// GC
if (values.Any())
// Do smth
// No GC
if (values.Count != 0)
// Do smth
}
}Такой код менее гибок, может быть, чуть хуже читается, но при этом может позволить сэкономить на создании итераторе. Да, именно может. Это зависит от того, будет ли возвращаться новый объект методом GetEnumerator. При более тонком изучении вопроса обнаружились интересные моменты, которые я, возможно, опишу в отдельной заметке.
LINQ -> циклы
Как показала практика, в местах, где каждый создаваемый временный объект может ухудшить производительность, есть смысл отказаться от LINQ в пользу простых циклов. Про это мы говорили выше на примере Any и Count, та же история и с другими методами.
Просто для примера:
var strings = collection.OfType<String>()
.Where(str => str.Length > 62);
foreach (var item in strings)
{
Console.WriteLine(item);
}Этот код можно переписать, например, так:
foreach (var item in collection)
{
if (item is String str && str.Length > 62)
{
Console.WriteLine(str);
}
}Хотя это очень простой случай, где разница не особо видна, бывают и такие, когда LINQ запросы читаются намного легче, чем аналогичный код на циклах. Так что ещё раз напоминаю, что просто так везде отказываться от LINQ — идея сомнительная.
Примечание. Если вы забыли, из-за чего при использовании LINQ в управляемой куче могут появляться объекты, рекомендую обратиться к этому видео или этой статье.
Буферизация LINQ запросов
Не забывайте, что LINQ запросы с отложенным вычислением исполняются каждый раз заново, когда вы запускаете обход последовательности.
Пример, наглядно демонстрирующий это:
static void LINQTest()
{
var arr = new int[] { 1, 2, 3, 4, 5 };
var query = arr.Where(AlwaysTrue);
foreach (var item in query) // 5
{ /* Do nothing */}
foreach (var item in query) // 5
{ /* Do nothing */}
foreach (var item in query) // 5
{ /* Do nothing */}
bool AlwaysTrue(int val) => true;
}В данном случае метод AlwaysTrue будет исполнен 15 раз. При этом, если бы мы провели буферизацию запроса (добавили вызов метода ToList к цепочке LINQ вызовов), метод AlwaysTrue был бы вызван всего 5 раз.
Изменение режима сборки мусора
Выше я упоминал, что ранее мы уже делали ряд оптимизаций в C# анализаторе PVS-Studio и даже написали про это статью. После того как она была опубликована на habr.com, в комментариях началось активное обсуждение. Одним из предложений было попробовать поменять настройки сборщика мусора.
Не сказать, что мы про них не знали. Более того, когда я занимался оптимизациями и почитывал книгу "Оптимизация приложений на платформе .NET", то также читал про настройки GC. Однако как-то не зацепился за то, что изменение режима сборки мусора может принести какую-то пользу. Косяк.
В итоге, пока я был в отпуске, коллеги сделали очень грамотную вещь: ухватились за совет из комментариев и решили попробовать поэкспериментировать с изменением режима работы GC. Результат был впечатляющим — время анализа с помощью PVS-Studio C# крупных проектов (например, Roslyn) значительно сократилось. При этом на некрупных проектах увеличилось потребление памяти, но в допустимых пределах.
Например, на той машине, где проводился эксперимент, время анализа исходного кода того же Roslyn сократилось на 47 процентов! Если раньше анализ проекта проходил за 1 час 17 минут, то после изменения режима сборки мусора анализ Roslyn стал проходить за 41 минуту.

Преодолеть психологическую отметку анализа Roslyn в 1 час было очень уж приятно.
Мы были так довольны результатами, что включили новый (серверный) режим сборки мусора в C# анализаторе. С версии PVS-Studio 7.14 этот режим будет включён по умолчанию.
Более подробно разные режимы сборки мусора Сергей Тепляков описывал в этой статье.
P.S. Кстати, Сергей — автор замечательной книги "Паттерны проектирования на платформе .NET". Если вдруг не читали, настоятельно рекомендую.
Результаты оптимизации C# анализатора PVS-Studio
Кроме разобранных выше оптимизаций, мы сделали и ряд других.
Например:
- устранения бутылочных горлышек в некоторых диагностиках (одна так и вовсе была полностью переписана);
- оптимизации объектов, используемых в data-flow анализе: облегчение копирования, доп. кэширование, устранение временных объектов в управляемой куче;
- оптимизация сравнения узлов дерева;
- и т.п.
Разобранные оптимизации начали добавляться в PVS-Studio с релиза 7.12 и добавлялись постепенно. При этом не стоит забывать, что за это время анализатор пополнился новыми диагностиками, поддержкой .NET 5 проектов, а также taint-анализом.
Ради интереса я замерил время анализа open source проектов из наших тестов с помощью 2 версий PVS-Studio: 7.11 и 7.14. Для статистики взял наиболее долго анализируемые проекты.
На графике, представленном ниже, можно увидеть время анализа (в минутах):
- проекта Juliet Test Suite;
- проекта Roslyn;
- суммарное время анализа всех проектов из тестов.
Сам график:

Как видно, прирост производительности оказался весьма значительным. Так что, если вдруг вы пробовали C# анализатор PVS-Studio и остались недовольны скоростью его работы, предлагаю попробовать ещё раз. Кстати, по указанной ссылке можно получить расширенную триальную лицензию — не на 7, а на 30 дней. ;)
Если же и сейчас столкнётесь с какими-то проблемами, обязательно пишите в поддержку, будем разбираться.
Заключение
Преждевременная оптимизация — зло. Да здравствует оптимизация по результатам профилирования! И помните, что даже совсем небольшие изменения многократно исполняемого кода могут значительно сказаться на производительности приложения, если они делаются в правильных местах.
Как всегда, приглашаю подписываться на мой Twitter, чтобы не пропустить ничего интересного.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Vasiliev. Optimization of .NET applications: a big result of small edits.
Автор: Sergey Vasiliev






{kind=link}