
Предисловие
В данной статье будут разобраны основные регламентные работы с базой данных информационной системы 24x7 (т е у которой нет простоя) и подходы к их выполнению в MS SQL Server. Также прошу заметить, что эта статья будет кратким обзором, т е не все работы будут достаточно детализированы. Однако, данной информации достаточно, чтобы при необходимости изучить более детально ту или иную регламентную работу.
Буду очень признателен, если в комментариях появятся поправки и дополнения к этой статье.
Регламентные работы
Выделяют следующие основные регламентные работы с базой данных:
1) Плановое создание резервных копий с последующей проверкой без восстановления
2) Плановое восстановление ранее созданных резервных копий с целью полной проверки их работоспособности
3) Анализ носителей информации, на которых расположены системные и все необходимые базы данных
4) Плановая проверка работы необходимых служб
5) Плановая оптимизация производительности системы
6) Плановая проверка целостности данных
7) Плановая проверка корректности данных
Первые три пункта самые критичные, так как обеспечивают восстановление системы после различных сбоев. Однако, и последние три пункта необходимо планово выполнять, чтобы и пользователям было комфортно работать (все запросы выполнялись быстро или за приемлемое время), и данные были корректными в различных отчетных системах.
Для автоматизации регламентных работ можно части этих работ оформить в задачи Агента или Планировщика Windows.
П.6 основан на команде CHECKDB.
П.7 реализуется относительно предметной области, которая применяется в информационной системе.
Пункты 6 и 7 подробно разбирать не будем.
Теперь разберем первые пять пунктов подробнее.
Плановое создание резервных копий с последующей проверкой без восстановления
На эту тему писалось достаточно статей (см. источники), поэтому отметим лишь то, что эту регламентную работу нужно делать постоянно желательно на резервном, а не на основном сервере. На таком резервном сервере должны быть актуальные данные (например, с помощью репликаций). Также необходимо делать резервные копии всех системных баз данных (кроме tempdb) на каждом экземпляре сервера MS SQL Server.
При неудачном создании резервной копии (или проверка резервной копии выявила проблему), данную информацию необходимо сообщить администраторам. Например, на почту (Настройка почтовых уведомлений в MS SQL Server).
Важно определить стратегию резервирования, которая отвечала бы в том числе и на следующие вопросы:
1) как часто и когда делать резервную копию (полную, разностную, журнала транзакций)
2) как долго и когда удалять резервные копии.
Плановое восстановление ранее созданных резервных копий с целью полной проверки их работоспособности
Данную процедуру лучше также выполнять на резервном сервере с помощью сторонних утилит или команды RESTORE.
При неудачном восстановлении резервной копии, данную информацию необходимо сообщить администраторам. Например, на почту (Настройка почтовых уведомлений в MS SQL Server).
Также в качестве проверки необходимо восстанавливать и резервные копии системных баз данных. Для этого достаточно их восстановить как обычную пользовательскую базу данных с именем, отличной от имен системных баз данных.
Анализ носителей информации, на которых расположены системные и все необходимые базы данных
Здесь необходимо анализировать сколько места занимает каждая база данных, как изменяются размеры файлов, а также как изменяются размеры свободного места всего носителя целиком (например, часть этого задания можно сделать с помощью Автосбор данных о файлах баз данных и логических дисках операционной системы в MS SQL Server).
Такую проверку можно делать каждый день и отправлять результаты. Например, на почту (Настройка почтовых уведомлений в MS SQL Server).
Необходимо также следить и за системными базами данных. Если этого не делать, то может произойти, например, это.
Также важно протестировать и сами носители на предмет износа или ошибочных секторов. Важно, что в момент такого тестирования, носитель необходимо вывести из работы, а данные переместить на другой носитель, т к проверка подобного рода сильно нагружает носитель.
Данная задача является уже чисто задачей системного администратора, и поэтому ее подробно рассматривать не будем. Для полного контроля лучше договориться с системным администратором об автоматической отправке отчета о результатах тестов на почту.
Данную проверку лучше выполнять раз в год.
Плановая проверка работы необходимых служб
Вообще говоря, службы никогда не должны падать. Для этого и предназначен резервный сервер, который в случае сбоя основного сервера, станет основным. Но просматривать логи необходимо периодически. Также можно продумать автоматический сбор информации с последующим уведомлением администраторов. Например, отправив результаты на почту (Настройка почтовых уведомлений в MS SQL Server).
Необходимо проверять и сами задания Агента (или Планировщика заданий Windows). Например, автоматизировать проверку заданий Агента можно с помощью автосбора данных о выполненных заданиях в MS SQL Server.
Плановая оптимизация производительности системы
Сюда входят следующие компоненты:
1) Автоматизация дефрагментации индексов в базе данных MS SQL Server
2) Автосбор данных об изменениях схем баз данных в MS SQL Server (чтобы можно было восстановить нужную резервную копию и сравнить изменения, например, с помощью dbForge)
3) Автоматическое удаление зависших процессов в MS SQL Server
4) Чистка процедурного кэша (здесь важно определить когда и что именно чистить)
5) Реализация индикатора производительности
6) Разработка и изменение индексов (Повесть о кластеризованном индексе)
Не будем подробно описывать каждый пункт, а остановимся на пунктах 5-6.
В пункте 5 необходимо создать систему, которая бы показывала быстродействие работы базы данных. Также это можно сделать и так.
Также в большинстве случаев советую в параметрах базы данных отключить параметр AUTO_CLOSE.
Еще немного поговорим об оптимизации самих запросов.
Иногда по разным причинам (а порой и не понятным) оптимизатор решает распараллелить запрос. И не всегда он это делает оптимально.
Есть общая рекомендация:
1) Если данных много будет в итоге обработки (выборка, изменение), то параллелизм оставить
2) Если данных немного будет в итоге обработки (выборка, изменение), то параллелизм в большинстве случаев не оптимально строит план.
За параллелизм отвечают два параметра в настройках экземпляра сервера MS SQL Server:
1) Максимальная степень параллелизма (max degree of parallelism) (чтобы выключить параллелизм, выставите значение в «1», т е будет всегда только один процессор задействован в выполнении плана запроса)
2) Стоимостный порог для параллелизма (cost threshold for parallelism) (в большинстве случаев его лучше оставить по умолчанию)
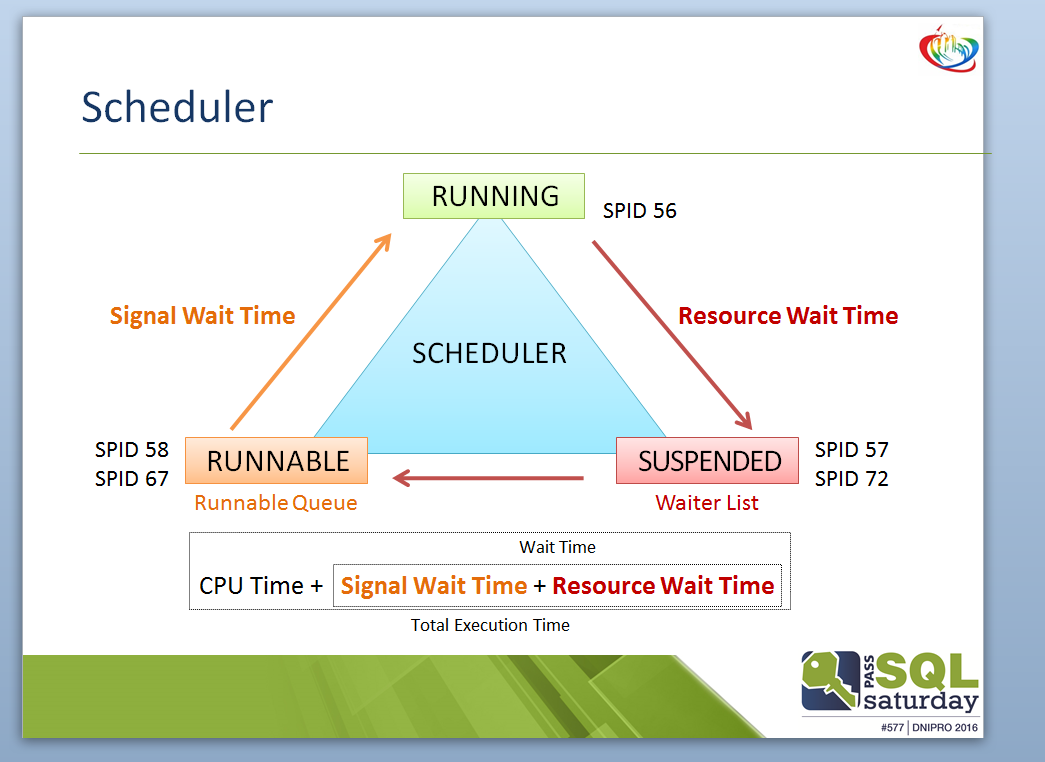
Выделяют две основные очереди:
1) На ожидание процессорного времени (очередь QCPU) – это когда процесс запроса уже был запущен и ожидает процессор на выполнение (например, другой процесс вытеснил процесс запроса)
2) На ожидание ресурсов (очередь QR) – это когда процесс ждет освобождение ресурсов для своего выполнения или продолжения выполнения (диски, оперативная память и др.)
Все время выполнения запроса T определяется следующей формулой:
T=TP+TQR+TCPU+TQCPU, где:
1) TP – время компиляции плана
2) TQR – время ожидания на ресурсы (время пребывания процесса в очереди QR)
3) TQCPU – время ожидания на освобождение необходимых процессоров (время пребывания процесса в очереди QCPU)
4) TCPU – время выполнения запроса (суммируется все время по всем процессорам)
В системных представлениях sys.dm_exec_query_stats и аналогичных:
1) total_worket_time = TP+TCPU+TQCPU
2) total_elapsed_time = TQR+TCPU
Из этого следует, что по встроенным средствам невозможно точно сказать сколько же на самом деле выполнялся запрос. Но в большинстве случаев с помощью total_elapsed_time можно получить время, которое близко к времени выполнения самого запроса. Более точно определить время выполнения запроса можно либо с помощью трассировки, либо с помощью самой информационной системы, если начало и конец вызова запроса как-то логируется в таблицу логов в базу данных. Но любая трассировка нагружает систему, поэтому ее лучше проводить также на резервном сервере, а собирать данные из основного сервера. Тогда нагрузка будет только на сеть.
Во время распараллеливания запросу выделяется n процессов (в выпуске Standart n<=4). И каждый процесс такой потребует процессорное время для выполнения (не всегда 1 процесс будет выполняться на каждом ядре). Чем больше процессов, тем больше вероятность того, что один или несколько процессов будут вытесняться другими процессами, что в свою очередь приведет к увеличению TQCPU.
Запрос может выполняться медленнее при распараллеливании в следующих случаях:
1) если у системы очень слабая пропускная способность дисковых подсистем, тогда при анализе запроса, его декомпозиция может выполняться дольше, чем без параллелизма.
2) возможен перекос данных или блокировки диапазонов данных для процесса, порождённые другим, используемым параллельно и запущенным позже процессом, и т.д.
3) если отсутствует индекс для предиката, что приводит к сканированию таблицы. Параллельная операция в рамках запроса может скрыть тот факт, что запрос выполнился бы намного быстрее с последовательным планом исполнения и с правильным индексом.
Рекомендации:
Запретить распараллеливание запросов на серверах, где нет большой выборки (показатель total_worket_time должен уменьшиться из-за возможного уменьшения TCPU и TQCPU особенно последнего, т к первый может примерно не измениться в виду того, что все процессы превратятся в один линейный процесс). Для этого необходимо параметр Максимальная степень параллелизма (max degree of parallelism) выставить в 1, чтобы всегда только один процессор был задействован в выполнении плана запроса.
Также можно использовать и другие готовые решения для построения системы, которая определяет быстродействие базы данных. Важно четко понимать как эти решения работают и правильно интерпретировать полученные числа.
По п.6 тоже достаточно много исчерпывающей информации в Интернете. Главное-понимать как логически устроен индекс и как он работает.
Напомню лишь о том, что первичный ключ и кластерный индекс-это не одно и тоже:
Первичный ключ-это поле или набор полей, которые делают уникальным запись в таблице (для него можно построить либо уникальный кластерный индекс, либо уникальный некластерный индекс). Его используют в других таблицах как внешний ключ для обеспечения целостности данных.
Кластерный индекс-это по сути B-дерево (или его модификация), в листьях которых содержатся сами данные (строки), а в узлах-то, что было определено в качестве кластерного индекса (поле или группа полей). Данное определение дано грубо относительно того, что содержится в листьях и в узлах B-дерева, но такое определение необходимо для понимания процесса поиска и вставки в это дерево. При этом кластерный индекс может быть и неуникальным, но лучше стараться делать его уникальным.
Напомню, что B-дерево-это структура, которая хранит данные в отсортированном виде по кластерному индексу. Поэтому также важно, чтобы поля, выбранные в качестве кластерного индекса, по порядку либо возрастали, либо уменьшались. Т. е. для кластерного индекса отлично подойдут поля типа целого числа (identity), а также дата и время (т к данные будут записываться всегда в конец дерева), но плохо подойдут поля типа uniqueidentifier, т к последние будут приводить к постоянным перестройкам B-дерева, что в свою очередь увеличит количество чтений и записей на носитель информации, где расположена база данных.
К сожалению, данный факт порой забывают даже ведущие разработчики программного обеспечения, т к в свободных ресурсах об этом явно не освещают, но зато разбирают сами индексы и как они устроены. И из этого делается уже вывод о том, что можно делать кластерным индексом, а что лучше не делать.
Также необходимо убедиться, что индекс используется с помощью системного представления sys.dm_db_index_usage_stats
P.S.: Также необходимо постоянно проверять, что на резервном сервере данные актуальны, а также саму систему, которая эти данные синхронизирует (например, репликации).
Источники:
» CHECKDB
» Настройка почтовых уведомлений в MS SQL Server
» RESTORE
» Автосбор данных о файлах баз данных и логических дисках операционной системы в MS SQL Server
» Тестирование производительности баз данных при помощи tSQLt и SQLQueryStress
» AUTO_CLOSE
» История про msdb размером в 42 Гб
» TOP (10) бесплатных плагинов для SSMS
» План обслуживания «на каждый день» – Часть 1: Автоматическая дефрагментация индексов
» План обслуживания «на каждый день» – Часть 2: Автоматическое обновление статистики
» План обслуживания «на каждый день» – Часть 3: Автоматическое создание бекапов
» Автосбор данных о выполненных заданиях в MS SQL Server
» Автоматизация дефрагментации индексов в базе данных MS SQL Server
» Автосбор данных об изменениях схем баз данных в MS SQL Server
» Полезные возможности dbForge для администрирования баз данных MS SQL Server)
» Автоматическое удаление зависших процессов в MS SQL Server
» Чистка процедурного кэша
» Реализация индикатора производительности запросов, хранимых процедур и триггеров в MS SQL Server. Автотрассировка
» Степени параллелизма и степени неопределенности в Microsoft SQL Server
» Презентация ожидания
» Схема выполнения запроса
» Степень параллелизма
» Исследуем базы данных с помощью T-SQL
» Повесть о кластеризованном индексе
» sys.dm_db_index_usage_stats
Автор: jobgemws






{kind=link}